M+R
很早以前分享过R结合PQ的应用,总感觉不过瘾,大家想尝试的,首先可以参考官方相关文档进行相关配置:
在 Power BI Desktop 中运行 R 脚本 - Power BI | Microsoft Docs https://docs.microsoft.com/zh-cn/power-bi/desktop-r-scripts
R语言作为统计学中的重型武器与我们的数据清洗有着莫大关联,另外R的可视化往往也让我欣喜,所以它是本人学习M语言绕不过去的一个扩展。。。
有人曾经将R的引入比喻为在PowerBI中安装了一把瑞士军刀。
R.Execute() the Swiss Army knife of Power Query | Query Power ? https://querypower.com/2017/03/11/r-execute-the-swiss-army-knife-of-power-query/
提几个点:
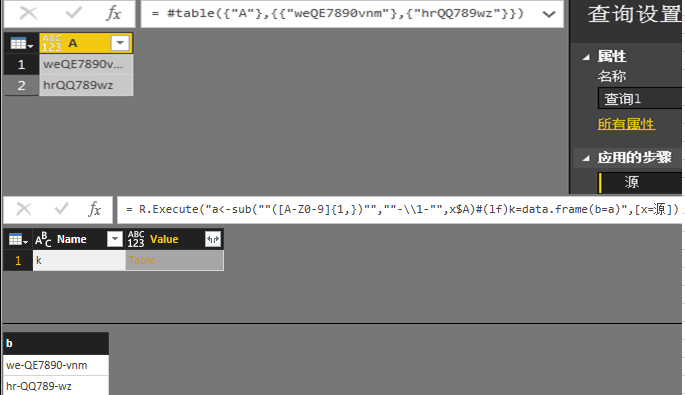
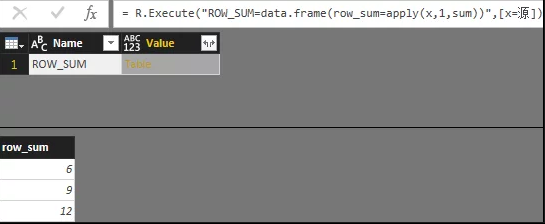
1.在PowerBI中使用R语言脚本,函数为R.Execute
该函数有两个参数,第一参数为脚本字符串,第二参数为交互传递的记录参数(对于Python.Execute差不多);
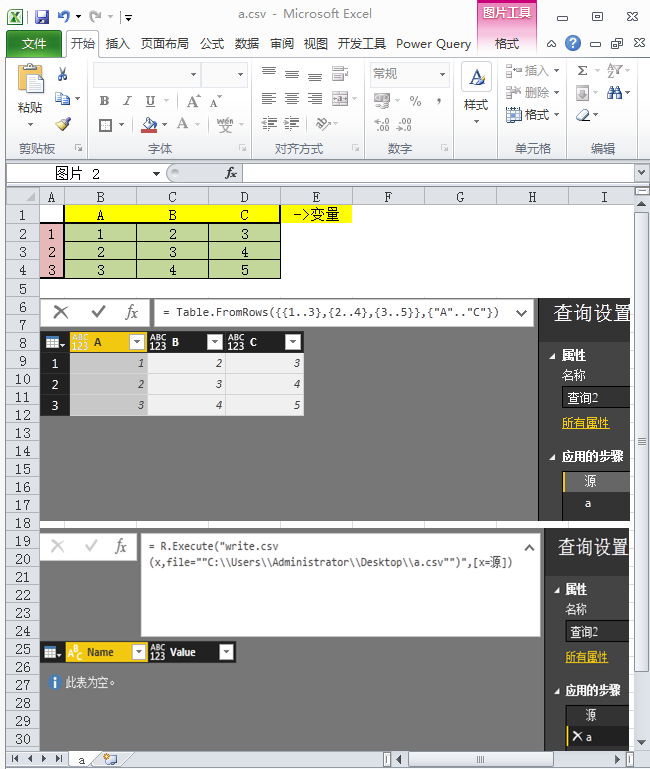
2.与Python.Execute类似,R脚本的数据在M环境中的输出需要依靠dataframe结构展现;
3.作为脚本语言当然可以进行其它对象的操作;
4.变量的交互传递,可以使用字符串重组为脚本字符串的方式调用M环境中的变量,或者依靠第二参数传递,注意第二参数记录中需要传递表变量。
5.和python类似那么多扩展包,你尽管用啊,掉头发我一概不负责。。。。。。
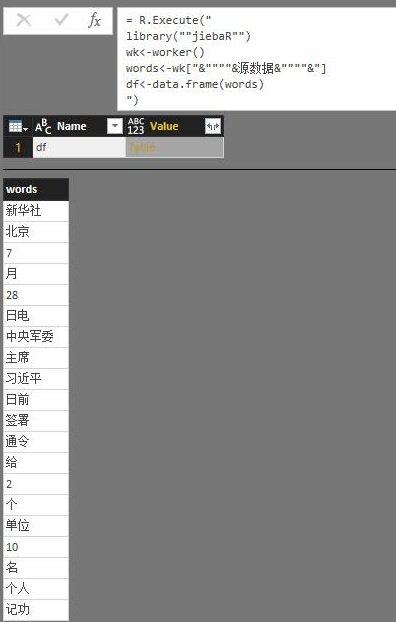
