
DAX 中的行上下文可视化解释
本文翻译自Marco Russo&Alberto Ferrari的文章—《Row context in DAX explained visually》来源:SQLBI 本文使用基于视觉表示的概念模型来描述DAX中的行上下文。
行上下文是编写DAX代码中的第二个基本概念。在之前的文章中,我们使用视觉方法介绍了第一个概念——筛选上下文。在本文中,我们将依赖图形来描述行上下文。
列引用需要行上下文
在DAX表达式中,当你引用列时,你需要一个行上下文来评估该表达式。例如,考虑以下DAX表达式:
Sales[Quantity]*Sales[Net Price]
该公式将“销售”表中的“数量”乘以“净价”。更具体地说,该公式执行以下步骤:
1.它获取“销售”表中当前行的“数量”列的值。
2.它获取“销售”表中当前行的“净价”列的值。
3.它将前两步中获得的两个值相乘。
每个列引用都需要评估一个“当前行”。但是,“当前行”是什么意思呢?嗯,我们用“当前行”这个一般性的说法来识别一个与DAX非常特定的概念:行上下文。
行上下文标识表的一行。例如,请考虑以下销售表。

我们可以通过高亮显示第二行来表示销售表的第二行的行上下文。)
但是,我们也可以使用只有一行的表来表示行上下文,即行上下文所指向的行。

这种表示法特别有助于描述上下文转换,这是未来文章中的一个主题。
如何获取行上下文
在DAX中,可以通过使用迭代器函数遍历表来获取行上下文。在DAX指南中,每个遍历表的函数都会为遍历的表提供一个迭代器标签,并为每个在遍历表上执行行上下文的DAX表达式的参数提供一个行上下文标签。例如,ADDCOLUMNS的第一个参数是遍历的表,而对于遍历表的每一行,都可以在行上下文中评估一个或多个表达式。
你可以在DAX指南中筛选“迭代器”组,以获取所有迭代器的列表。
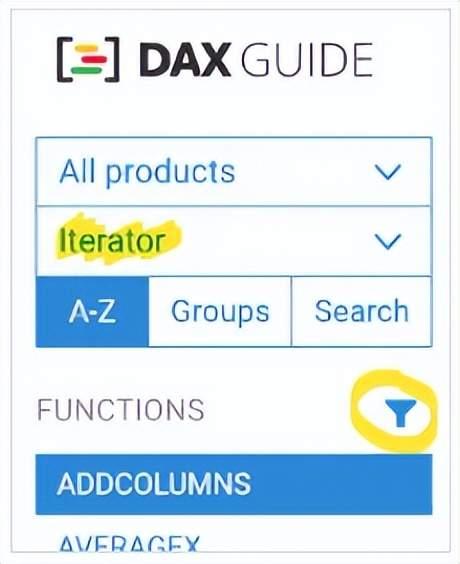
因此,迭代器总是逐行扫描表。尽管我们的表达式只使用了几列,但行上下文始终提供对整个行的访问。
虽然引擎可能会优化执行,只考虑DAX表达式中引用的列,但从概念上讲,我们可以访问迭代表的所有列。然而,行上下文没有物化成本,因为它只表示表中的一个位置。同样,我们可以用一个包含原始表所有列但只有一行的表来表示行上下文,但这个表不会复制任何数据——它只是一个概念模型,使DAX的工作原理更容易解释。
计算列是迭代器的一个特例。当模型刷新时,引擎会为表中的每一行执行计算列的表达式,并将其结果存储在单独的列中。与通过筛选上下文可见的行进行迭代的迭代器不同,计算列是在空的筛选上下文中进行评估的,因此它们总是遍历表中的所有行。
筛选上下文用于筛选,而行上下文用于迭代
当你执行一个DAX表达式时,通常同时涉及到筛选上下文和行上下文。例如,考虑以下Sales Amount(销售额)度量的定义:
销售表中的度量值
Sales Amount =
SUMX (
Sales,
Sales[Quantity] * Sales[Net Price]
)
SUMX是DAX中的一个迭代器,它会为第一个参数中的表的每一行执行第二个参数。我们说SUMX遍历了第一个参数中指定的表表达式。筛选上下文会筛选该表表达式。我们可以使用的最简单的表表达式仅仅是Sales(销售)表的引用。在DAX中,表引用始终受到筛选上下文的筛选,因此SUMX会遍历在筛选上下文中可见的Sales表中的行。例如,当我们对2024年6月12日应用筛选器时,以下图表显示了此行为。
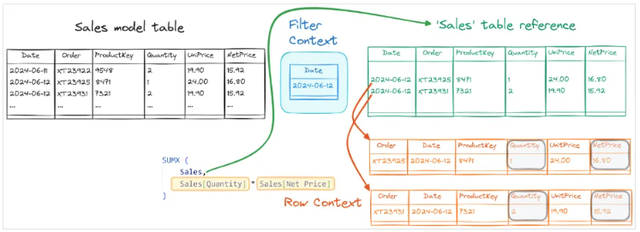
“Sales”这个名字被用来表示两个不同的概念:
在左侧,我们有语义模型中的Sales表。当我们谈论“模型表”时,我们考虑的是语义模型中带有所有行的物理表,忽略任何筛选。
在右侧,我们有Sales表的引用。在DAX中,表引用始终受到安全筛选器和筛选上下文的筛选。表引用就像是模型表上的一个“视图”,只返回“可见”的行。DAX不能覆盖安全筛选器,但可以通过使用CALCULATE和CALCULATETABLE添加和删除筛选器来操作筛选上下文。
SUMX表达式执行以下操作:
它在筛选上下文中评估第一个参数。
对于在(1)中获得的表中的每一行,它在相应的行上下文和相同的筛选上下文中评估第二个参数。
如果我们在第二个参数中仅使用列引用,则筛选上下文将不再相关。但是,如果我们有其他表达式,则这可能很重要。例如,以下度量值将每笔交易的金额除以由切片选择定义的数字:
销售表中的度量值
Sales Amount Scale A =
SUMX (
Sales,
DIVIDE (
Sales[Quantity] * Sales[Net Price],
SELECTEDVALUE ( Scale[Scale] )
)
)
SELECTEDVALUE函数返回“Scale”切片器上的当前选择,因为筛选上下文在该表达式中仍然有效。显示的代码并不理想,因为如果表达式不依赖于行上下文,它可能会在迭代器之前被评估,从而明确表明这种依赖关系不存在:
销售表中的度量值
Sales Amount Scale B =
VAR _Factor = SELECTEDVALUE ( Scale[Scale], 1 )
RETURN
SUMX (
Sales,
(Sales[Quantity] * Sales[Net Price]) / _Factor
)
在这个特定的情况下,除法应该在SUMX的外部进行。但是,我们只是想澄清,在迭代器的行上下文中评估的表达式中,筛选上下文仍然是可用的。我们使用这些最后的例子是为了教学目的。代码优化不是本文的目标。
表表达式定义了基数
行上下文会遍历迭代器函数提供的表表达式返回的所有行。因此,迭代的基数由表表达式定义。例如,考虑以下两个度量值:
销售表中的度量值
Sales Amount Projection =
VAR SalesProjection =
SELECTCOLUMNS (
Sales,
Sales[Quantity],
Sales[Net Price]
)
RETURN
SUMX (
SalesProjection,
Sales[Quantity] * Sales[Net Price]
)
销售表中的度量值
Sales Amount Grouped =
VAR SalesGrouped =
SUMMARIZE (
Sales,
Sales[Quantity],
Sales[Net Price]
)
RETURN
SUMX (
SalesGrouped,
Sales[Quantity] * Sales[Net Price]
)
“Sales Amount Projection”度量值返回与“Sales Amount”相同的结果,因为迭代的行数(基数)是相同的。实际上,尽管SalesProjection变量只有两列,但行数是一样的。从性能的角度来看,只要表没有被具体化,我们就不会为在内存中分配可能引用的未使用模型列而付出代价。但是,就本文而言,我们可以忽略这一点:重要的是SUMX的结果取决于迭代的行数,而这个数字是相同的。SELECTCOLUMNS函数不会改变迭代表的基数。
“Sales Amount Grouped”度量值返回不同的结果,因为它迭代了SUMMARIZE返回的Sales中Quantity和Net Price的唯一组合数。实际上,SUMMARIZE可以从第一个参数提供的表中返回更少的行数,这通常会导致结果基数更小。同样较小的基数解释了不同的结果。以下图片显示了两个度量值使用的SalesProjection和SalesGrouped变量的内容。
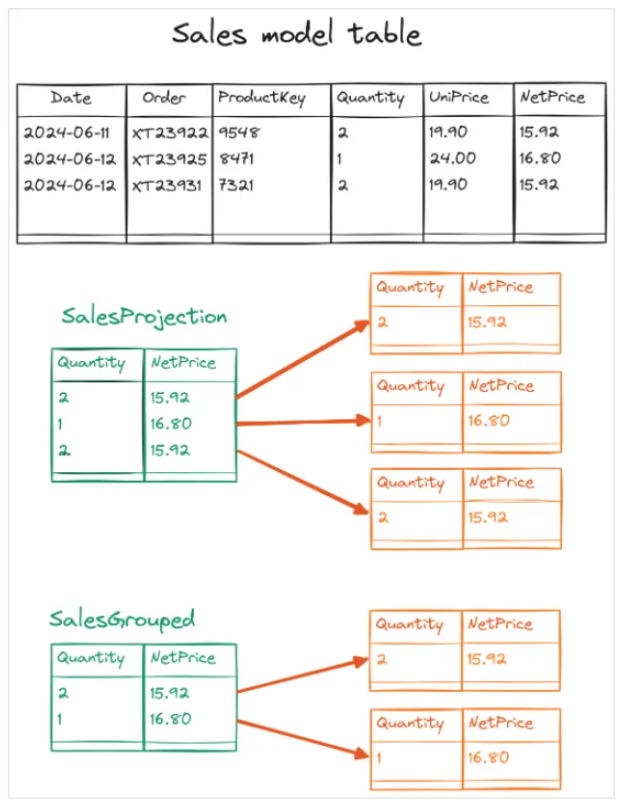
结论
行上下文可以通过在表中选择一行来直观地表示,或者将行表示为一个包含所有列和单行的表。在后续文章中讨论上下文转换时,后一种表示方法将非常有用。
迭代器获得行上下文,并通过迭代表达式控制迭代的基数。实际上,由于筛选上下文的存在,简单的表引用通常只显示模型中可用行的一个子集。以图形方式表示提供给迭代器的表表达式有助于理解迭代的基数和行上下文可用的列。
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


