@明仔
那部分是Table.Group分组的第五参数,不能省略。
- 个人中心
- Ta 发表的回复(91)
-
表格转换
at 2019-02-27 21:10:49
-
Table.ExpandListColumn 怎么实现同时展开一个表格多行里面的 list
at 2019-01-27 23:20:14
猜一下,展开的“self” 这一步之后,添加一步:
= Table.FromColumns(List.Transform( Table.ToColumns(#"展开的“self”"),List.Combine),Table.ColumnNames(#"展开的“self”"))
-
对多级 BOM 文本列进行正确排序
at 2019-01-20 16:48:04
关于M+JS用“0”补齐位数,经畅心老板斧正,精炼了一下写法。一是JS中的自定义补齐函数用了递归,这样的好处是避免了上述补充方法中需要人为目测一个最长的连续数字长度的做法,可以做到不够位数则补全,足位数的保持原来的状态;第二个是效仿了M的隐式传递,精简了语句。比如,以下例子中把连续数字不足5位的用0补全,其中的function Pad...return Pad就是JS中的递归, replace正则替换的第二参数可以是function,且做了隐式传递,这类似于M中的List.Transform({"1".."3"},Number.From)省略了each _这样的写法。
以下写法是把补全长度在UDF中写成了一个常量:
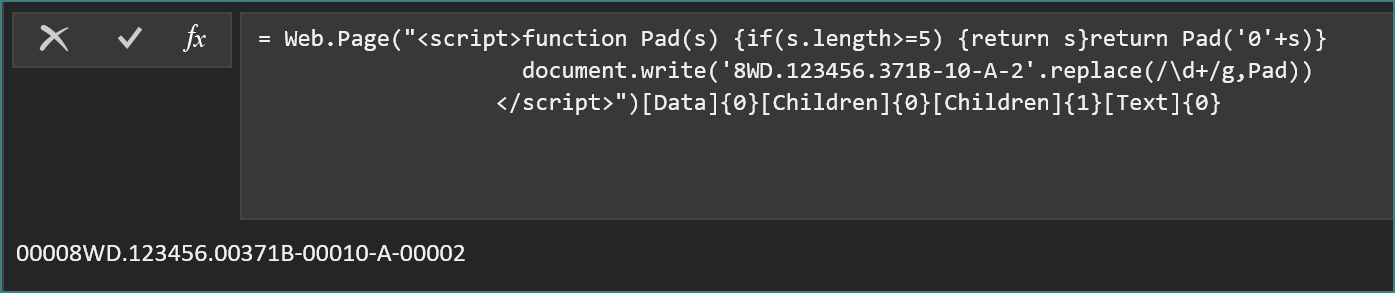
= Web.Page("<script>function Pad(s) {if(s.length>=5) {return s}return Pad('0'+s)} document.write('8WD.123456.371B-10-A-2'.replace(/\d+/g,Pad)) </script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}结果如下图:
如果要传递双参数,比如字符串对象和补全长度都作为参数,那就要这样写:
= Web.Page("<script>function Pad(s,len) {if(s.length>=len) {return s} return Pad('0'+s,len)} document.write('8WD.123456.371B-10-A-2'.replace(/\d+/g,function(x){return Pad(x,5)})) </script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}从Table.Sort第二参数的写法构造引申出这些内容,个人觉得信息量不少。
以上供参考,不妥之处请指正。
-
对多级 BOM 文本列进行正确排序
at 2019-01-19 22:21:51
有朋友没有更新到最新版本的PQ,没有Splitter.SplitTextByCharacterTransition,这个函数有点像正则里的零宽,断的只是一个位置。再提供两种补位的方法:
一个是用JS自定义补位,并配合replace把字符串中的数字替换成补位后的文本数值,优点是简洁,缺点是效率欠佳:
单独的M+JS数字补位方法,连续数字用“0”补全为10位,这个补位的取值必须要大于最大连续数字字符串的长度:= Web.Page("<script>function Pad(num, len) {return (Array(len).join('0') + num).slice(-len);} document.write('8WD.199.371B-10-A-2'.replace(/\d+/g,function(x){return Pad(x,10)})) </script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}运用到排序里:
let 源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content], 排序 = Table.Sort(源, each Web.Page("<script> function Pad(num, len) {return (Array(len).join('0') + num).slice(-len)} document.write('"&[#"Excel排序功能-升序结果"]&"'.replace(/\d+/g,function(x){return Pad(x,20)})) </script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}) in 排序另一种是用List.Accumulate对字符串中的数字进行补位,本来以为用acc会简单一点,写完奔溃了,有点复杂,就当交流参考吧。希望大神能优化一下acc的写法。
单独的accumulate补位语句,连续数字用“0”补全为5位:
= let l=Text.ToList("8WD.199.371B-10-A-1") in List.Accumulate( l&({{"1"},{""}}{Byte.From(List.Contains({"0".."9"},List.Last(l)))}), {"","",l{0}}, (s,c)=>if List.ContainsAll({"0".."9"},{s{2},c}) or (not List.ContainsAny({"0".."9"},{s{2},c})) then {s{0},s{1}&c,c} else {s{0}&{s{1},Text.PadStart(s{1},5,"0")}{Byte.From(s{1}>="0" and s{1}<="9")},c,c}){0}运用到Table.Sort里:
let 源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content], 排序 = Table.Sort( 源, each let l=Text.ToList([#"Excel排序功能-升序结果"]) in List.Accumulate( l&({{"1"},{""}}{Byte.From(List.Contains({"0".."9"},List.Last(l)))}), {"","",l{0}}, (s,c)=>if List.ContainsAll({"0".."9"},{s{2},c}) or (not List.ContainsAny({"0".."9"},{s{2},c})) then {s{0},s{1}&c,c} else { s{0} & { s{1},Text.PadStart(s{1},5,"0") }{Byte.From(s{1}>="0" and s{1}<="9")},c,c}){0}) in 排序 -
对多级 BOM 文本列进行正确排序
at 2019-01-19 13:30:01
@斜杠星号
昏倒,跟着畅老板忙活一上午,你居然没有那个函数,哈哈哈哈哈。。。。
还有一个写法,跟着畅老板学的。 一个是把fx单独写了一步,另一个是把排序的内容先拆了,用0补全为5位数后,合并再排序。供参考:let 源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content], fx = let fx = (x)=>Splitter.SplitTextByCharacterTransition(x,each not List.Contains(x,_)) in fx, 排序 = Table.Sort( 源, each Text.Combine( List.Transform( List.Combine( List.TransformMany( Text.SplitAny([#"Excel排序功能-升序结果"],".- "), each fx({"0".."9"})(_), (x,y)=>fx({"A".."Z"})(y))), (t)=>Text.PadStart(t,5,"0") ) ) ) in 排序 -
对多级 BOM 文本列进行正确排序
at 2019-01-19 12:21:51
(以下语句和方法,得到了畅老板和晨星大佬的指点,谢谢)
有点复杂,也有考虑不到边的情况。我的想法就是把每个ID拆开,只要是数字连在一起的就一起不拆开,有分隔符的就拆开,字母连在一起的还是连在一起,比如"8WD.199.371B-10-A-2"拆成8,WD,199,371,B,10,A,2这样子后,再按每个元素的先后位次按照其对应字符的序列进行排序。不知道这个逻辑是不是对的? 大概弄了一下,按照目前数据源的情况测试,结果是对的。有两种方法,一个是用Splitter.SplitTextByCharacterTransition,一个是用正则,正则简单但速度慢。以下仅供参考,普适性有待检验。源就是你表格左侧的那一列。
方法一:Splitter拆
let 源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content], 排序 = Table.Sort( 源, List.Transform( {0..15}, (x)=>each let fx = (x)=>Splitter.SplitTextByCharacterTransition(x,each not List.Contains(x,_)), l = List.Combine(List.TransformMany( Text.SplitAny([#"Excel排序功能-升序结果"],".- "), each fx({"0".."9"})(_), (x,y)=>fx({"A".."Z"})(y))) in try Number.From(l{x}) otherwise l{x}?)) in 排序方法二:正则拆
let 源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content], 排序 = Table.Sort(源, List.Transform({0..15},(x)=>each Table.TransformColumns( Web.Page("<script> document.write('"&[#"Excel排序功能-升序结果"]&"'.match(/\d+|[A-Z]+/g).join('<br>')) </script>")[Data]{0}[Children]{0}[Children]{1}, {"Text",(x)=>try Number.From(x) otherwise x}) [Text] {x}?)) in 排序还有一个就是你说的补全位数后排序:
let 源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content], 排序 = Table.Sort( 源, List.Transform( {0..15}, (x)=>each let fx = (x)=>Splitter.SplitTextByCharacterTransition(x,each not List.Contains(x,_)), l = List.Transform(List.Combine(List.TransformMany( Text.SplitAny([#"Excel排序功能-升序结果"],".- "), each fx({"0".."9"})(_), (x,y)=>fx({"A".."Z"})(y))),(t)=>Text.PadStart(t,2,"0")) in l{x}?)) in 排序 -
一个单元格内的几行内容如何用拆分列 分离出来
at 2019-01-19 11:39:40
上传一个模拟数据和模拟结果试试
-
对多级 BOM 文本列进行正确排序
at 2019-01-18 20:54:06
这个应该可以用Table.Sort一步出排序结果,只是Table.Sort 的第二参数要花点心思。
-
对多级 BOM 文本列进行正确排序
at 2019-01-18 20:46:05
@斜杠星号
有个问题,1、如果把表里的第二个“4G0 199 379AQ” 改成“14G0 199 379AQ” ,按目前的数据源,它应该排在哪里?最后?
2、你想要的排序规则是不是这样的,以“4G0 199 379AQ”为例,分别按 4、G、0、199、379、AQ,这样的顺序排序?
-
power query 筛选,出来后的数量不一致。
at 2019-01-12 11:59:03
当写成 "not Text.Contains" "not Text.StartsWith" "not ..." 的时候,null 要单独拿出来处理。供参考:
= Table.SelectRows(源, each [字段] is null or (not Text.Contains([字段], "xxx") and not Text.Contains([字段], "yyy"))) -
【求助】table 和 list 分别展开的如何实现数据一一对应?
at 2019-01-12 11:48:50
看看是不是这样:
let 源 = Excel.CurrentWorkbook(){[Name="支付买家pay"]}[Content], 变 = Table.TransformColumns( 源, {}, each Table.FromColumns( { Excel.CurrentWorkbook(){[Name="日期data"]}[Content][日期], Json.Document(_)[data][my] } ) ) {0} [支付买家] in 变 -
如何用最简洁的语句完成以下拆分
at 2019-01-09 23:37:49
这个下划线 怎么自动不见了
Table.ToList(源,each Splitter.SplitTextByAnyDelimiter(delimiters as list)(_{0}))或者
Table.SplitColumn(源,"明细科目",each Splitter.SplitTextByAnyDelimiter(delimiters as list)(_),{列名}) -
如何用最简洁的语句完成以下拆分
at 2019-01-09 23:28:50
@Able
不好意思,翻车了。谢谢找出错误。Text.SplitAny是见啥都拆,比如“币别”,只要是“币”或者“别”都会拆,所以这里币别和人民币这里都拆了。SplitTextByAnyDelimiter是把“币别”作为一个整体拆,所以只拆“币别”,不会拆“人民币”。
改一下就可以了:
= #table( {"明细科目","类别","项目","备注","币种"}, Table.ToList( 源, each List.Skip(List.RemoveItems(Text.SplitAny(_{0},"()-|别:"),{"","币"}))))或者
= Table.SplitColumn( 源, "明细科目", each List.Skip(List.RemoveItems(Text.SplitAny(_,"()-|别:"),{"","币"})), {"明细科目","类别","项目","备注","币种"} )或者你把each 后边的部分换成 each Splitter.SplitTextByAnyDelimiter(delimiters as list)({0}) 或者() 试试
-
如何将累计值得列转换为单个值
at 2019-01-09 16:12:52
PQ,累计求和的逆过程
= List.Accumulate({1,3,6,10,15,21,28,36,45,55},{0,{}},(s,c)=>{c,s{1}&{c-s{0}}}){1} -
power query 可以开车了你知道吗?
at 2019-01-09 15:20:36
@夜幕 Thanks to BOSS畅。。。多亏了畅老板:thumbsup: :thumbsup: