@geyee 奇怪,连接和部分内容被吞了,参考自 Applications experience forcibly closed TLS connection errors when connecting SQL Servers in Windows。官方的文章个人理解是客户端和服务端是否包含前导0补丁更新导致的使用 TLS_DHE 时计算值不同,而连接被关闭。解决方法是要么安装补丁或升级系统,要么禁用 TLS_DHE 。
- win11 电脑数据库连接 SQLSERVER 提示 SSL PROVIDER ERROR:0
- win11 电脑数据库连接 SQLSERVER 提示 SSL PROVIDER ERROR:0
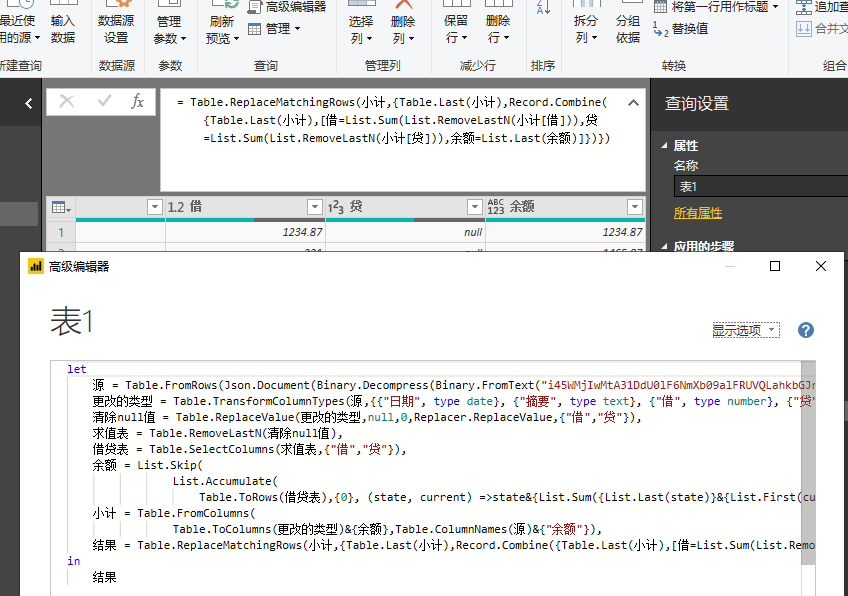
- 自动删除字段 全部是 null 或 0 的列
- 工作需要,想用 power query 作一个 现金日记账,但始终实现不了,请大神帮忙
- 文本提取: [爬 (无)](http://xxx/) 怎样提取出 [] 内容和 () 内容
- 文本提取: [爬 (无)](http://xxx/) 怎样提取出 [] 内容和 () 内容
- 网抓深化提取 Excel 文件数据问题
- OLE DB 或 ODBC 错误
- 如何采集同一网页地址,通过点击按钮的其他数据
- 为什么抓取内网系统数据,在 header 里已经添加了 cookie 信息,提交 URL 的时候仍然转到了登录页面
- 如何采集同一网页地址,通过点击按钮的其他数据
- PQ 中索引列与随机数的关系
- PQ 中索引列与随机数的关系
- PQ 中索引列与随机数的关系
- power bi 本地部署后,通过 Web 门户 URL 查看报表 报错:无法连接到 Analysis Services 服务器。请确保已正确输入连接字符串。
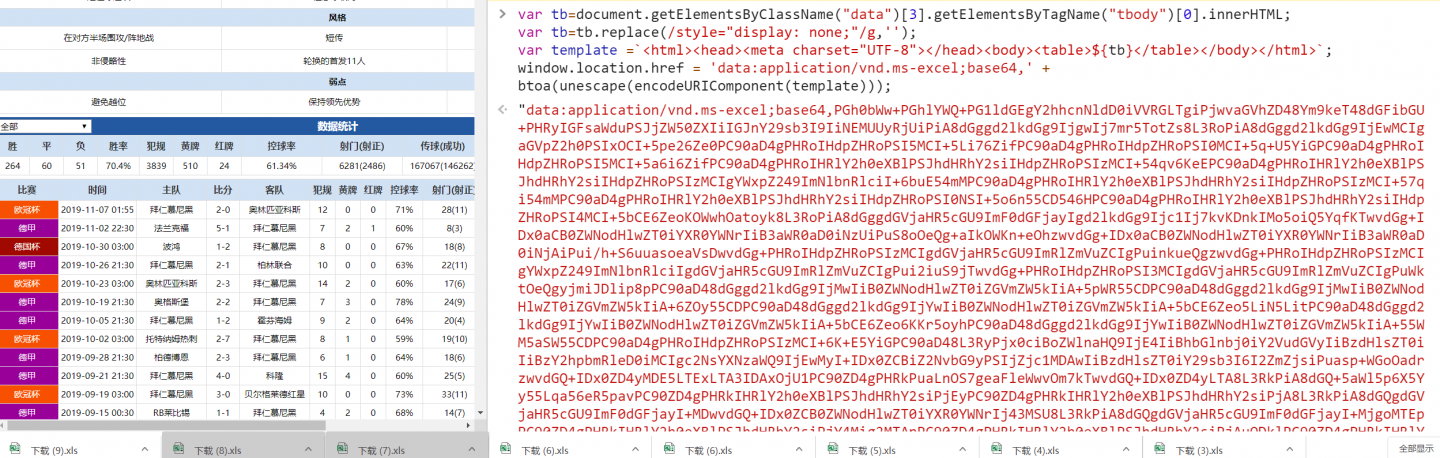 ,可先搜索下"浏览器 终端 javascript 调试 "关键词学习下。
,可先搜索下"浏览器 终端 javascript 调试 "关键词学习下。