@geyee 奇怪,连接和部分内容被吞了,参考自 Applications experience forcibly closed TLS connection errors when connecting SQL Servers in Windows。官方的文章个人理解是客户端和服务端是否包含前导0补丁更新导致的使用 TLS_DHE 时计算值不同,而连接被关闭。解决方法是要么安装补丁或升级系统,要么禁用 TLS_DHE 。
专栏文章
没有任何数据~~
最近问题
没有任何数据~~
最新评论
-
win11 电脑数据库连接 SQLSERVER 提示 SSL PROVIDER ERROR:0
at 2023-06-30 14:51:32
-
win11 电脑数据库连接 SQLSERVER 提示 SSL PROVIDER ERROR:0
at 2023-06-30 14:28:19
对应的英文错误详细信息```
A connection was successfully established with the server, but then an error occurred during the login process. (provider: SSL Provider, error: 0 - An existing connection was forcibly closed by the remote host.)后者可以使用组策略:开始菜单运行栏输入 gpedit.msc 访问本地组策略编辑器,计算机配置——管理模板——网络——SSL配置设置——SSL密码套件顺序——已启用。或者 PowerShell 脚本——foreach ($CipherSuite in $(Get-TlsCipherSuite).Name)
{
if ( $CipherSuite.substring(0,7) -eq "TLS_DHE" )
{
"Disabling cipher suite: " + $CipherSuite
Disable-TlsCipherSuite -Name $CipherSuite
}
else
{
"Existing enabled cipher suite will remain enabled: " + $CipherSuite
}
}前者需要安装补丁或升级系统。 >+ Windows Server 2016, version 1607 + KB 4537806: February 25, 2020-KB4537806 (OS Build 14393.3542) + KB 4540670: March 10, 2020-KB4540670 (OS Build 14393.3564) + Updates that supersede KB4537806 and KB4540670 for the respective OS versions + Windows Server 2019 RTM and later versions. + Windows 10, version 1511, and later versions of Windows 10 当然可以查看一下SQLServer中有无错误日志。尝试其他客户端看能否正常连接,检查防火墙设置,检查 SSL/TLS 设置, SQL Server 配置管理器下是否启用了TCP/IP协议等等。 -
自动删除字段 全部是 null 或 0 的列
at 2020-01-06 21:08:49
考虑筛选不包含0, null等的列形成的list的步骤 = List.Select( List.Transform(Table.ColumnNames(源), (x)=>Table.SelectColumns(源, x)), each List.Transform(Table.ToColumns(_),(y)=>List.RemoveItems(y, {0,"0",null,"null",""}) ){0}<>{} ),试写出自定义函数如下——
