关于模糊筛选问题
看到雷公子以前写了一个模糊匹配速度优化的帖子,这里再从学习的角度写点基础用法:
https://pbihub.cn/blog/46
假设我有个比较大的数据集表放在csv文件中,想要按某个列进行模糊筛选:
比如我现在要筛选姓名中包含“王”字的所有记录,pq的代码是:
Table.SelectRows(表,each Text.Contains([姓名],"王"))而pbi中使用python脚本的解法是:
Python.Execute("r=x[x['姓名'].str.contains('王')]",[x=表])或者
Python.Execute("r=x[x['姓名'].str.contains(r'.*王.*')]",[x=表])
如果是不包含王字写为:
Python.Execute("r=x[~x['姓名'].str.contains('王')]",[x=表])如果对列进行模糊筛选,在pq中写为:
List.Select(表[姓名],each Text.Contains(_,"王"))或者
List.Accumulate(表[姓名],{},(x,y)=>x&(if Text.Contains(y,"王") then {y} else {}))但是List.Accumulate在大列表迭代时往往会产生如下内存溢出风险: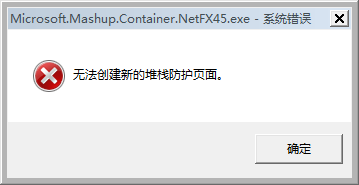
如果要获取满足条件的列表对象python可以写为:
Python.Execute("匹配=pandas.DataFrame([m for m in x['姓名'] if m.find('王')!=-1])",[x=表])如果仅仅只要取得满足条件的位置:
Python.Execute("索引=pandas.DataFrame([i for i,m in enumerate(x['姓名']) if m.find('王')!=-1])",[x=表])上面是最基础的单字符或连续字符模糊匹配,如果我们遇到逐字模糊匹配的情形怎么办?
例如:我要根据指定的简称匹配表中全称列中满足的记录(北大匹配北京大学),pbi中的python是这样处理的
Python.Execute("import re
正则逐字模糊匹配=pandas.DataFrame([i for i in x['全称'] if re.compile('.*'.join('北大')).search(i)])",[x=表])pq本身目前未开发内置的正则匹配相关的函数,但是我们也可以使用一些非常规手段处理:
pq中用js脚本的暗门就是Web.Page函数,该函数用来解析html结构内容,我们知道js脚本是可以直接嵌入html中的,如果js在html中输出有内容,我们就可以直接解析html从而获取js运行输出在html中的数据。
Web.Page("<script>document.write('hello畅心012中国123数学138'.match(/\d+/g));
</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}这里不再细说,看施阳的分享:
在Power Query中使用VB/JavaScript | Power Query爱好者 https://pqfans.com/2645.html
我们用"北大"来匹配"北京大学"可以写为:
Web.Page("<script>document.write(RegExp('.*'+'北大'.split('').join('.*')+'.*').test('北京大学'));
</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}此时返回二者是否满足逐字符的模糊匹配关系
如果是整列取模糊筛选匹配对象:
我们可以换一个思路,首先将整列字符串按换行符"\n"合并,然后用正则的按行匹配模式匹配字符串: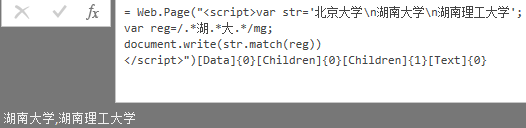
当然这里直接全局检索匹配也没问题。
我们还可以使用odbc或是oledb接口借用sql语句实现模糊匹配功能,将其中的查询参数改为如下形式即可:
select * from [表$] where 全称列 like " & "'%"&Text.Combine(Text.ToList("简称字符串对象"),"%")&"%'"关于匹配再介绍一个python好用的库flashtext:
在我们做分词应用的时候统计对象出现次数,首先得获取每个匹配对象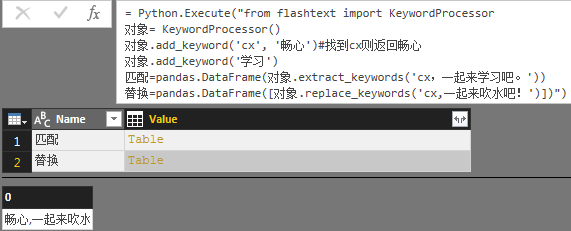
.add_keywords_from_list方法可以一次加入多关键字。
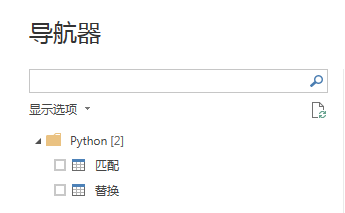
同时这里有个小发现:当我们使用界面操作从其它类的python脚本方式获取数据,如果我们的脚本框内代码指定了多个输出dataframe,那么此时的导航器会为我们返回原生的查询,多个dataframe构建的查询可以同时分别存在于不同查询存储,这貌似就是很多人问过的"拆分query"问题。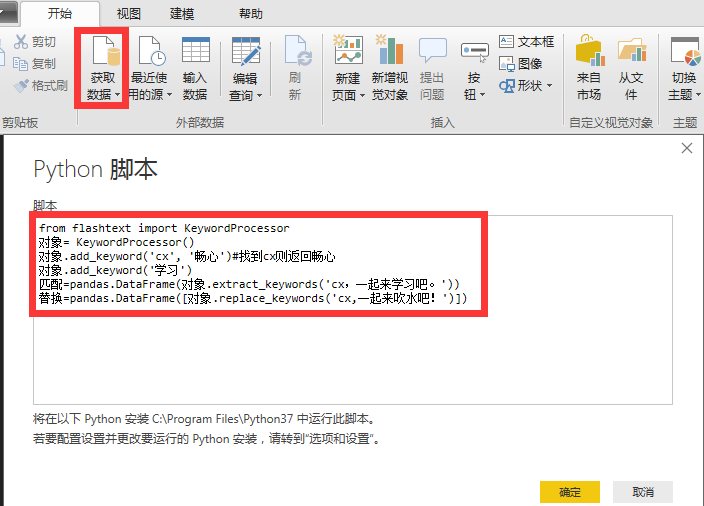
未完待续......
关于缓存提速的理解
转出数据库的提速策略


道高一尺 魔高一丈
https://pbihub.cn/users/44

自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)