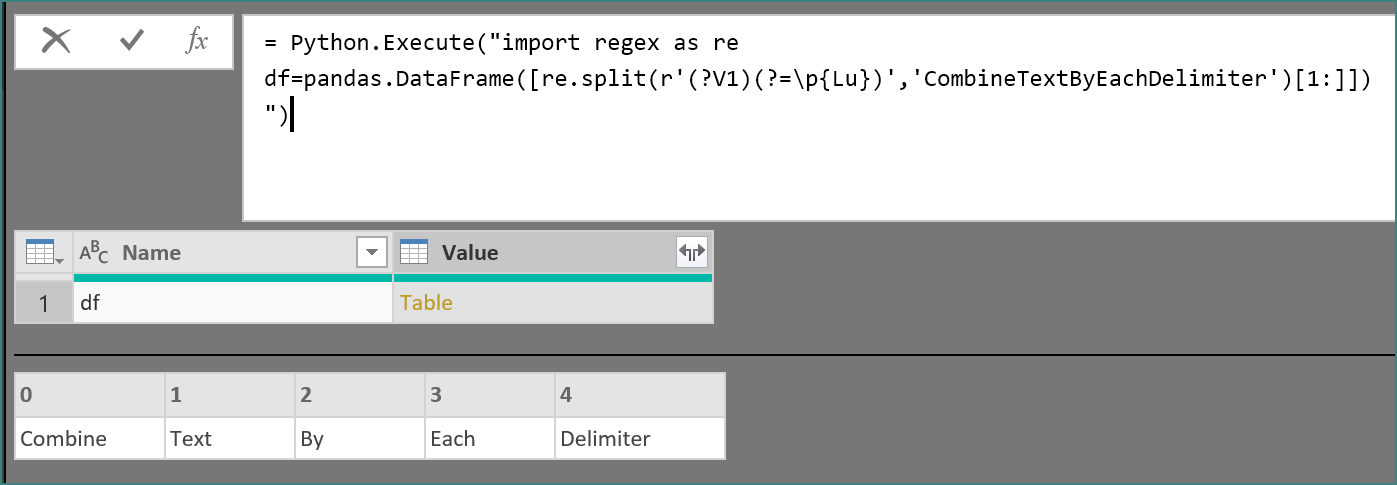
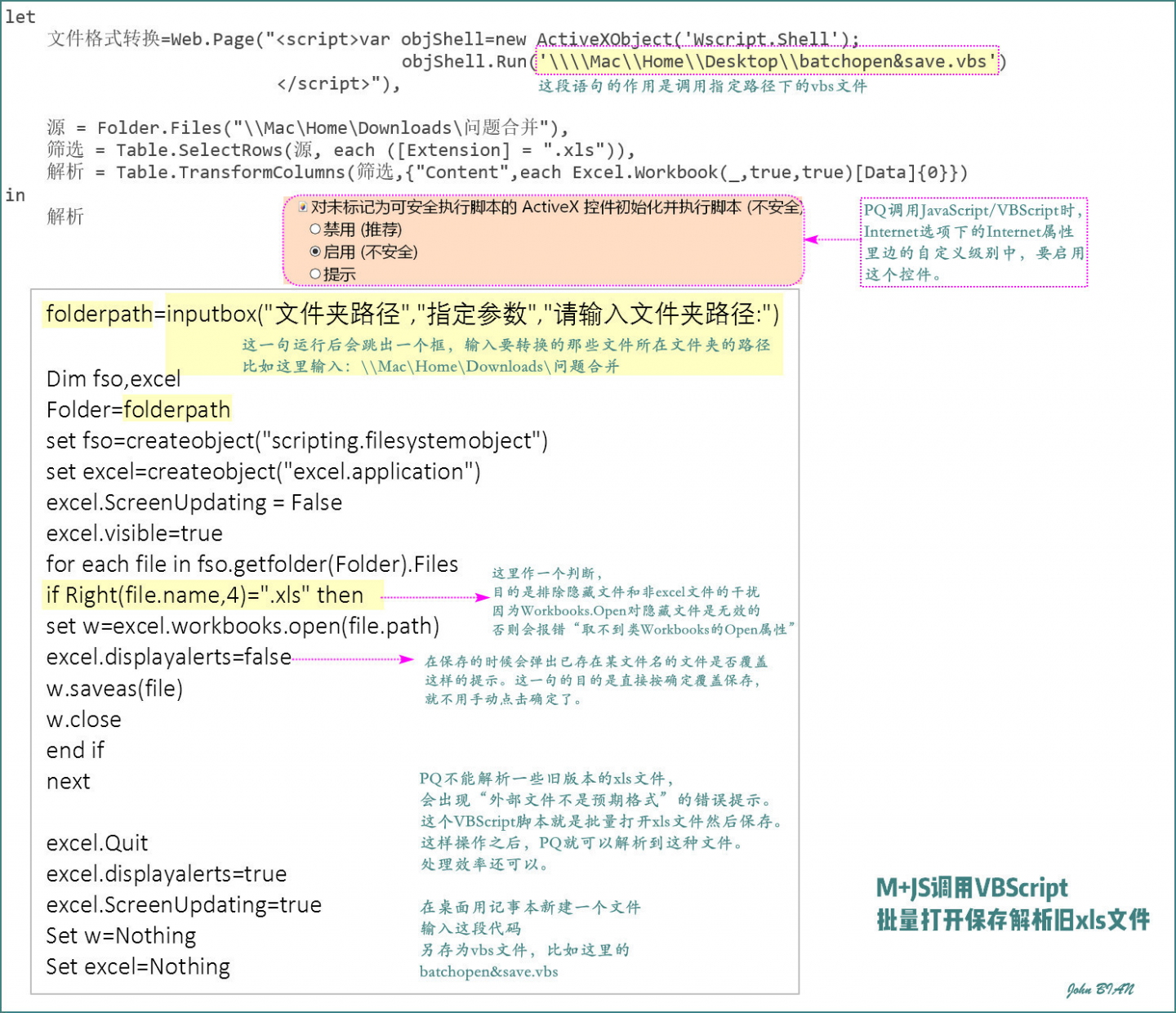
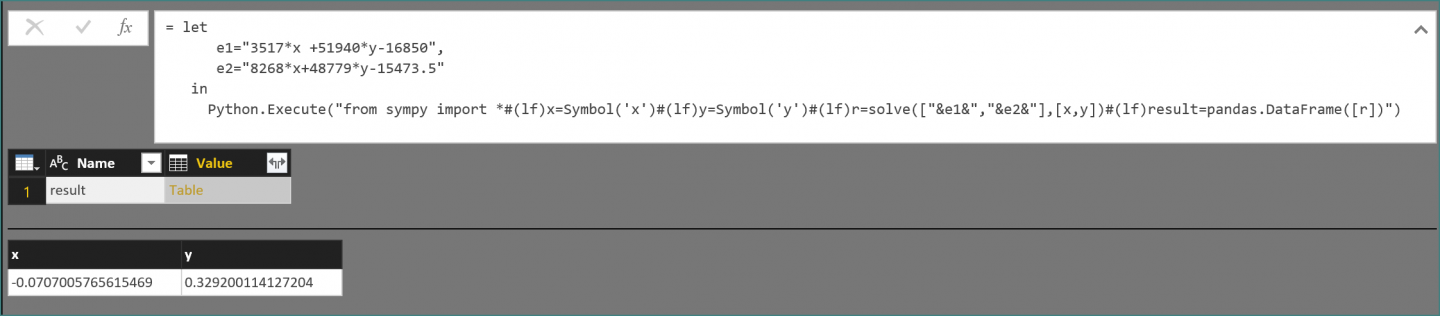
PQ解法,常规思路,供参考!
把代码中的“T = #table(n,{m[b]})”这部分写成“T = #table(n,{D,m[b]})”可以观察到具体的哪些7天。
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
更改 = Table.TransformColumnTypes(源,{{"上市日期", type date}, {"销售日期", type date}}),
分组 = Table.Group(更改, "产品编号", {"a", (z)=>[ m = Table.Group( Table.Buffer(Table.Sort(Table.Combine({z,
#table({"销售日期"},
List.Generate( ()=>z[上市日期]{0},
each _<=List.Max(z[销售日期]),
each Date.AddDays(_,1),
each {_})
) } ),
"销售日期" ) ),
"销售日期",
{"b",each List.Sum([成交金额])},
0,
(x,y)=>Number.From(Date.AddDays(x,7)<=y) ),
D = List.Transform(m[销售日期],each Text.Format("#{0}-#{1}",{_,Date.AddDays(_,6)})),
n = List.Transform({1..List.Count(m[b])},each Number.ToText(_,"第0个7天")),
T = #table(n,{m[b]})]
[T]
},1),
展开 = Table.ExpandTableColumn(分组, "a", List.Max( List.Transform(分组[a],each {Table.ColumnNames(_),Table.ColumnCount(_)}),
null,
each _{1}){0} )
in
展开