经验不足,在此咨询各位前辈,网抓类通过各类公众号学习,学会了皮毛,利用Json.Document()和Web.Contents()两个函数嵌套能抓取大部分网络数据,主要是找到数据所在的真正网址便可抓取,如下图。现在抓取某网站数据,直接提示error。始终不理解哪里出了问题,求赐教。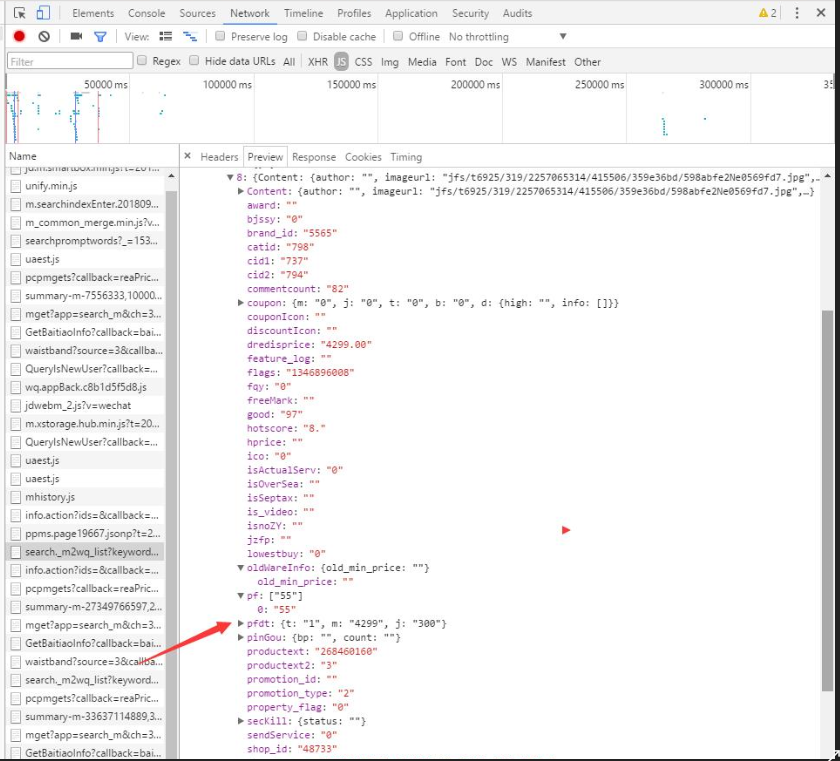
现在找到了所需数据网址为https://so.m.jd.com/ware/search._m2wq_list?keyword=%E5%88%9B%E7%BB%B455G3&datatype=1&callback=jdSearchResultBkCbA&page=2&pagesize=10&ext_attr=no&brand_col=no&price_col=no&color_col=no&size_col=no&ext_attr_sort=no&merge_sku=yes&multi_suppliers=yes&area_ids=1,72,2819&filt_type=redisstore,1;&sort_type=sort_totalsales15_desc&qp_disable=no&fdesc=%E5%8C%97%E4%BA%AC&t1=1538897256595
嵌套两个函数后,直接报错,其余网址均不会出现此情况,在此疑问
①是否网址有多余,我是否删除某些既能正常显示
②是否Json.Document()使用错误,此网址结构是否不同
③是否此网址有时间戳,是否要做一个变量才能成功。其余成功测试的网址没有时间戳。
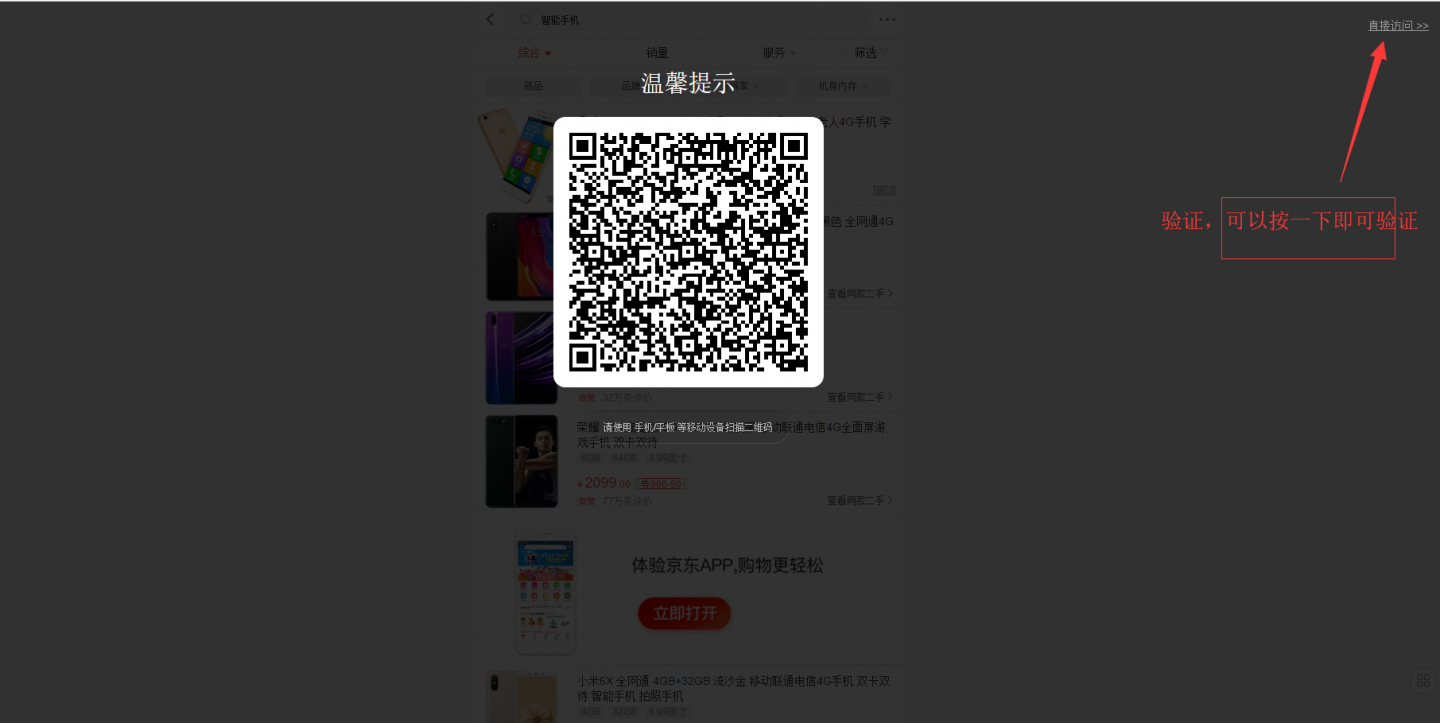
④此网站有一个验证,是否为需要某代码跳过验证,如下图。之前成功抓取的网站是没有弹出这个的。