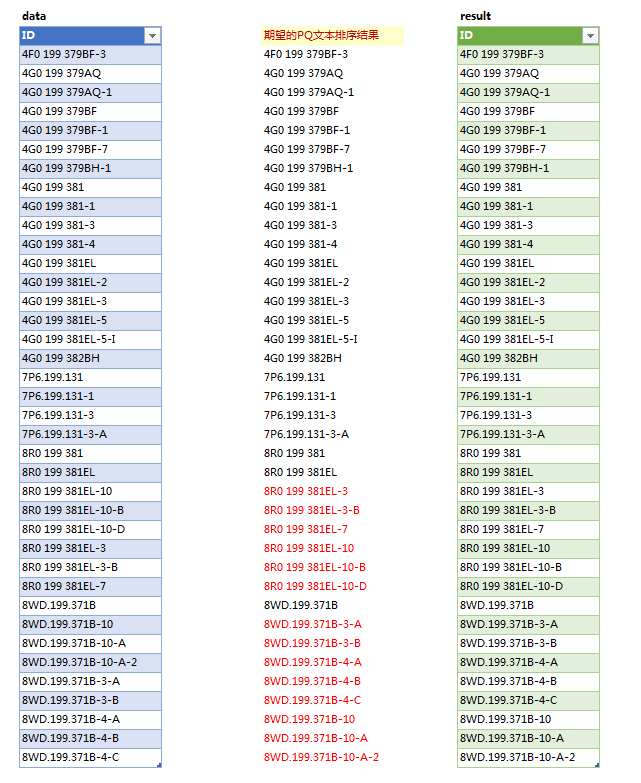
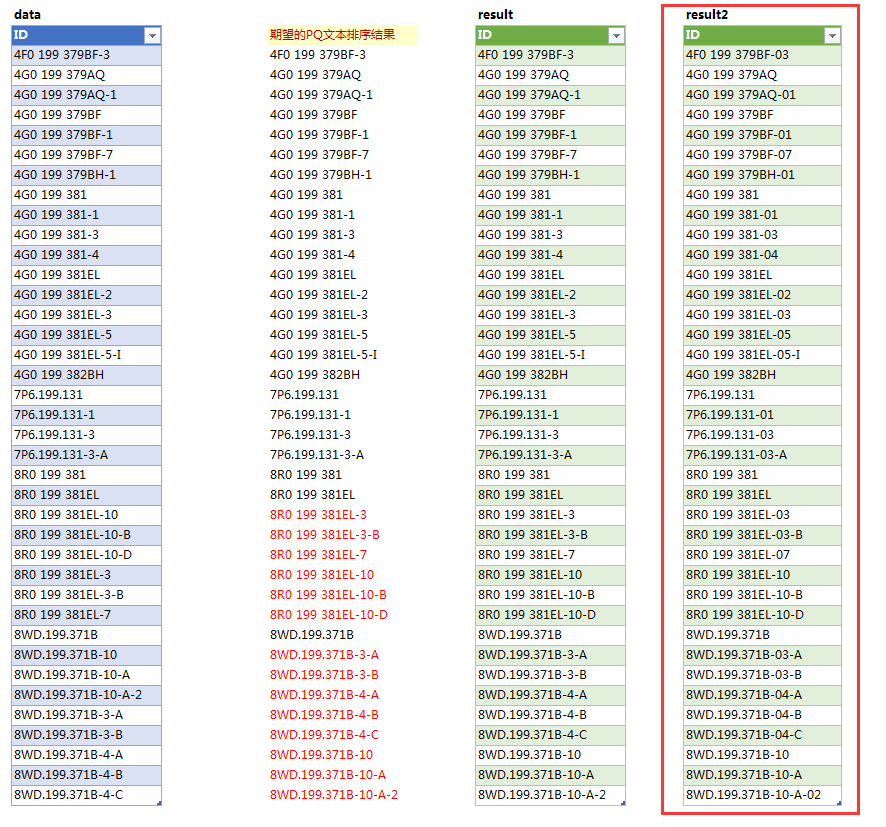
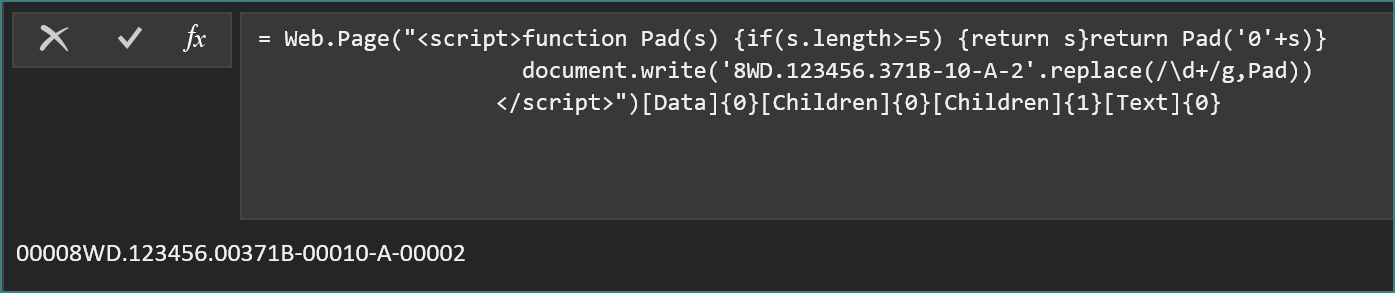
有朋友没有更新到最新版本的PQ,没有Splitter.SplitTextByCharacterTransition,这个函数有点像正则里的零宽,断的只是一个位置。再提供两种补位的方法:
一个是用JS自定义补位,并配合replace把字符串中的数字替换成补位后的文本数值,优点是简洁,缺点是效率欠佳:
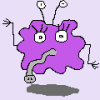
单独的M+JS数字补位方法,连续数字用“0”补全为10位,这个补位的取值必须要大于最大连续数字字符串的长度:
= Web.Page("<script>function Pad(num, len) {return (Array(len).join('0') + num).slice(-len);}
document.write('8WD.199.371B-10-A-2'.replace(/\d+/g,function(x){return Pad(x,10)}))
</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}
运用到排序里:
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
排序 = Table.Sort(源, each Web.Page("<script> function Pad(num, len) {return (Array(len).join('0') + num).slice(-len)}
document.write('"&[#"Excel排序功能-升序结果"]&"'.replace(/\d+/g,function(x){return Pad(x,20)}))
</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0})