对比python,以前我用pip安装包方式、现在R直接install.packages('包名字'),选择相应镜像连接会自动下载,当我们关闭R后下次使用不必再次下载包,直接用library加载使用即可。
使用时直接library(包名字),进行加载就可以使用包内封装好的函数了(不要单引号)。
R中定义的方式(不是用等号):名称<-表达式
注意严格区分大小写
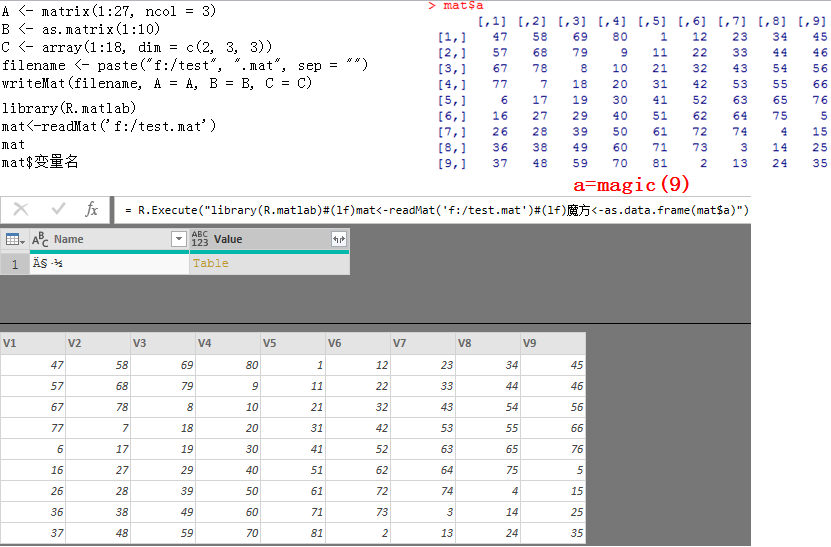
说明:本人win7的64位系统,安装的64位R版本为3.5.1,同时本人安装了Rtools和RStudio(我要调用C++)。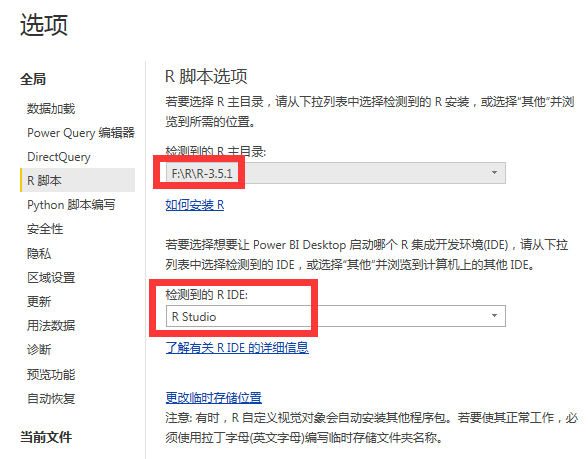
我没有默认将R安装在C盘,而是放在F盘的R文件夹下(默认路径有空格调用Rcpp包时报错)
首先本人在F盘中写入如下fibcpp.cpp文件(C++里面自定义一个生成斐波那契数列数据的函数)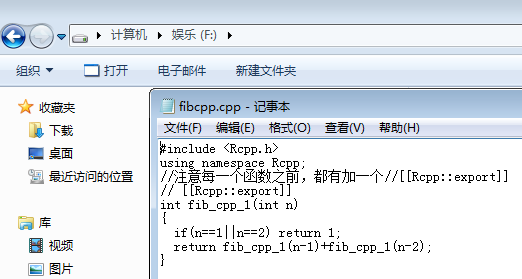
然后在PowerBI中使用R脚本方式生成数据
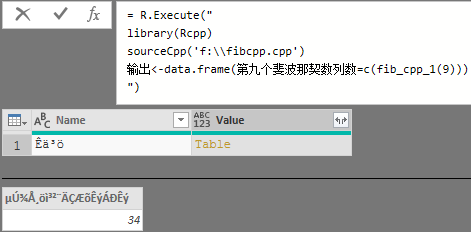
可能你的会提示找不到Rcpp包,没错和Python类似你得先安装
在R中输入如下代码
install.packages('Rcpp')
按照弹出窗口选择一个安装源路径就好(我就选了第一个)
装好后关闭R,再回到这里刷新应该就没问题了。
注意和Python类似需要将R添加到系统环境变量中去。。。
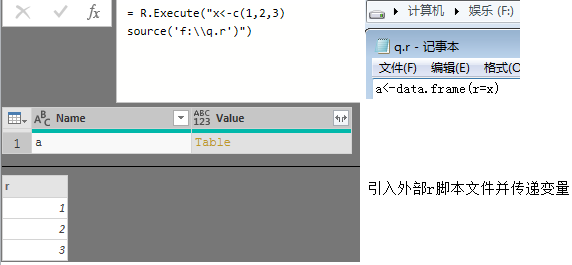
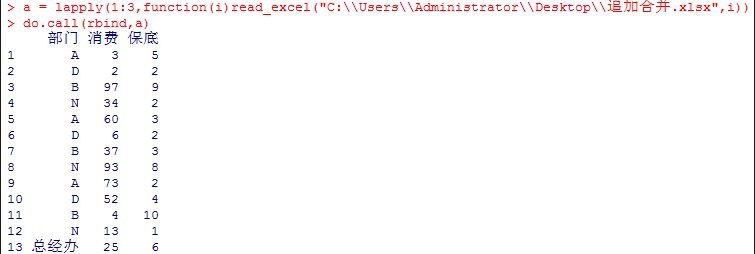
我们可以将做好的自定义函数放到本地脚本文件中,利用函数source("filename")方式读取脚本文件从而使用相关自定义函数。
不好意思第一个就上了M+R+C++
下面回过头来讲基础
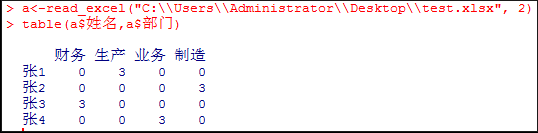
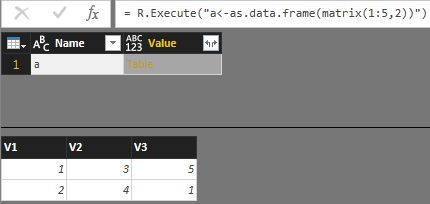
