腾讯共享文档读取 API
前几天有位群友发了个问题,相关讨论参考连接:https://pbihub.cn/qa/1102
这里自我梳理一下腾讯文档公开分享的相关文件数据读取套路:
sheet读取
例如在我的文档某个文件夹下共享了一个腾讯文档工作簿,在浏览器中看到分享文档的链接如下:
https://docs.qq.com/sheet/DYkNJRlp0cWRWZUlH?tab=ez6e97
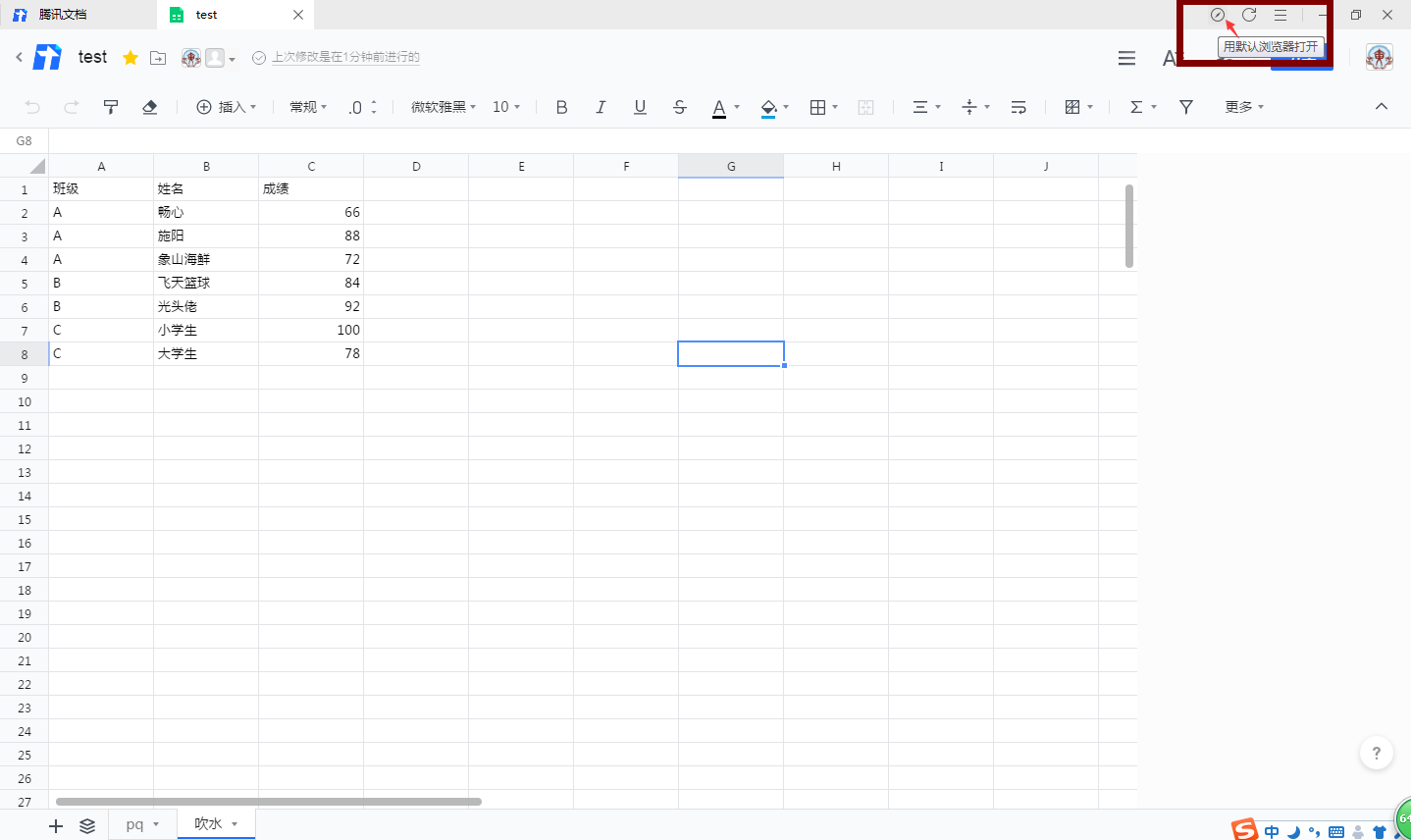
此时我们只需重新构造一个数据读取的接口地址(tab参数不变,将sheet的标志id加入同时指定输出数据格式):
https://docs.qq.com/dop-api/opendoc?tab=ez6e97&id=DYkNJRlp0cWRWZUlH&outformat=1&normal=1此时我们就拿到了该表格的json数据
后续即可用PQ解析json文件读取到表格数据:
Table.FromRows(List.Split(List.Transform(Record.ToTable(Json.Document(Web.Contents("https://docs.qq.com/dop-api/opendoc?tab=ez6e97&id=DYkNJRlp0cWRWZUlH&outformat=1&normal=1"))[clientVars][collab_client_vars][initialAttributedText][text]{0}{2}{0}[c]{1})[Value],(x)=>x[2]?{1}?),3))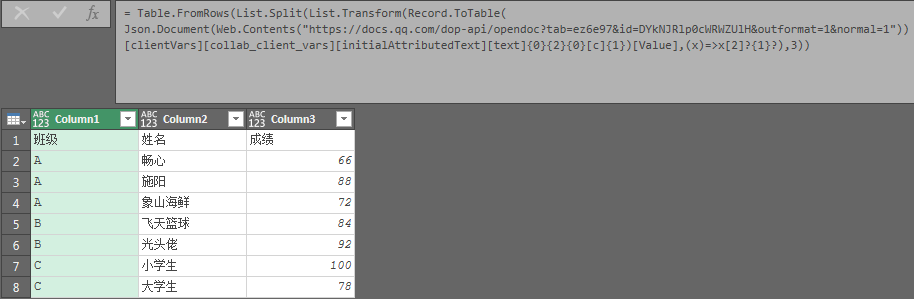