(t as table)=>[ a=List.Select( List.Transform(Table.ColumnNames(t), (x)=>Table.SelectColumns(t, x)), each List.Transform( Table.ToColumns(_), (y)=> List.RemoveItems(y, {0,"0",null,"null",""}) ){0}<>{} ), b=List.Transform( List.Zip( List.Transform(a, each Table.ToRows(_))),List.Combine), c= List.Combine( List.Transform(a, Table.ColumnNames)), d=Table.FromRows(b, c) ][d]或者添加如下步骤
= List.Accumulate( List.Combine( List.Transform( List.Select( List.Transform(Table.ColumnNames(源), (x)=>Table.SelectColumns(源, x)), each List.Transform(Table.ToColumns(_), (y)=> List.RemoveItems(y, {0, "0", null,"null", ""}) ){0}={} ), Table.ColumnNames)), 源, (s, c)=>Table.RemoveColumns(s, c)) -
工作需要,想用 power query 作一个 现金日记账,但始终实现不了,请大神帮忙
at 2020-01-06 16:14:06
拼凑了一个,步骤应该可以优化下。
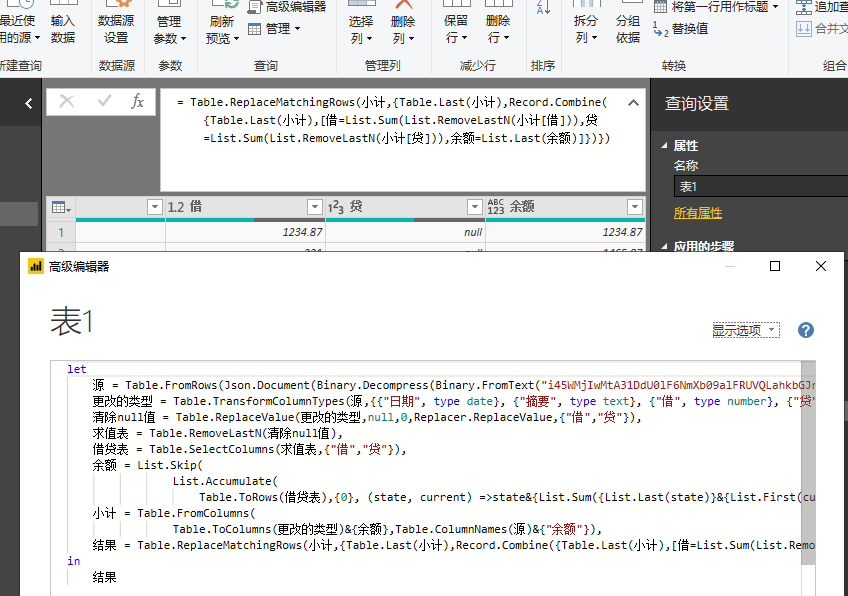
let 源 = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMjIwMtA31DdU0lF6NmXb09alFRUVQLahkbGJnoU5kKUUqwNXZYSmysjYEE2FMVjF+qftuyAqgMjYxBRZhQmmCiMDA2QVpuhuMQACNHvM0F2CqcQc0yITUxSnWGBxiqEhinfA4TJnzbM5HU839L9YtxCiSik2FgA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [日期 = _t, 摘要 = _t, 借 = _t, 贷 = _t]), 更改的类型 = Table.TransformColumnTypes(源,{{"日期", type date}, {"摘要", type text}, {"借", type number}, {"贷", Int64.Type}}), 清除null值 = Table.ReplaceValue(更改的类型,null,0,Replacer.ReplaceValue,{"借","贷"}), 求值表 = Table.RemoveLastN(清除null值), 借贷表 = Table.SelectColumns(求值表,{"借","贷"}), 余额 = List.Skip( List.Accumulate( Table.ToRows(借贷表),{0}, (state, current) =>state&{List.Sum({List.Last(state)}&{List.First(current)-List.Last(current)})})), 小计 = Table.FromColumns( Table.ToColumns(更改的类型)&{余额},Table.ColumnNames(源)&{"余额"}), 结果 = Table.ReplaceMatchingRows(小计,{Table.Last(小计),Record.Combine({Table.Last(小计),[借=List.Sum(List.RemoveLastN(小计[借])),贷=List.Sum(List.RemoveLastN(小计[贷])),余额=List.Last(余额)]})}) in 结果 -
文本提取: [爬 (无)](http://xxx/) 怎样提取出 [] 内容和 () 内容
at 2019-12-25 23:56:25