数据框(Data frame)数据框可以由函数read.table()、read.csv()读取一个文本文件,返回的也是一个Data Frame对象。读取数据库也是返回Data Frame对象;这里也可以用函数data.frame来创建。数据框中的向量必须有相同的长度,如果其中有一个比其它的短,它将“循环”整数次(以使得其长度与其它向量相同):
> x <- 1:4; n <- 10; M <- c(10, 35)
> data.frame(x, n)
x n
1 1 10
2 2 10
3 3 10
4 4 10
> data.frame(x, M)
x M
1 1 10
2 2 35
3 3 10
4 4 35数据框可以用data.frame()函数生成,如果一个列表的各个成分满足数据框成分的要求,它可以用as.data.frame()函数强制转换为数据框。
数据框的基本操作:
访问元素
与Matrix一样,使用[行索引,列索引]的格式可以访问具体的元素。
比如访问第一行:df[1,]
访问第二列:df[,2]
访问前两列:df[1:2]或者df[c("列1","列2”)]
如果是只访问某一列,返回的是Vector类型的可以使用:df[[2]]、df[[“第2列”]]、df$第2列
修改数据类型
df$列<-as.character(df$列)
df$列<-as.as.Date(df$列)
筛选
df[which(df$列1=="值"),]
df[which(df$列1=="F值"),"列2”]
subset(df,列1=="值" & 列2<数值 ,select=c("返回列a","返回列b"))
sql操作数据框:
library(sqldf)
result<-sqldf("select 字段1,字段2 from 表 where 筛选条件设置")连接与合并
merge(df1,df2,by.x="df1关键字",by.y="df2关键字")
merge(df1,df2,by="关键字")
rbind(df1,df2)
列的命名
colnames(df)=c('列1','列2','列3')
