提取的数据现在几乎是全页面的源代码。但实际向下简头这开始才是我要的数据。这是还缺了什么参数还是怎么了?初学者,还望各位老师不吝赐教。
图1 PQ(因信息敏感,部分内容已处理)
图2 得到的(全是源代码--里面也包含我真正要的数据,且都放在a1单元格内)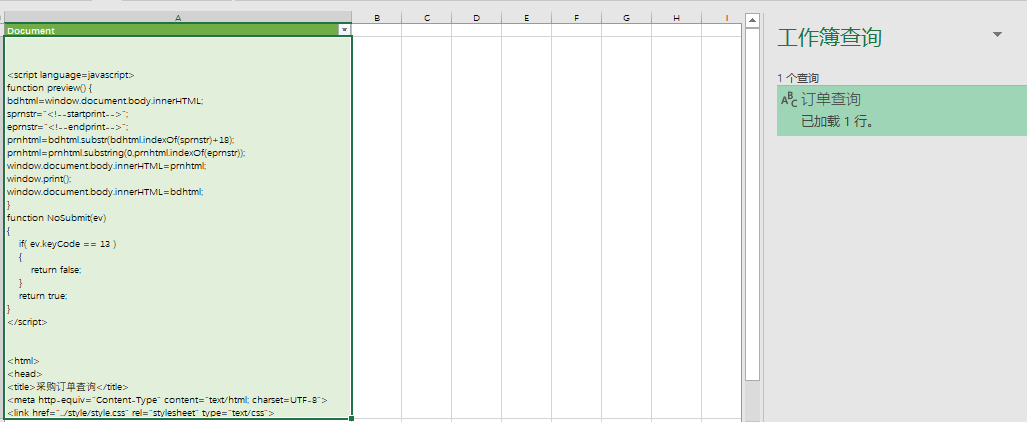
图3 我要的数据在这:
从这开始的(这里有表头)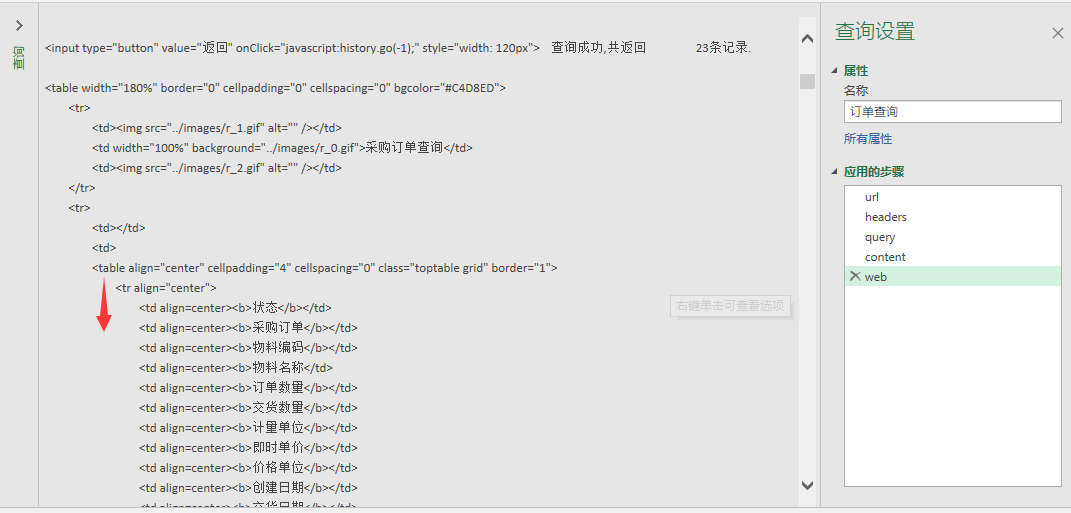
数据是这样的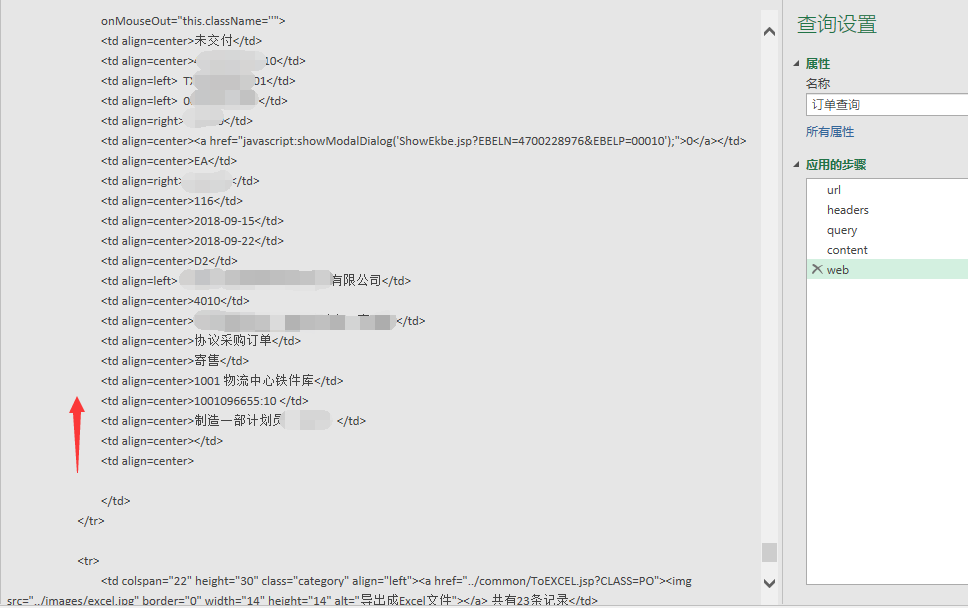
感觉初次模仿改制的网抓离结果只差一步之遥了。或是说这就是已经完成抓包(得到了HTML源代码),如果是,我看数据部分有"table“(图3向下键头位置),是不是就是bable标签?有这种标签的是不是可以用Web.Page直接解析成数据表格?(但我这个期望数据的table标签外面还有个table,似乎是表中表,该怎么取里层的?)望老师不吝赐教,真诚先谢过。
用Web.Page这样就可以解析成表格了吗?如果是下一步该如何操作深化,达到最终效果?



