
银保监会非现场监管报表报送日历
1. 必要性与复杂性
对于银行业金融机构财务统计与合规工作人员来说,银保监会非现场监管报表(1104报表)不仅难度高,而且数量大批次多。做好监管报送工作的第一步就是根据要求制定监管报送计划,以降低迟报漏报的概率。
不过政府监管部门通知并未按照数据库格式要求设计结构化,日常工作中一般按照由报送部门人工控制,但迟报与漏报可能将导致通报批评与处罚等严厉后果。
本文旨在说明如何使用Power BI通过M函数导入、清洗、转换文本型数据,然后通过DAX函数将文本型数据整理为度量值,以规范化的矩阵形式发布到网络。
为简化起见,笔者排除了一些数据,只挑选出机构类别之中数量占大多数的股份制商业银行、城市商业银行、民营银行、外资法人银行与外国银行分行,省略了大型银行、政策性银行、涉农金融机构以及各种非银行金融机构等。而且具体报表以报告日为2019年各月末要求为准,对报告期为2018年12月31日,上报日在2019年的报表不做处理。
2. M函数清洗数据
在数据处理部分,笔者以银保监会通知附件中Excel文件为数据源(少量修改其中一些疑似笔误和为一处批次加以限定性修饰),再加上日期参数表,机构类型参数表,频率批次参数表作为输入数据。
2.1 数据源简介
目前银保监会发布的通知之中与上报时间和报表有关的一共有三组,五个文件,具体格式见Power BI报告之中的“规范-1时间与频率批次”与“规范-2适用机构”,详细描述如下:
1. 报表适用范围:行标签与“口径及频度时间要求”几乎相同(除个别疑似笔误之外),按每一张报表列明适用的机构类型(大型银行、股份制银行、城商行、外资行…)。
这一部分包含全部报表,但是不同类型的金融机构只适用一其中部分,需要识别出适用报表,排除不适用部分。
2. 口径及频度要求:按每一张报表名称列明频率(月、季、半年、年)与报告日后需上报天数(6日、13日、18日、40日),还分成基础类、业务类、支持发展类报表,以及机构类报表两组。但是没有标注批次,只能够根据上报天数判断是第几批次,而且报表编号有重复(例如有多张G01报表附注),还必须结合报表名称才可以作为唯一标志。
这一部分包含全部报表,但是不同类型的金融机构只适用一其中部分,需要识别出适用报表,排除不适用部分。
3. 上报与审核时间表:按每月具体日期列明报表频率(月、季、半年、年)、批次(第一批、第二批)。
这一张表适用于所有类型机构。但是最底层粒度只到报表批次,没有具体列明批次的每一张报表,而且上报时间随周末与节假日调整,并未固定在期后某一日或星期几。
2.2 数据清洗转换
为了适应读者阅读习惯,监管部门通知中使用了大量的合并单元格,报表没有唯一编号,报表批次、频率和适用的机构类型没有统一编码,且手工输入文字中有多处换行符和空格,适用范围以二维表展现,这些都需要使用Power Query清洗处理。
导入数据后,处理步骤主要有删除不需要的列、删除空行、提升标题、拆分列、合并列,删除非打印字符、逆透视、合并查询等。
2.2.1 报表适用机构范围转一维表
本步骤目标是将原先不适用电脑自动化处理的机构类型列转行,与报表名称形成适合批量自动化处理的笛卡尔积。
图表 1 适用机构类型转一维表代码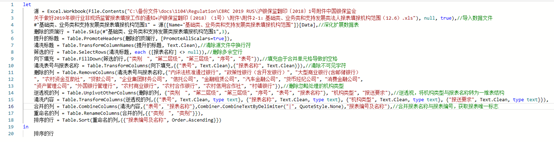
图表 2 适用机构类型转换后样式
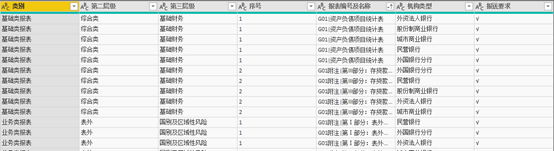
2.2.2 报表口径及频度要求匹配适用机构
这一步骤目标是将数据源之中已知各种报表的频度,根据其编号与名称与上一步骤中获取的适用机构类型一维表相匹配,即合并查询,最后得到各机构类型每一张报表的频率与报告期后上报天数。但是,这里的上报天数只有参考意义,只能够用于计算报表批次(如月报第一批、季报第二批…),实际上报天数应该以银保监会附件为准,因为银保监会将因规避周六日和节假日而调整上报天数。
以上报表批次将最终存为符号,如M,Q, H, Y; 1,2,3;分别代表各个频率的各个批次。
此处代码与转换效果从略。
2.2.3 转换上报与审核时间表
本步骤主要难点在于报表批次并未细化到具体报表,而且不同机构类型适用的报表并不相同,除了常规的2019年一批、二批、三批之外,还有2018数据按新格式补报批次,而且月报与季报、半年报、年报分别处于规范之中的两栏,此外源文件单元格之中以换行符分隔的报表批次,而非将其处于两行。