添加自定义列、行
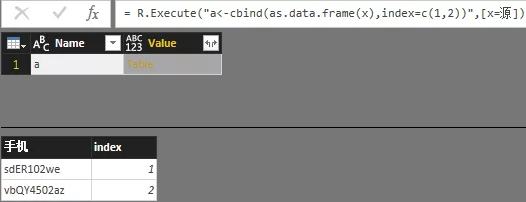
df$新列=列1/列2
y<-1:4
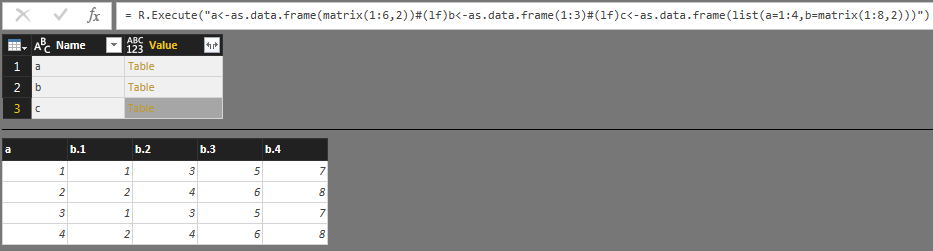
df2<- cbind(df1[,1:2],y,df1[,3:ncol(df1)])row<- c(1, 1, 1)
df2 <- rbind(df1[1:5,], row, df1[6:nrow(df1), ])数据框的排序
df[order(df$列1, -df$列2),]
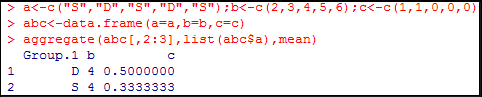
分类汇总
循环
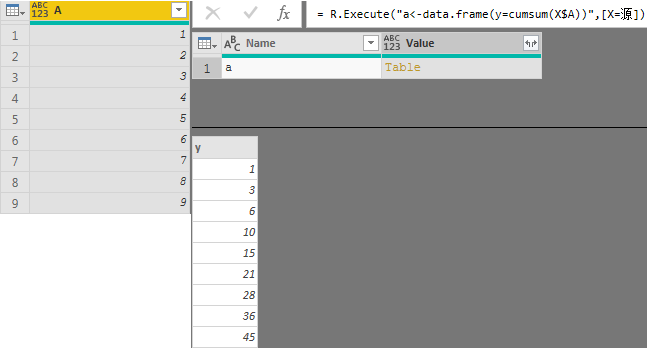
x <- c(1,1)
for (i in 3:30) {
x[i] <- x[i-1]+x[i-2]
}x <- c(1,1)
i <- 3
while (i <= 30) {
x[i] <- x[i-1]+x[i-2]
i <- i +1
}for(i in seq(from=1,to=100,by=1)) x=x+i
x
x <- foreach(i=1:5) %do% i^2
x
> gcd <- function(a,b) {
+ if (b == 0) return(a)
+ else return(gcd(b, a %% b))
+ }条件分支语句
if (条件判断){
输出真条件返回值
} else {
输出假条件结果返回值
}自定义函数
fx <- function(参数集定义){
statements
return(返回对象)
}其实你都不用看那些乱七八糟的,有想法就问百度吧,相信你的基础问题都已经有答案了。
读取大数据集,可以先查看前面几行的数据情况进行选择加载
read.table('f:\\test2.csv',nrows=5,sep=',')那么面对千万行数据的读取(仅读取第一和第三列):
a<-read.table('f:\\test2.csv',nrows=5,sep=',')