但是有个问题,如果我们的表格数据中间出现了空单元格这种解析方式会导致部分数据无法对齐表格,需要重构!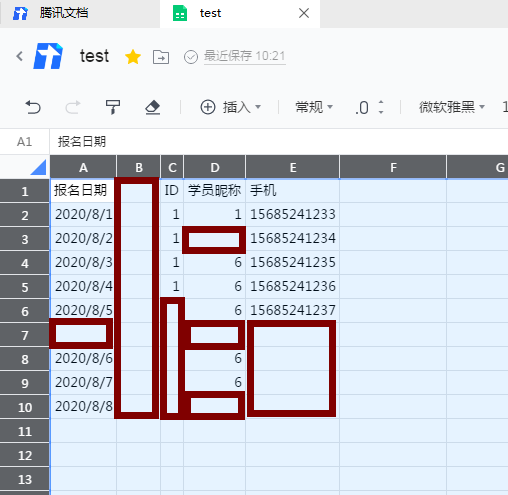
图上表格连接为:https://docs.qq.com/sheet/DYkNJRlp0cWRWZUlH?tab=nsffyn
重构网址:https://docs.qq.com/dop-api/opendoc?tab=nsffyn&id=DYkNJRlp0cWRWZUlH&outformat=1&normal=1
我们尝试用老方法:
Table.FromRows(List.Split(List.Transform(Record.ToTable(Json.Document(Web.Contents("https://docs.qq.com/dop-api/opendoc?tab=nsffyn&id=DYkNJRlp0cWRWZUlH&outformat=1&normal=1"))[clientVars][collab_client_vars][initialAttributedText][text]{0}{2}{0}[c]{1})[Value],(x)=>x[2]?{1}?),3))将会报错,针对表格中间周围数据有缺失的情况json的数据结构页有所变化。