@wgf4242 索引既可以是0,也可以是{0, RelativePosition.FromStart},还可以是{0, 0},其中第2个0对应RelativePosition.FromStart(1则对应RelativePosition.FromEnd),第一个0自然是索引。RelativePosition.FromStart或0是从左到右数,RelativePosition.FromEnd或1是从右到左数。Text.BetweenDelimiters共5个参数,最后两个参数为可选(索引)参数。索引参数可以选择数值,或者适当两个元素的list,或者为空(无后一参数的情况下)。若参数为0,则表示从左向右数第1个对应符号(左括号或右括号)的位置,为1,则表示第2个对应符号的位置。若参数大于对应符号的数量减1,则可看做无穷远处,结果返回空或者截断左边的对应位置的符号后的剩余右边部分(从左向右数时)。需要注意第5参数是相对第4参数的(endIndex相对startIndex编制索引)。可以看站长的帖子Text.Before/After/BetweenDelimiter(s)或者官方的帮助验证下。解答写成list是为了实践下参数,在该例中当然可以直接去掉。
-
文本提取: [爬 (无)](http://xxx/) 怎样提取出 [] 内容和 () 内容
at 2019-12-25 17:01:37
Text.BetweenDelimiters 设定可选参数即可。该例暂未使用正则、Text.Remove。
let Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45Win66ffnzKSuebl/6tHX7+z09zzq7n3V1gcipM5/sXfC0cdbT9l0vV894umT5kx1dz2e1pCQWZyTlJxalvFy57+XKbS86NsZqZJSUFFjp65eXl+uV5JeWZCbm6yXn5+pnlqTm6puZmxtbmphZmJuYGFsYWBoamRvpayrF6gCtft6x5sXM1c+6GoBueL9n1vNVjc8XbHna2ft89fqn/b0vNjS/WD9V49n0BS9nTkhJTSpNT08t0iRomaGRmaWxgaGxhYWhhZGBkQHIslgA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [List = _t]), 源 = Excel.CurrentWorkbook(){[Name="表2"]}[Content], 更改的类型 = Table.TransformColumnTypes(源,{{"List", type text}}), 自定义1 = Table.TransformColumns(源, {"List", each [a=Text.BetweenDelimiters(_,"[","](",{0, RelativePosition.FromStart}),b=Text.BetweenDelimiters(_,"](",")", {0, RelativePosition.FromEnd},0)]}), #"展开的“List”" = Table.ExpandRecordColumn(自定义1, "List", {"a", "b"}, {"a", "b"}) in #"展开的“List”" -
网抓深化提取 Excel 文件数据问题
at 2019-12-12 01:39:07
不使用M语言的Excel.Workbook解析,而使用OLE DB查询或者Microsoft Query一样得到77列的数据(列名F1至F77),不包含对应excel表的首列,末列为null列/空列。经测试,可排除文档被锁定(ads备选数据流问题)而导致的无法读取第一列的问题。文件头d0cf11e0a1b11ae1,符合excel的格式。
搜索知First Column of excel file not reading oledb reader in window application, excel file data not reading,然而并无合适的解答。另一个帖子First Column not returning while reading excel sheet using oledb reader也没有满意的答复。Stackoverflow上的其他类似帖子也未找到终极答案。
我们在使用PowerBIDesktop时,可能会遇到提示安装AccessDatabaseEngine_X64以能解析早期2003版本的excel文件的情况。由此,猜测使用Excel.Workbook函数时,调用了'Microsoft.ACE.OLEDB.12.0' provider,但其没能正确地解析表格。虽然可以使用excel打开再另存一下相应文件就可以正确解析,但那是另一个问题了(参看当 powerquery 遇上受保护的视图?)。附一个可能有用的链接Dynamic Excel file loading with SSIS。