typed<-sapply(a,class)
typed[c(-1,-3)]<-rep('NULL',length(typed)-2)
data<-read.table('f:\\test2.csv',sep=',',colClasses=typed)rio包
library(rio)
a<-import('f:\\test2.csv')
library(rio)
a<-import('C:\\Users\\Administrator\\Desktop\\excel.xlsx')
library(rio)
a<-import('C:/Users/Administrator/Desktop/压缩包内容.zip')
#还能读取JSON文件及数据类型转换
library(rio)
library(xml2)
a<-import('C:/Users/Administrator/Desktop/压缩包内容.zip')
export(a,'f:\\a.html')关于R相关操作可以参考张丹的介绍:
https://blog.csdn.net/kMD8d5R/article/details/81741192
R语言中的apply函数族:http://blog.fens.me/r-apply/
回到数据框,有个包也是不得不看:
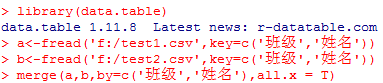
R之data.table速查手册 - Little_Rookie - 博客园 http://www.cnblogs.com/nxld/p/6059570.html






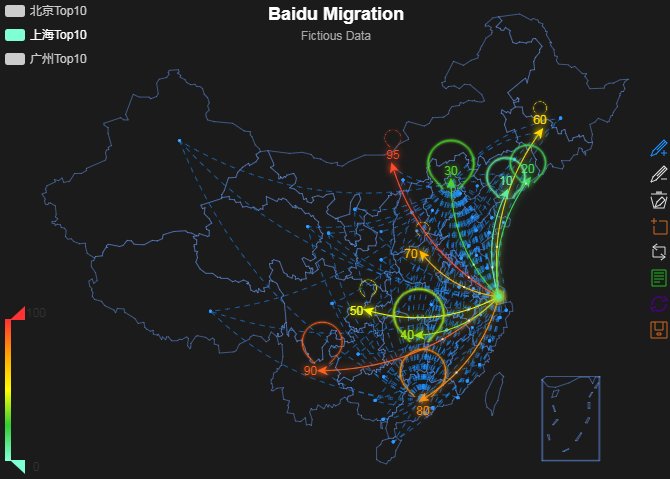



最后我吐槽以下百度迁徙图,费尽千辛万苦实现的过程:
首先安装devtools包并加载;然后采用本地安装Remap;
GitHub - Lchiffon/REmap: create a map by R https://github.com/lchiffon/REmap