所以本步骤主要过程是拆分行,合并月报与其他频率报表两列,然后将官方文件之中的报表批次与报表编号和机构类型相匹配,最后形成规范的一维表,最细粒度为每一种机构类型适用的每一张报表按每月末展开。
主要步骤:
- 合并“月报”与“季报、半年报、年报”两栏,
= Table.CombineColumns(提升标题,{"报表批次", "Column3"},Combiner.CombineTextByDelimiter(",", QuoteStyle.None),"已合并")
两列合并一列之后,后续步骤更加简单。使用原先文本之中已有的中文逗号“,”作为合并符号,可以在下一步Text.SplitAny语句之中省去一个分隔符。 - 使用多个字符拆分以上合并列
= Table.AddColumn(合并批次, "合并批次", each Text.SplitAny(_[已合并],",补#(lf) "))
图表 3 Text.SplitAny新增列嵌套结构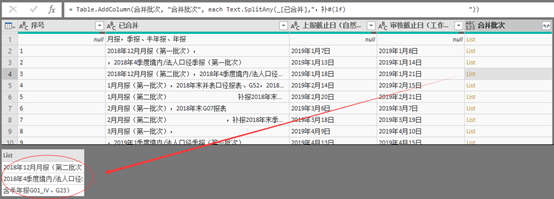
以上Text.SplitAny语句使用了中文逗号“,”、汉字“补”、换行符“#(lf)”以及连续多个空格“ ”都被作为分隔符,即只要[已合并]这一列文本之中有上述字符,都将被分拆。而分拆后的内容以list形式单独存为一个新增列,展开后最终是各个报表批次和空格,并且后续展开list后,原先的上报截止日也将复制到各行。
- 将汉字频率批次转为标准符号
通过检查文字描述之中是否存在“月”、“季”,“第一批”、“第二批”等,分别添加M,Q; 1,2,3等符号,用以匹配前两个步骤之中整理得出的报表批次与具体报表。这样可以根据官方调整后的上报时间控制筛选各机构的每一类或每一张报表。
3. DAX函数发布展示
3.1 数据模型结构
经过以上Power Query M函数整理之后,得到两张数据表,上报及审核控制表2019与合并报表清单2019,与此前加入的三张参数表,即日历表、银行类型与频率批次,共同构成DAX数据模型。
需要注意的是,本文中数据模型虽然简单,但实际是两组,并非传统的以单一事实表为核心的星型模型或者雪花模型。这主要是由于上报及审核控制表2019与合并报表清单2019二者各自报表频率批次(月报一批、季报二批等)都多次在表内重复,不可以建立简单的一对多关系。笔者为简化起见,设置了以红线分隔的两个子模型分析展示2019年度报表审核与上报情况以及各批次明细,而忽略2018当年月报一批、二批,季报一批、二批等报表批次。
图表 4 DAX数据模型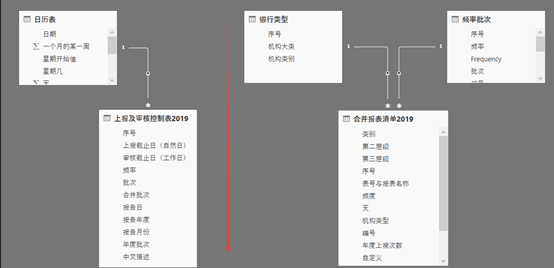
图表 5 上报及审核控制表2019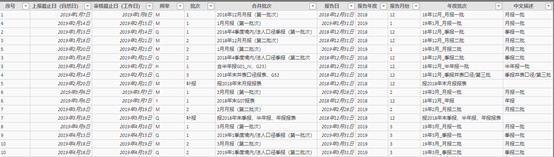
图表 6 合并报表清单2019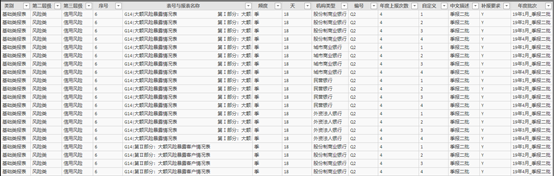
3.2 DAX函数度量值公式
基于明细数据源设置以上数据模型之后,还需要使用DAX函数聚合展示,以及设计切片器方便用户查看。
3.2.1 合并展示报表批次
以下度量值[报表批次]的含义是以换行符UNICHAR(10)为连接符号,合并符合筛选条件的'上报及审核控制表2019'[年度批次]所包含的各个文本,CONCATENATEX意即连接合并文本。
报表批次 = CONCATENATEX('上报及审核控制表2019','上报及审核控制表2019'[年度批次],UNICHAR(10))
3.2.2 报表不重复计数
报表不重复计数 = DISTINCTCOUNT('合并报表清单2019'[表号与报表名称])
这一度量值是为了统计不重复监管报表数量,比如按照季度或月度等时间维度筛选时,如果不同金融机构类型需要报送的报表有重复,那么DISTINCTCOUNT将去除重复后计数。
3.3 网络版查看
本报告发布到网络之后,读者可以自行筛选查看。例如如果希望查看一月、四月、七月、十月有哪些季报需要报送,那么按住Ctrl键,然后打钩选取相应的月份,以及频率标志“Q”即可,效果如下图。
图表 7 网络版报表查看
最终展示效果:
电脑或手机横屏效果更佳
http://u6.gg/hgU9x
银行业Excel商务智能实践者
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
