本帖已被设为精华帖!
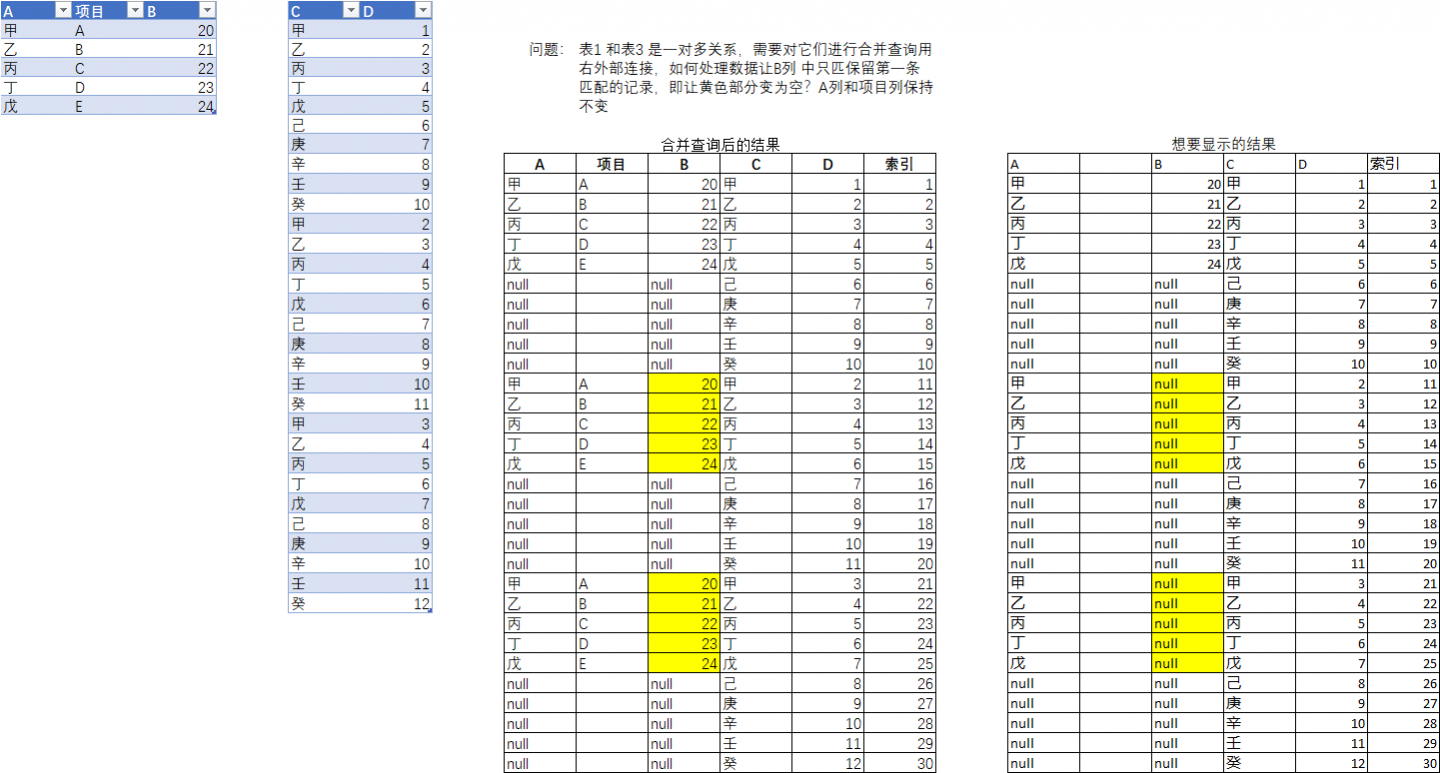
因为只需要保留第一次出现的数据,而源数据中并没有反映出现次数的列,所以首先得添加次数列,可参考 《模拟绝对引用累计计数》 。
合并查询时,将次数列添加到合并条件中,因为表 1 中的值都是第一次出现,这样表 2 中只有第一次出现的行才会匹配到表 1 中的数据,后面出现的就不会匹配到了 。
共 3 个查询:
// 表1
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
分组 = Table.Group(源, {"A"}, {"a", each Table.AddIndexColumn(_,"times")}),
展开 = Table.ExpandTableColumn(分组, "a", {"B", "times"})
in
展开
// 表2
let
源 = Excel.CurrentWorkbook(){[Name="表2"]}[Content],
索引 = Table.AddIndexColumn(源, "索引"),
分组 = Table.Group(索引, {"C"}, {"a", each Table.AddIndexColumn(_,"times")}),
展开 = Table.ExpandTableColumn(分组, "a", {"D", "索引", "times"})
in
展开
// 结果
let
源 = Table.NestedJoin(表1,{"A", "times"},表2,{"C", "times"},"表1",JoinKind.RightOuter),
展开 = Table.ExpandTableColumn(源, "表1", {"C", "D", "索引"}, {"C", "D", "索引"}),
排序 = Table.Sort(展开,{"索引"})
in
