二进制函数应用从一个 500M 的 CSV 文件中提取最后一行数据说起
一切有为法,如梦幻泡影,施主回头是岸,哈哈哈...
php
Table.LastN(
[fb=File.Contents("C:\Users\Administrator\Desktop\test2.csv"),
提取=Csv.Document(
BinaryFormat.Record([a=BinaryFormat.Binary(Binary.Length(fb)-666),畅心=BinaryFormat.Binary()])(fb)[畅心],
[Encoding=936])
][提取],1) //保险一点还是把Csv.Document的Columns参数带上,编码请根据自己的文件修改,-666是看你文件够大,别模拟几行数据不够减。或者
php
Table.LastN(
[fb=File.Contents("C:\Users\Administrator\Desktop\test2.csv"),
提取=Csv.Document(
Binary.Range(fb,Binary.Length(fb)-666),
[Encoding=936])
][提取],1)读取中间几行自己写写吧,,,
读取初始几行信息:
php
Table.PromoteHeaders(Table.FirstN(Csv.Document(BinaryFormat.Binary(666)(File.Contents("C:\Users\Administrator\Desktop\test2.csv")),[Encoding=936]),2))
//由于pq惰性计算,可能直接Table.FirstN(Csv.Document(File.Contents("")),2)更快!!!前段时间有人问过批量解析不同编码不同类别的文件的套路:
二进制类函数里面有个函数可以推断文件类型、编码及分隔符等信息。
php
Table.AddColumn(Folder.Files("C:\Users\Administrator\Desktop"),"推断二进制文件信息",
each Binary.InferContentType([Content])[Content.Encoding]?)unicode/utf16=1200
unicode big endian=1201
utf8=65001
windows=1252
ascii=20127
php
Csv.Document(
[a=Folder.Files("C:\Users\Admin\Desktop\test")[Content],
b=#binary(BinaryFormat.List(BinaryFormat.Byte, (x) => x <>10)(a{0})),
c=Binary.Length(b),
d=List.Transform(a,each Binary.Range(_,c)),
e=Binary.Combine({b}&d)
][e])表头(还是感觉不科学)