in
排序
另一种是用List.Accumulate对字符串中的数字进行补位,本来以为用acc会简单一点,写完奔溃了,有点复杂,就当交流参考吧。希望大神能优化一下acc的写法。
单独的accumulate补位语句,连续数字用“0”补全为5位:
= let l=Text.ToList("8WD.199.371B-10-A-1")
in List.Accumulate( l&({{"1"},{""}}{Byte.From(List.Contains({"0".."9"},List.Last(l)))}),
{"","",l{0}},
(s,c)=>if List.ContainsAll({"0".."9"},{s{2},c}) or (not List.ContainsAny({"0".."9"},{s{2},c}))
then {s{0},s{1}&c,c}
else {s{0}&{s{1},Text.PadStart(s{1},5,"0")}{Byte.From(s{1}>="0" and s{1}<="9")},c,c}){0}
运用到Table.Sort里:
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
排序 = Table.Sort( 源, each let l=Text.ToList([#"Excel排序功能-升序结果"])
in List.Accumulate( l&({{"1"},{""}}{Byte.From(List.Contains({"0".."9"},List.Last(l)))}),
{"","",l{0}},
(s,c)=>if List.ContainsAll({"0".."9"},{s{2},c})
or
(not List.ContainsAny({"0".."9"},{s{2},c}))
then {s{0},s{1}&c,c}
else { s{0}
& { s{1},Text.PadStart(s{1},5,"0") }{Byte.From(s{1}>="0" and s{1}<="9")},c,c}){0})
in
排序