各位老师好,
最近遇到问题如下。试图抓取某卫生洁具品牌官网,每个具体商品型号信息并汇总成表。
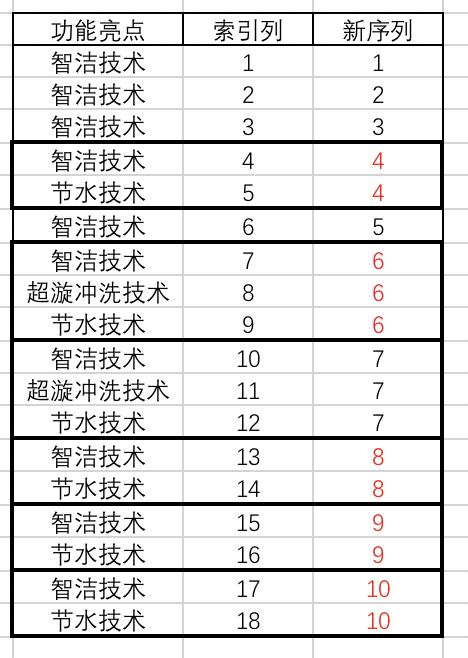
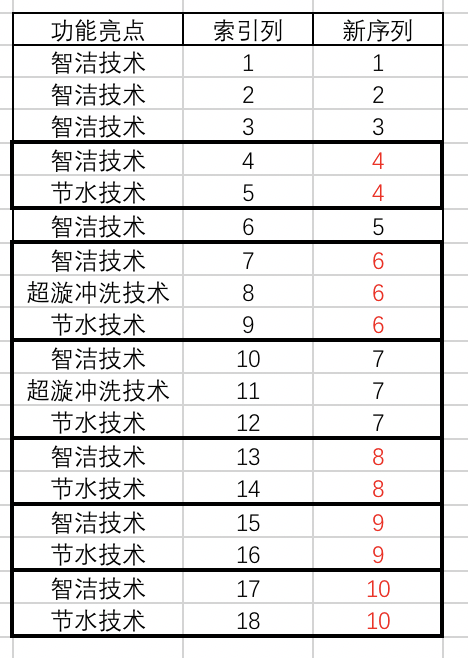
不同商品除了具体型号外,在各自的技术特性上,分别又有支持1~5项特殊亮点。
经过繁杂处理后,已经获得一个页面上所有商品(20个)对应的所有技术特性的文字短语列表。
从人工角度,很容易理解是,每个从”智洁技术“开头的若干词语,属于同一个商品具备的亮点;因此,我希望根据下表左侧的情况,通过索引列的辅助,生成右侧最终的索引顺序列,便于我进一步将相关技术特性,合并在同一个商品下。
但是使用Table.AddColumn时,对于 each和"_" 的使用,都比较混乱。
总是写不对,还望大侠出手指点!
php
已添加自定义 = Table.AddColumn(已添加索引, "新序列", if each _[功能亮点]=[功能亮点]{_-1} if true then 已添加索引{[索引]-1}[索引]+1 else 已添加索引{[索引]-1}[索引])