我们可以一步步深化解析看看json结构,其中发现如图信息: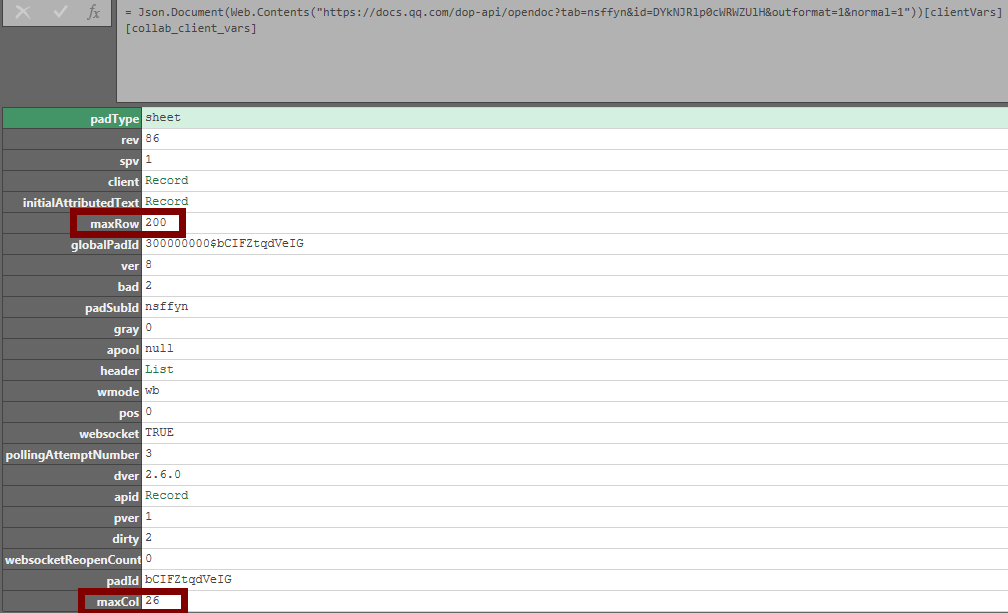
26列200行的数据区域边界值
内层貌似也有数据边界值信息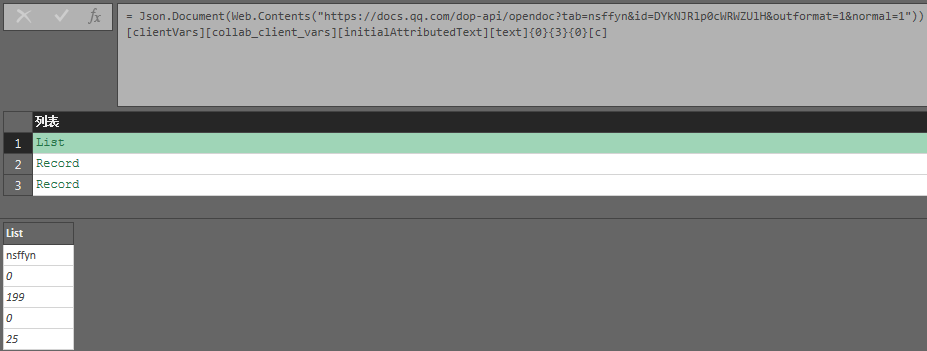
对应单元格数据字段名也有规律,如下: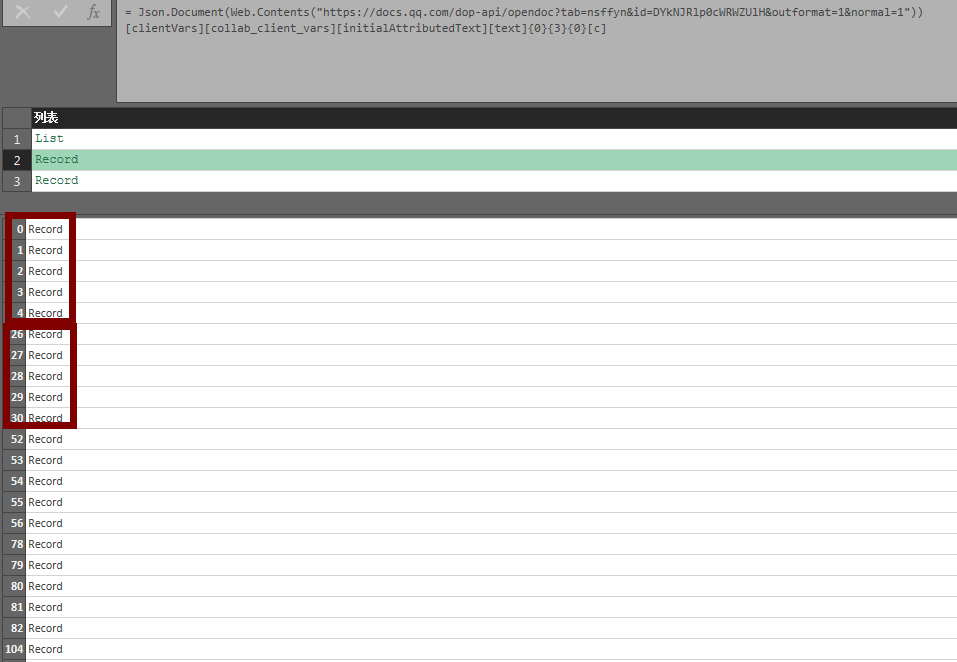
我们发现字段名从0开始,0..4对应第一行数据,然后字段名直接跳到26,因为数据边界是26列200行,所以字段名26是第27个数据,也就是第二行的第一个单元格(可以深化看一下部分字段下记录值情况验证),所以直接构造表格导致中间空白的部分单元格没有存储在json中无法对齐表格,那么可以尝试重构表格矩阵:
let
web=Json.Document(Web.Contents("https://docs.qq.com/dop-api/opendoc?tab=nsffyn&id=DYkNJRlp0cWRWZUlH&outformat=1&normal=1"))[clientVars][collab_client_vars][initialAttributedText][text]{0}{3}{0}[c],
doc=Table.FromList({0..web{0}{2}},each List.Transform({0..web{0}{4}},(m)=>Record.FieldOrDefault(web{1},Text.From(_*web{0}{4}+m+_),null)[2]?{1}?))
