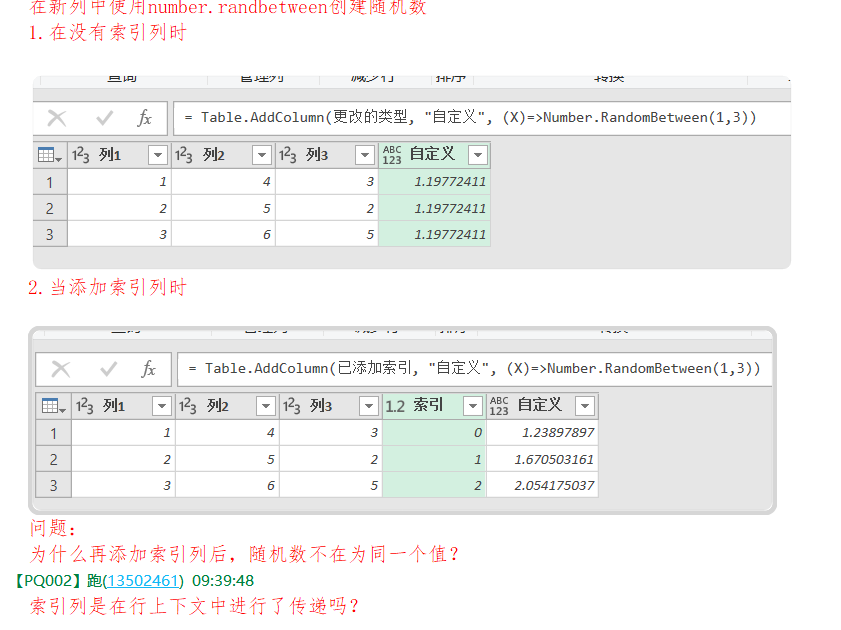
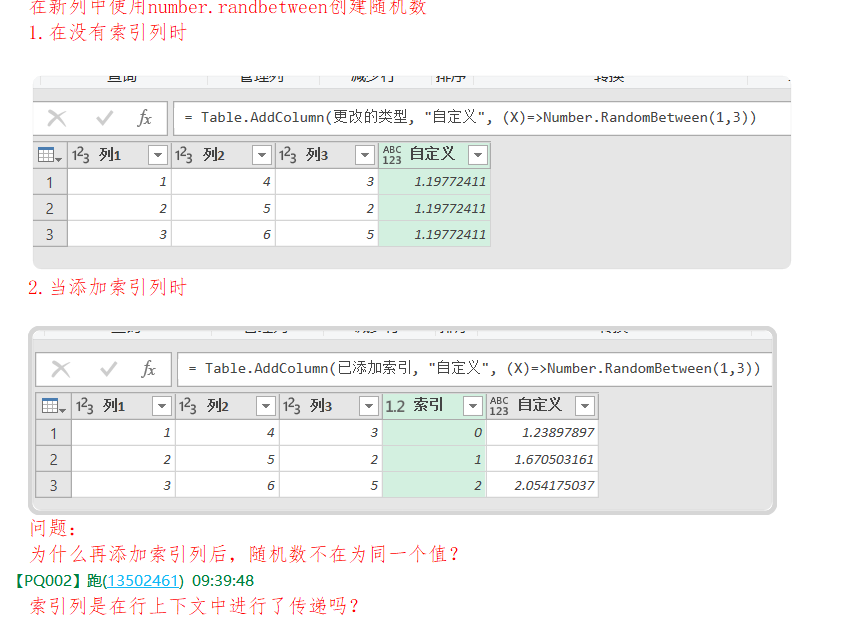

How to get a random sample of data with Power Query提到PowerQuery是一种parallel language,通过添加index索引可强制所有行运行随机函数。包含随机值的结果加载到工作表后,可能变成同一值,可通过Table.Buffer解决。添加索引、添加随机数及Table.Buffer,这三个步骤需要依次紧挨着。更多理解可能需要了解Microsoft.Mashup.Evaluator、Microsoft Mashup Evaluation Container了。猜测,添加索引后,后继的步骤中的随机数函数的种子(seed)就改变了。行上下文是dax中的概念,应该不牵扯PowerQuery吧?
How to get a random sample of data with Power Query提到PowerQuery是一种parallel language,通过添加index索引可强制所有行运行随机函数。包含随机值的结果加载到工作表后,可能变成同一值,可通过Table.Buffer解决。添加索引、添加随机数及Table.Buffer,这三个步骤需要依次紧挨着。更多理解可能需要了解Microsoft.Mashup.Evaluator、Microsoft Mashup Evaluation Container了。猜测,添加索引后,后继的步骤中的随机数函数的种子(seed)就改变了。行上下文是dax中的概念,应该不牵扯PowerQuery吧?
@跑 添加随机数的前一个步骤(随机函数作用于的项),比如源,如果源本身被Table.Buffer过,或者表结构发生变化(相对于上一步后者内层计算单元),则Power Query编辑器看到随机数这一步骤的各行随机数各不相同。虽然不用提及dax的上下文,环境上下文倒是应当提及,也就是考虑相应步骤内函数作用的对象的构成。使用Table.Repeat可观察到先相同再不同的随机数。归根结缔,当然与PowerQuery的数据结构与算法实现有关。随机数的相同与否,感觉也与Power Query的惰性计算Lazy Evaluation特点有关,是一个feature,是计算资源利用优化的结果。
如果数据源经过数据类型转换,或是添加或删除列操作(非索引列),或是修改列名的操作等,那么生成的随机数便是相同的了。数据在内存中的状态是亦失的(不稳定的),则给到的资源便宜惰性(并行)计算(而有 same value in all cells in a Column),反之,则需要更多的计算资源来运算,个人这样理解,不清楚对不对。
值得注意的是Random Number being changed to the same number for all rows这个问答,提到一般而言函数是幂等的( idempotent ),optimization pipeline使得Number.Random()转换成为常量,从而所有行得到相同的值(via: Ehren)。在PowerQuery编辑器界面,强制产生不同的随机数常见操作一是加入索引列,二是使用= List.Random(Table.RowCount()){[Index]},最后可用类似Number.RandomBetween(0.5+[SomeNumber]-[SomeNumber],10.5) 这种方法。在添加随机数列之前添加Table.Buffer是有意义的。还有Colin Banfield的这样一段话,如何选择M还是DAX使用随机数。
The moral of the story is that you use random numbers in Power Query if you need to perform a
calculation based on a random value, or if you need a random sample of your source data(sort on
the random column and select the top n rows). Otherwise, you are better off creating a random
number calculated column in the data model using DAX.

