
现在我们有一个在线的知识库系统,HTML编辑界面很难用,必须得在Word里面编辑好了再粘贴过来。但是OneNote里面有近千条记录需要进行导入,帖到Word里面再贴出来图片就失效了。原因是OneNote会把图片进行OCR转化成可搜索的格式,而知识库系统的图片采用base64方式编码,整个正文所有多媒体内容都存储在数据库的一个cell里面。问题目前已经解决,找到一个第三方工具可以批量把Word转HTML,在过程中会把图片转化为base64。
但是现在遇到了新问题,茫茫多的HTML文件在同一个文件夹里,如何把他们的代码整理为一个表格方便批量导入呢?尝试了转换成txt文件,PowerBI自动读取也会识别为HTML,需要多级展开。单个文件退回步骤强制打开为TXT,他们会变成一行一行的,不在同一个cell中。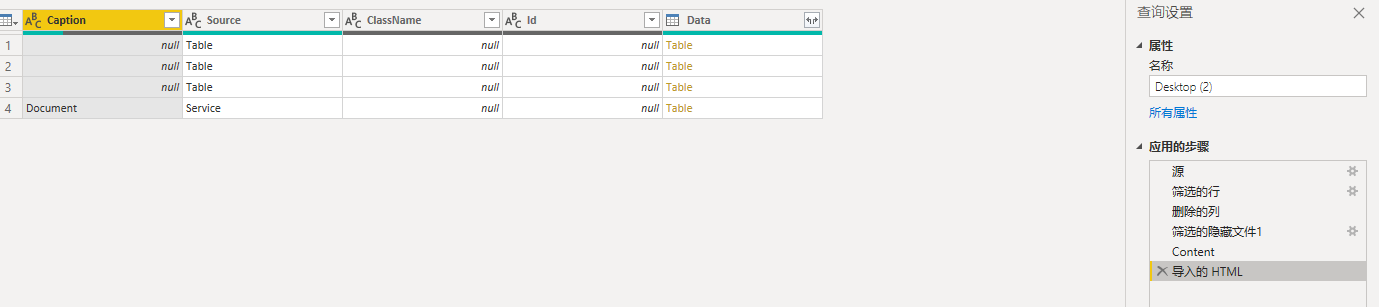

怎样才能实现最终需要的效果呢?
谢谢!