题主没有写错,是Excel自身的问题(需要更好的复合文档解析引擎),xlsx比xls更容易解析。基本可看成php导出为xls文件,ole db查询无法解析其首列的问题。
-
OLE DB 或 ODBC 错误
at 2019-11-26 15:52:24
该问题对应的英文出错提示大概这这样—— OLE DB or ODBC error: [DataSource.Error]: error when reading data from provider: Guid should contain 32 digits with 4 dashes (xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx).或许要问自己几个问题:两个数据库的版本一致吗, 安装的MySQL Connector/Net组件版本合适吗,账号、密码重新输入也出错吗,以及用其他MySQL客户端程序能否查询数据。看到一篇涉及“GUID 4个短划线 32位数”问题的文章《MySQL中char(36)被认为是GUID导致的BUG及解决方案》,阅读它可能有帮助。
-
如何采集同一网页地址,通过点击按钮的其他数据
at 2019-11-10 10:50:16
@风好大压力 Ctrl+Shift+I或F12 选择终端,看截图
 ,可先搜索下"浏览器 终端 javascript 调试 "关键词学习下。
,可先搜索下"浏览器 终端 javascript 调试 "关键词学习下。 -
为什么抓取内网系统数据,在 header 里已经添加了 cookie 信息,提交 URL 的时候仍然转到了登录页面
at 2019-11-09 23:43:00
搜索“ASP.NET_SessionId”关键词了解到asp.net页面维持机制有 Session, Cookie, ViewState等。可以先测试下直接针对查询页面的Cookie访问是否可行。下列步骤需要替换网址及Cookie--
let Source= Web.Contents("http://localhost/Default.aspx", [ Headers=[Cookie="ASP.NET_SessionId=h2gy3solpc3134q1n3grv1kt" ]]), parse_data=Text.FromBinary(Source) in parse_data再看看查询时是否需要__VIEWSTATE、__VIEWSTATEGENERATOR等参数,如需要,是要编码放到Content里的(post的web请求)。
-
如何采集同一网页地址,通过点击按钮的其他数据
at 2019-11-09 20:50:28
SummaryJs.js 里的ClickTechType函数监听对"进攻数据"、"防守数据"的点击事件,控制切换style样式为diplay:none或者为空。所需数据完全在网页按F12或者Ctrl+Shift+I(检查)可见,而不必翻页(showpage函数及作用于techLogic对象的showPageCountList方法也控制分页显示)。Power Query的Web.Contents得到网页的二进制数据,Text.FromBinary或者Lines.FromBinary解析又无法提供更多信息,同时Web.Page函数没找到可以模拟点击事件的方法 ,WebAction.Request又暂不可用,在浏览器终端利用JavaScript获得数据倒是可以。值得注意的一点是,不同版本Excel和PowerBI Desktop上的Web.Page解析网页结构化数据的效果可能是不一样的,最新版的效果看着好些。
需要锚定获取数据的区域,如利用
document.getElementsByClassName("data"),document.getElementsByTagName("tbody")
,document.getElementById("Tech_sclass"),来初步定位数据。考虑利用Data URLs( data URI scheme)来包装及下载数据,利用畅心老师的前端下载的现成代码再加工下就成。在网站对应的浏览器终端输入如下var tb=document.getElementsByClassName("data")[3].getElementsByTagName("tbody")[0].innerHTML; var tb=tb.replace(/style="display: none;"/g,''); var template =`<html><head><meta charset="UTF-8"></head><body><table>${tb}</table></body></html>`; window.location.href = 'data:application/vnd.ms-excel;base64,' + btoa(unescape(encodeURIComponent(template)));``` 得到的结果是进攻数据和防护数据混合在一起的html格式的伪excel文件(需要excel打开启用编辑然后再另存一下就OK了),如果需要分门别类的,尚需考虑。 抓取类似方式呈现的数据,可能Python、C#等更在行些,或者选用一些第三方的网抓、采集工具,如码栈、八爪鱼等。由于学识尚浅,部分描述可能有技术性错误,见谅。  -
PQ 中索引列与随机数的关系
at 2019-11-08 16:08:02
值得注意的是Random Number being changed to the same number for all rows这个问答,提到一般而言函数是幂等的( idempotent ),optimization pipeline使得Number.Random()转换成为常量,从而所有行得到相同的值(via: Ehren)。在PowerQuery编辑器界面,强制产生不同的随机数常见操作一是加入索引列,二是使用= List.Random(Table.RowCount()){[Index]},最后可用类似Number.RandomBetween(0.5+[SomeNumber]-[SomeNumber],10.5) 这种方法。在添加随机数列之前添加Table.Buffer是有意义的。还有Colin Banfield的这样一段话,如何选择M还是DAX使用随机数。
The moral of the story is that you use random numbers in Power Query if you need to perform a calculation based on a random value, or if you need a random sample of your source data(sort on the random column and select the top n rows). Otherwise, you are better off creating a random number calculated column in the data model using DAX. -
PQ 中索引列与随机数的关系
at 2019-11-07 14:18:55
@跑 添加随机数的前一个步骤(随机函数作用于的项),比如源,如果源本身被Table.Buffer过,或者表结构发生变化(相对于上一步后者内层计算单元),则Power Query编辑器看到随机数这一步骤的各行随机数各不相同。虽然不用提及dax的上下文,环境上下文倒是应当提及,也就是考虑相应步骤内函数作用的对象的构成。使用Table.Repeat可观察到先相同再不同的随机数。归根结缔,当然与PowerQuery的数据结构与算法实现有关。随机数的相同与否,感觉也与Power Query的惰性计算Lazy Evaluation特点有关,是一个feature,是计算资源利用优化的结果。
如果数据源经过数据类型转换,或是添加或删除列操作(非索引列),或是修改列名的操作等,那么生成的随机数便是相同的了。数据在内存中的状态是亦失的(不稳定的),则给到的资源便宜惰性(并行)计算(而有 same value in all cells in a Column),反之,则需要更多的计算资源来运算,个人这样理解,不清楚对不对。
-
PQ 中索引列与随机数的关系
at 2019-11-07 12:24:07
How to get a random sample of data with Power Query提到PowerQuery是一种parallel language,通过添加index索引可强制所有行运行随机函数。包含随机值的结果加载到工作表后,可能变成同一值,可通过Table.Buffer解决。添加索引、添加随机数及Table.Buffer,这三个步骤需要依次紧挨着。更多理解可能需要了解Microsoft.Mashup.Evaluator、Microsoft Mashup Evaluation Container了。猜测,添加索引后,后继的步骤中的随机数函数的种子(seed)就改变了。行上下文是dax中的概念,应该不牵扯PowerQuery吧?