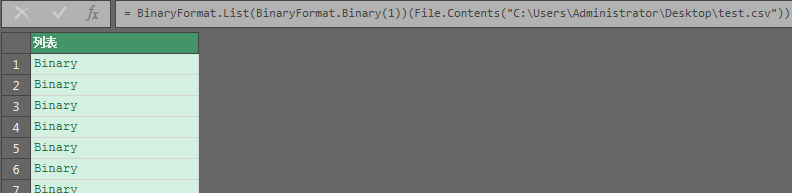

php
Csv.Document(Binary.FromList(BinaryFormat.List(BinaryFormat.Byte, (x) => x <>13)(二进制数据)))
Csv.Document(#binary(BinaryFormat.List(BinaryFormat.Byte, (x) => x <>10)(二进制数据)))
(x,y)=>BinaryFormat.List(BinaryFormat.Binary(x))(二进制数据){y} //总感觉差了一个条件式设置
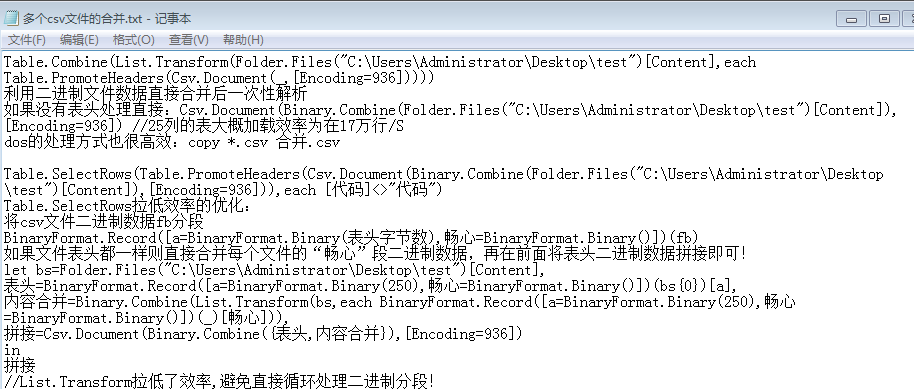
逐行读取流处理
php
let
源=[fb=File.Contents("C:\Users\Admin\Desktop\test.csv"),lchunk=#binary(BinaryFormat.List(BinaryFormat.Byte,(x)=>x<>10)(fb))],
提取第几行=Csv.Document(
List.Accumulate({1..18},源,(p,q)=>
[fb=BinaryFormat.Record([a=BinaryFormat.Binary(Binary.Length(p[lchunk])),畅心=BinaryFormat.Binary()])(p[fb])[畅心],lchunk=#binary(BinaryFormat.List(BinaryFormat.Byte,(x)=>x<>10)(fb))]
)[lchunk]) //18指代指定行
in
提取第几行或者
php
Csv.Document(
List.Accumulate({1..100},源,(p,q)=>
[fb=BinaryFormat.Record([a=BinaryFormat.Binary(p[lb]),b=BinaryFormat.Binary(Binary.Length(p[fb])-p[lb])])(p[fb])[b],lchunk=#binary(BinaryFormat.List(BinaryFormat.Byte,(x)=>x<>10)(fb)),lb=Binary.Length(lchunk)]
)[lchunk])
或者
php
let
源=[fb=File.Contents("C:\Users\Admin\Desktop\test.csv"),lchunk=#binary(BinaryFormat.List(BinaryFormat.Byte,(x)=>x<>10)(fb)),index=0],
逐行读取=List.Generate(()=>源,each [index]<18,
each [fb=BinaryFormat.Record([a=BinaryFormat.Binary(Binary.Length([lchunk])),畅心=BinaryFormat.Binary()])([fb])[畅心],lchunk=#binary(BinaryFormat.List(BinaryFormat.Byte,(x)=>x<>10)(fb)),index=[index]+1],
each Text.FromBinary([lchunk])) //index控制读取行数
in
逐行读取
/*
Binary.Combine(List.Generate(()=>源,each [index]<5,
each [fb=BinaryFormat.Record([a=BinaryFormat.Binary(Binary.Length([lchunk])),畅心=BinaryFormat.Binary()])([fb])[畅心],lchunk=#binary(BinaryFormat.List(BinaryFormat.Byte,(x)=>x<>10)(fb)),index=[index]+1],
each [lchunk]))
*/
计算行数:
php
List.Sum(BinaryFormat.Group(BinaryFormat.Byte,
{{13,BinaryFormat.Byte,BinaryOccurrence.Repeating,0,List.Count},
{10,BinaryFormat.Byte,BinaryOccurrence.Repeating,0,List.Count}
},each BinaryFormat.Byte
)(File.Contents("F:\test2.csv"))) //这速度有点慢了
或者
List.Sum(BinaryFormat.Group(BinaryFormat.Byte,
{{13,BinaryFormat.Byte,2,0,List.Count},
{10,BinaryFormat.Byte,2,0,List.Count}
},each BinaryFormat.Byte
)(File.Contents("C:\Users\Administrator\Desktop\test.csv")))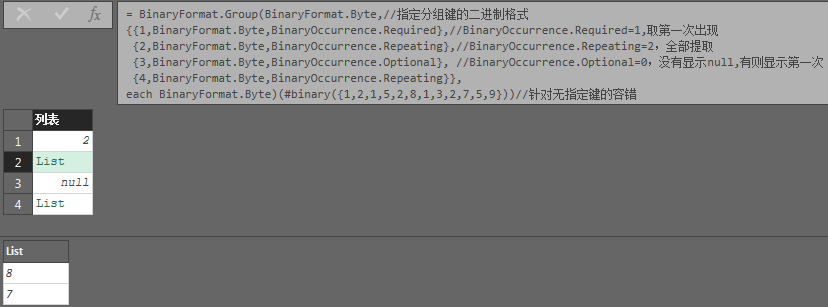
php
let
fb=File.Contents("C:\Users\Administrator\Desktop\复合文档.xlsx"),
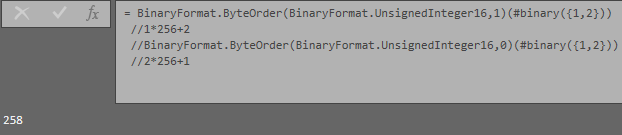
u32=BinaryFormat.ByteOrder(BinaryFormat.UnsignedInteger32,0),
u16=BinaryFormat.ByteOrder(BinaryFormat.UnsignedInteger16,0),
Header=BinaryFormat.Record([MiscHeader=BinaryFormat.Binary(14),BinarySize=u32,FileSize=u32,FileNameLen=u16,ExtrasLen=u16]),
HeaderChoice=BinaryFormat.Choice(u32,
each if _ <> 0x4034B50 then
BinaryFormat.Record([Filename="畅心"]) else
BinaryFormat.Choice(BinaryFormat.Binary(26),
each BinaryFormat.Record([Filename = BinaryFormat.Text(Header(_)[FileNameLen]),
Extras = BinaryFormat.Text(Header(_)[ExtrasLen]),
Content = BinaryFormat.Transform(BinaryFormat.Binary(Header(_)[BinarySize]),
(x) =>Binary.Decompress(x,1))
]),
type binary)
),
ZipFormat = BinaryFormat.List(HeaderChoice, each [Filename]<>"畅心")(fb)
in
ZipFormat 上面的函数就可以用来解析seatable导出文件test.dtable,修改最后一句解析表达式为:
php
ZipFormat = Table.FromRecords(
Json.Document(Table.FromRecords(
BinaryFormat.List(HeaderChoice, each [Filename]<>"畅心")(fb)
){1}[Content])[tables])dax studio导出的Microsoft_SQLServer_AnalysisServices.vpax一样可以解析: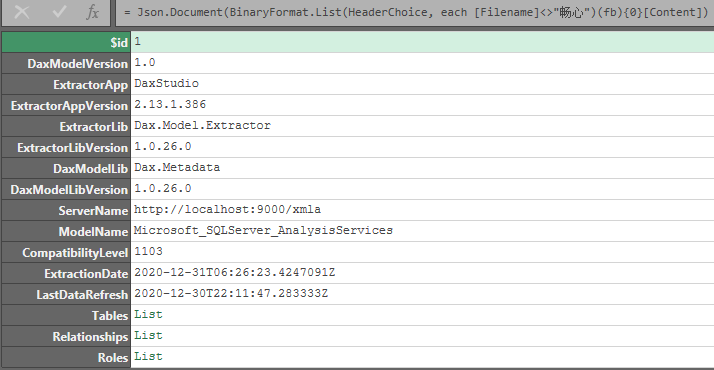
道高一尺 魔高一丈
https://pbihub.cn/users/44

自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)