in doc说明:有些文档的深化结构有些许变化,有的可能是[clientVars][collab_client_vars][initialAttributedText][text]{0}{2}{0}[c]
doc文档读取
与sheet类似,假设有doc腾讯文档共享链接:https://docs.qq.com/doc/DYktXWXFmUkdEb29V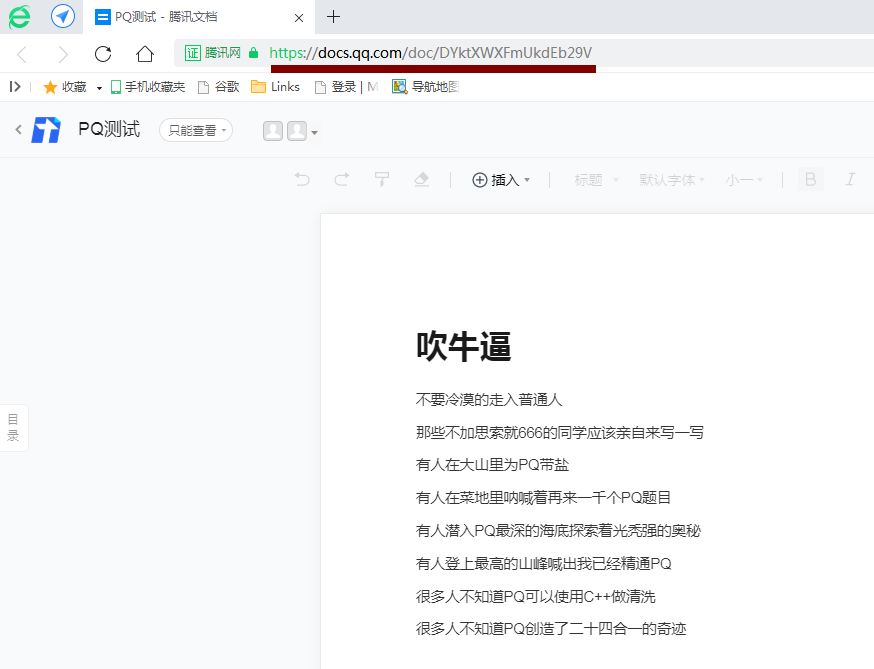
尝试构造接口地址:https://docs.qq.com/dop-api/opendoc?id=DYktXWXFmUkdEb29V&normal=1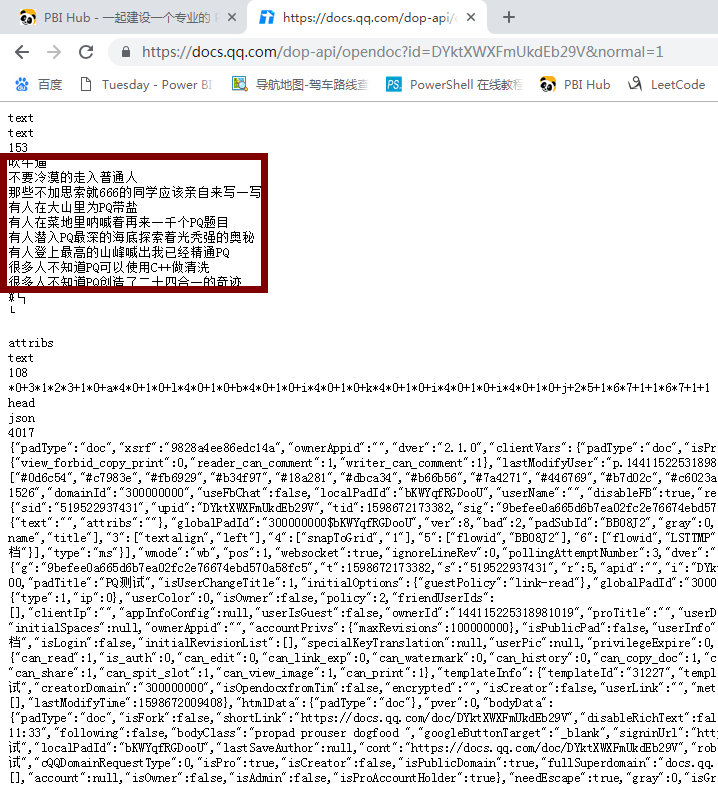
看到这里拿到文档信息应该不难了!