排序因为只需要保留第一次出现的数据,而源数据中并没有反映出现次数的列,所以首先得添加次数列,可参考 《模拟绝对引用累计计数》 。
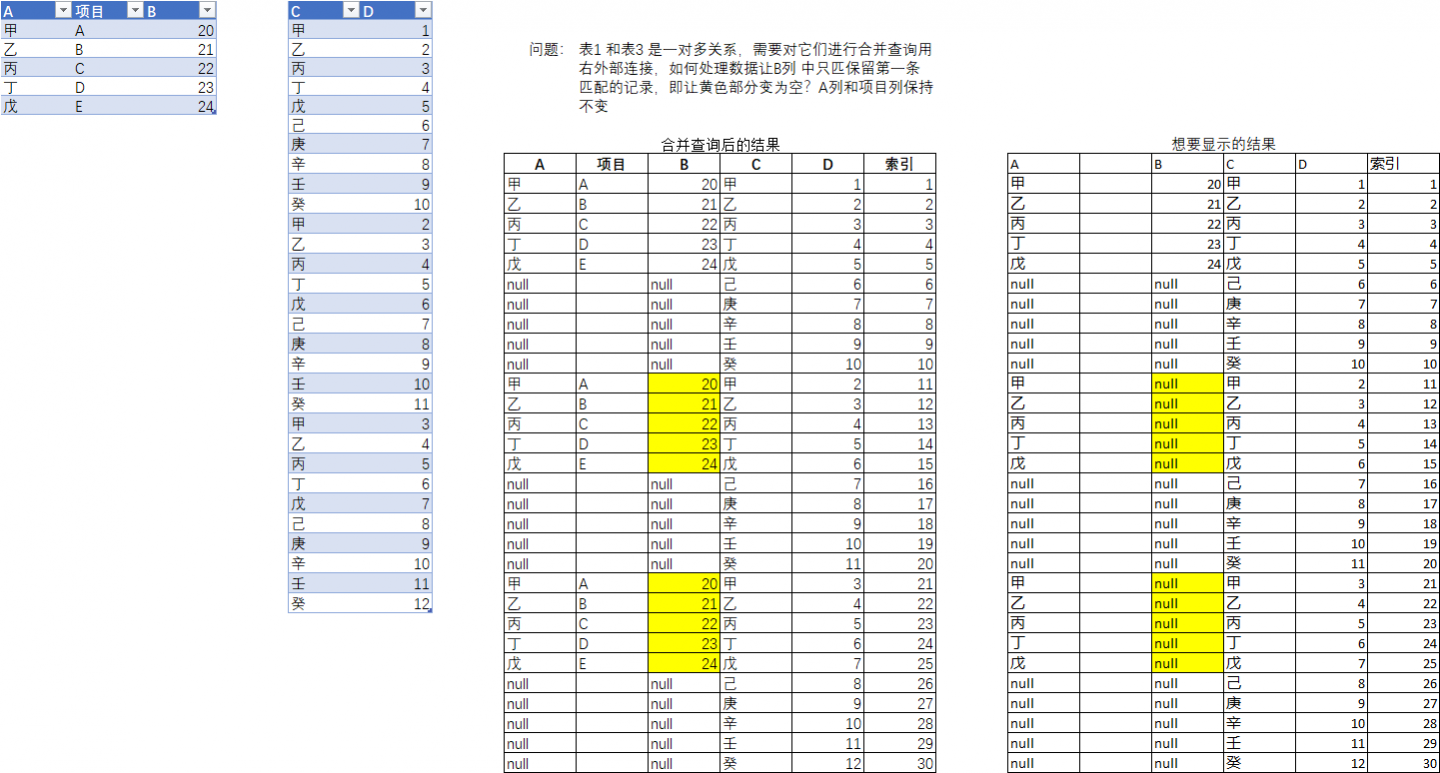
合并查询时,将次数列添加到合并条件中,因为表 1 中的值都是第一次出现,这样表 2 中只有第一次出现的行才会匹配到表 1 中的数据,后面出现的就不会匹配到了 。
共 3 个查询:
// 表1
let
源 = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
分组 = Table.Group(源, {"A"}, {"a", each Table.AddIndexColumn(_,"times")}),
展开 = Table.ExpandTableColumn(分组, "a", {"B", "times"})
in
展开
// 表2
let
源 = Excel.CurrentWorkbook(){[Name="表2"]}[Content],
索引 = Table.AddIndexColumn(源, "索引"),
分组 = Table.Group(索引, {"C"}, {"a", each Table.AddIndexColumn(_,"times")}),
展开 = Table.ExpandTableColumn(分组, "a", {"D", "索引", "times"})
in
展开
// 结果
let
源 = Table.NestedJoin(表1,{"A", "times"},表2,{"C", "times"},"表1",JoinKind.RightOuter),
展开 = Table.ExpandTableColumn(源, "表1", {"C", "D", "索引"}, {"C", "D", "索引"}),
排序 = Table.Sort(展开,{"索引"})
in
排序