-
power bi 本地部署后,通过 Web 门户 URL 查看报表 报错:无法连接到 Analysis Services 服务器。请确保已正确输入连接字符串。
at 2019-11-05 11:46:05
搜索这篇文章Power BI: We couldn’t connect to the Analysis Services server. Make sure you’ve entered the connection string correctly,提到SQL Server数据库连接是Direct Query而非Import Query时,需要在PowerBI web门户网站重新输入登录凭据(本机用户名密码或SQLServer数据库的用户名及密码)。
In this case, you will need to provide again the login credential of the report data source from the Power BI Web Portal.
可按原文试试,如果不能解决,可考虑再次检索相应英文关键词。 -
百度接口 进行文本分析 GBK 格式转换错误
at 2019-10-10 23:05:20
查看 百度nlp词法分析接口文档 ,需要 post 方法提交 json 格式的数据向带有 access_token 的指定网址,access_token 由发送带有 apikey(client_id)和 secretkey(secret_id)的指定网址的请求返回的json数据取得。
前者可以添加 charset=UTF-8 参数以 utf-8 格式来 post utf-8 格式的 json 数据,而其默认是 gbk 编码的。返回的数据依然是json格式,故有——(wb) => let token_url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=*&client_secret=*", token_headers = [#"Content-Type"="application/json; charset=UTF-8"], token = Json.Document(Web.Contents(token_url))[access_token], text_url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?access_token="&token, text_headers = [#"Content-Type"="application/json"], text_content = "{""text"":"""&wb&"""}", result=Json.Document(Web.Contents(text_url,[Content=Text.ToBinary(text_content, 936)]), 936) in Table.FromRecords(result[items])
其中,text_url对应的可以改成"https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token="&token, 以及 result 改为 Json.Document(Web.Contents(text_url,[Content=Text.ToBinary(text_content)])) 。继而想到 utf-8 与 gbk 编码解码的问题,看样子暂时用不到 Uri.EscapeDataString 。
*星号需要替换一下自己申请得来的百度AI开放平台相应应用(如 产品服务 / 自然语言处理 - 应用列表 / 应用详情 下的)的值,自不必说。 -
网抓 网址请求方式为 post,已找到数据,研究半天没成功抓取到。求解
at 2019-09-05 18:15:14
@绿夏 用户分析数据接口需要通过开发者中心页(微信公众平台=》开发=》接口权限)->用户管理下开通相应接口权限,但开通用户管理接口需要微信认证,微信认证个人公众号不给办(账号主体为个人), 否则返回48001全局返回码。试写自定义函数如下:
(ACCESS_TOKEN)=> let bin=Web.Contents("https://api.weixin.qq.com/datacube/getusersummary?access_token="&ACCESS_TOKEN,[Content=Text.ToBinary(datejsontext)]), datejsontext = "{ ""begin_date"": ""2014-12-02"", ""end_date"": ""2014-12-07"" }" in Json.Document(bin) -
数据处理问题
at 2019-09-05 14:43:27
如果规则2只处理仅有一个空行的话,还是可以用List.Accumulate,否则的话可能需要借助索引等辅助,走分组标记子查询的方法。
let 源 = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("Zc3BDcMwCAXQXThH6IMN2At0hR4s779GsFslUSv5APjr/TFIRToUqEYHvV/SHRBFLhbsKDlorzkWmsegXD9PQo0r9vEy/GtEGtCVMta25E3ED1HyN26hAlZvAa2tkHPrvgvDGI9CAUr8xdl3H815Ag==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [销售合同号 = _t, 外销发票号 = _t, 重量 = _t, #"分摊金额(含税)" = _t]), tlist = List.RemoveLastN(Table.ToRows(源),0), 转换 = List.Accumulate(tlist,{},(s,c)=>if Text.Length(c{2})<=1 then List.RemoveLastN(s)&{List.RemoveLastN(List.Last(s))&{List.Sum(List.Transform({List.Last(List.Last(s)),c{3}},Number.From))} } else s&{c}), 转换2 = List.Accumulate(转换,{},(s,c)=>if Text.Length(Text.From(c{3}))<=1 then List.RemoveLastN(s) & { List.RemoveLastN(List.Last(s)) & { Number.From( List.Last(s){2} ) / List.Sum( List.Transform({ List.Last(s){2}, c{2} }, Number.From) ) * Number.From(List.Last(s){3}) } } & {List.RemoveLastN(c)&{ Number.From(c{2}) / List.Sum(List.Transform({List.Last(s){2}, c{2} },Number.From) ) * Number.From(List.Last(s){3})} } else s&{c}), result = Table.FromRows(转换2,Table.ColumnNames(源)) in result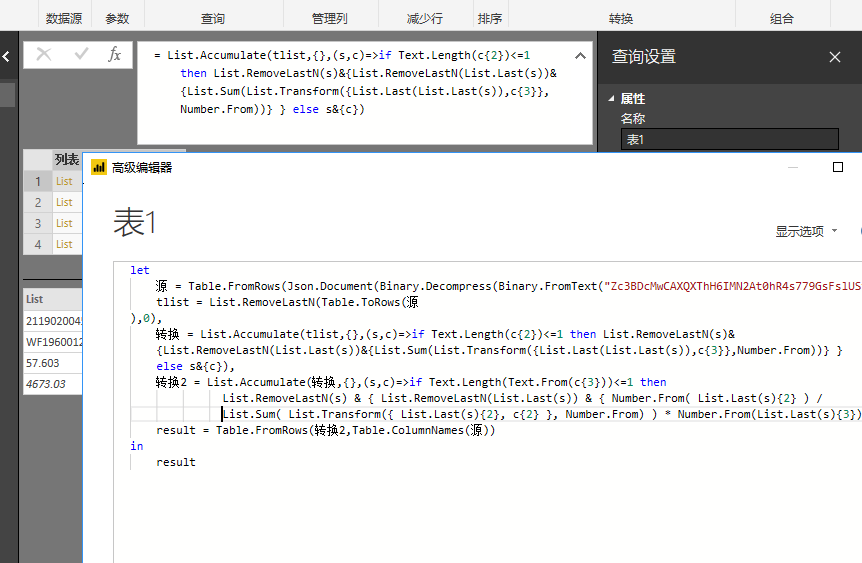
-
M 语言-隔行提取某列中的信息并转至表格
at 2019-09-03 21:05:13
如果是按第二列,每三行一组,然后三行变三列再加上分组的列,如下显示
let 源 = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WMs7JLElV0skrzcmJ1YlW8krMy84vy0xW0lHyzcxJzFMCCQYUZeYlZxYk5iDUoWnzTSwqzkjMASpQck/NT0srSq2E6EwsKslLLcKuLxYA"),Compression.Deflate)),let _t = ((type text) meta [Serialized.Text = true]) in type table [Column1.1 = _t, Column1.2 = _t]), 三行拆分 = List.Transform(Table.Split(源,3),each #table({"Column1.2","col2","col3","col4"},{List.FirstN(List.Combine({{_[Column1.2]{1}?}, _[Column1.1]&{null,null}}),4)})), 合并 = Table.Combine(三行拆分) in 合并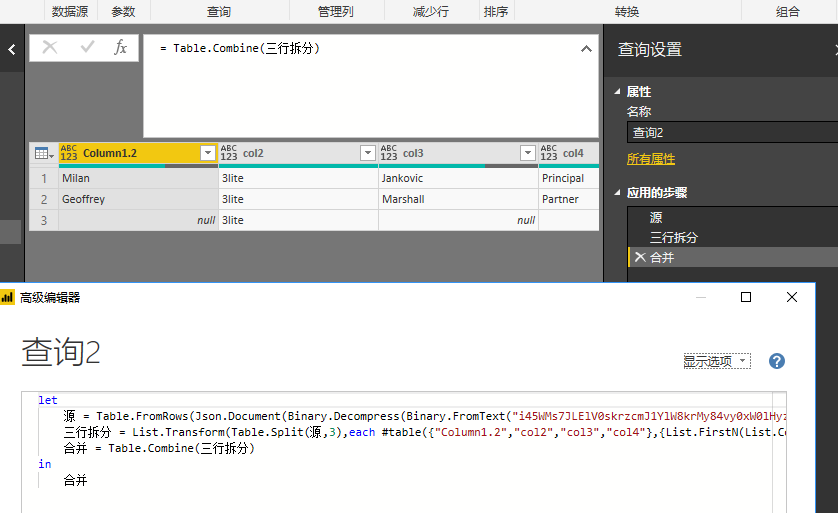