下载REmap-master并解压,打开里面的REmap.Rproj文件;
在Rstudio中进行如下操作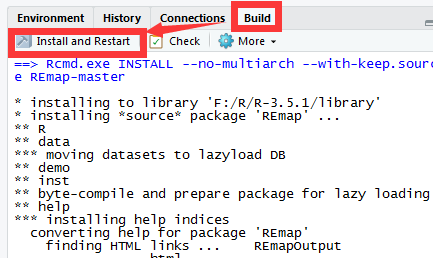
有可能会提示你的附属包对当前Remap包不合适,需要安装。
本人当初提示XML和rjson两个包有问题,install.packages('分别安装这两个包')
装好后再次Install and Restart操作
library(devtools)
library(REmap)
a<-data.frame(起点=c('佛山','佛山','佛山'),终点=c('长沙','无锡','北京'))
地图<-remap(mapdata = a,title ='百度迁徙图',subtitle = '佛山数据',theme = get_theme(theme = 'Dark'))
plot(地图)提示:请使用Chrome或者Firefox来作为默认浏览器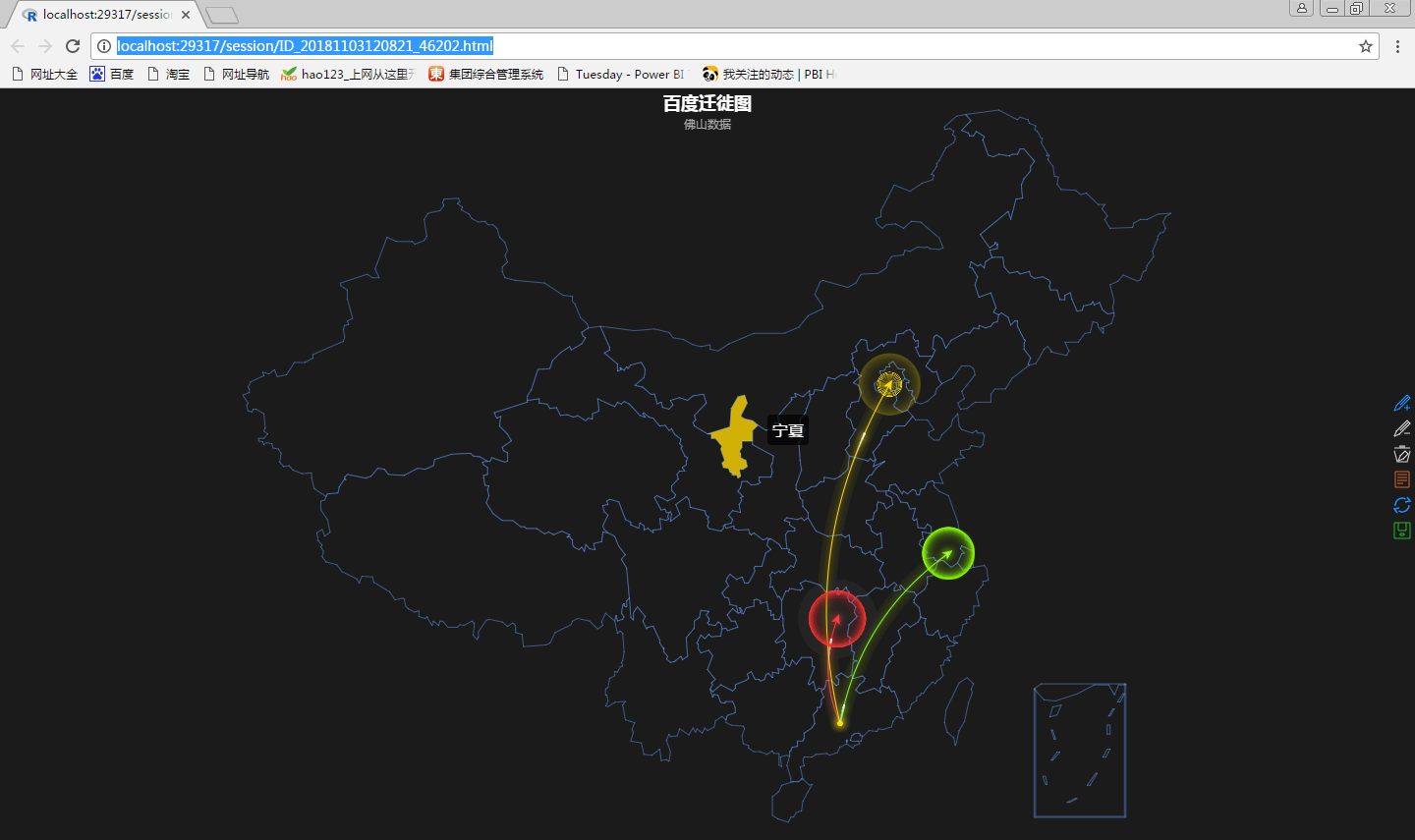

说明:在R或RStudio中会单独输出一个html临时文件显示动态地图,但是在PowerBI中无法找到临时文件,我猜想可能是调用百度API时间问题,不够生成地图时间......
主题设置参考如下:
关于可视化图表,可以看下echarts图标库
recharts: 百度ECharts 2的R语言接口 http://madlogos.github.io/recharts/index_cn.html#-en
但是最新版的R貌似没有合适的recharts安装包版本......
用R语言绘制动态地图,代码奉上!(REmap包详解) - 小游老师 - CSDN博客 https://blog.csdn.net/u013524655/article/details/72812181
听说JAVA也保不住了
道高一尺 魔高一丈
https://pbihub.cn/users/44

自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)