再次分析题主的意思,估计是按第一列3开头的为分组开始拆分,则首列可变为
= List.Accumulate(源[Column1.1],{""},(s,c)=>if Text.At(c,0)="3" then s&{{c}} else List.RemoveLastN(s,1)&{List.Last(s)&{c}}),进而有let 源 = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("dY1BCoRADAT/kvPcfIS4MKCehMFDcKMGQ0biKPj7VRSEBY/dVHWHAJlwInC6irQuwAd1iht34MCzoMJZlsba8YzycH+aR1tGlAOAnGLfG+2XiZaU7NXLfNE8qVp31OHYqOP9Swt/SdONtD8="),Compression.Deflate))), 合并列 = Table.CombineColumns(源,Table.ColumnNames(源),each Text.Combine(_,"-"),"合并"), 分组 = List.Skip(List.Accumulate(合并列[合并],{""},(s,c)=>if Text.At(c,0)="3" then s&{{c}} else List.RemoveLastN(s,1)&{List.Last(s)&{c}})), 修正 = List.Transform(分组,each if List.Count(_)<3 then List.FirstN(_&{null,null},3) else _), 转换 = Table.FromRows(修正,{"Col1","Col2","Col3"}), 按分隔符拆分列 = Table.SplitColumn(转换, "Col2", Splitter.SplitTextByDelimiter("-", QuoteStyle.Csv), {"Col2.1", "Col2.2"}), 更改的类型 = Table.TransformColumnTypes(按分隔符拆分列,{{"Col2.1", type text}, {"Col2.2", type text}}) in 更改的类型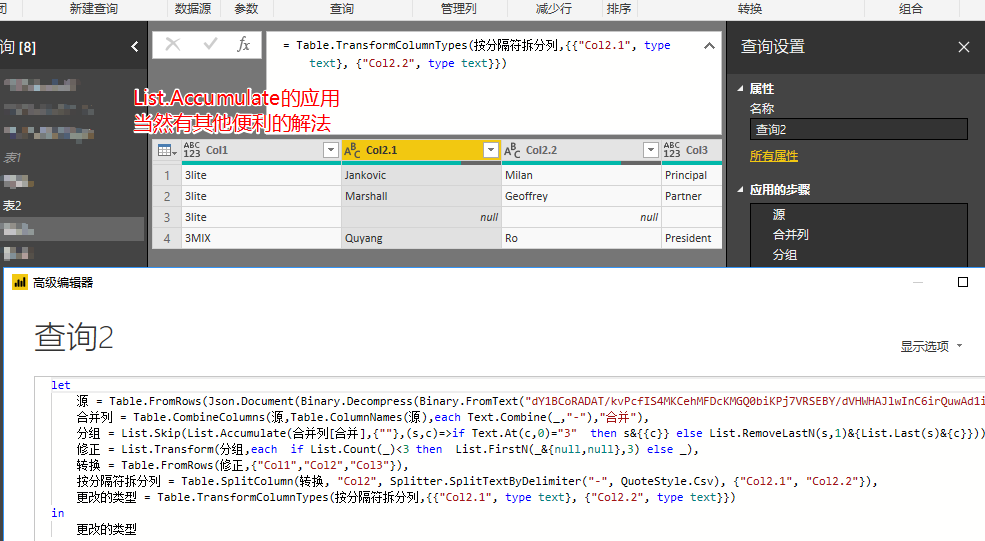
-
如何在表格的文本中 计算金额合计
at 2019-09-03 15:17:45
该题识别为提取数字,不含小数点及千分位符等,可以考虑引入Web.Page正则查找等。其他解决方案可能用到Splitter.SplitTextByAnyDelimiter,Character.FromNumber,List.Accumulate,Expression.Evaluate等函数。一个适用部分情况的简单的解答为
let 源 = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WSjRU0lF6umn2846NTzs2PNm7wNjgaWvz+z09z2e1PF2y/OWM/U83THk6tcsEJKwUqwPUYQTU8Xz5+qcdbeYGMMUbdz9tXfF8QrOlhTlQ5HFDE0SpMVDpy0XtQCOAip7s7Hg6dZmZqbkJRNOTPb0vN7eYmcENNgGqfrZm+dMVjUDy2bR2MyMDHCpNgSpfrN8GdN3L9h5DA4iV4fmZqUYQZ8YCAA==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [类型1 = _t, 数据 = _t]), 求和 = Table.AddColumn(源, "合计", each List.Sum(List.Transform(Text.SplitAny([数据], Text.Remove([数据],{"0".."9"})),Number.From))) in 求和思路为字符按汉字、标点符号及其他除数字外的特殊符号的任意字符拆分,然后转换为数字再求和。
其他情形,如有小数点等可能PQ表达式就复杂些。