List.Skip(List.FirstN(Lines.FromBinary(Web.Contents("https://docs.qq.com/dop-api/opendoc?id=DYktXWXFmUkdEb29V&normal=1")),each _<>"attribs"),3)注意:尾部有乱码制表符相关信息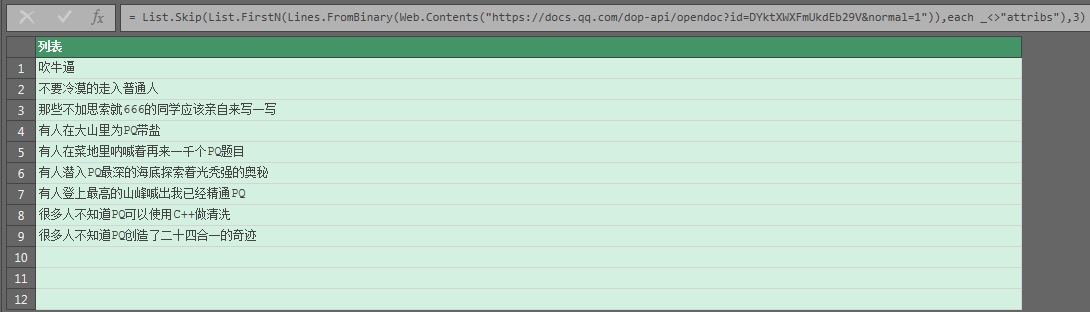
还有一种情形,拿取doc文档中的表格数据
https://docs.qq.com/doc/DYm9lV3N5WW1BaWF5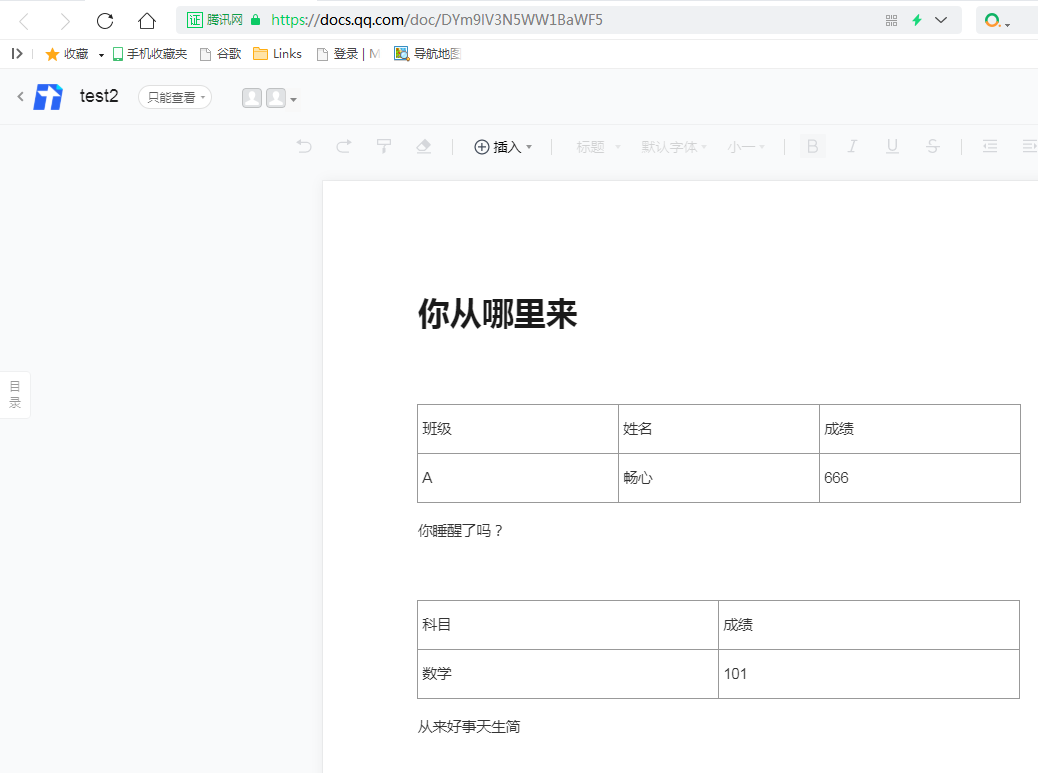
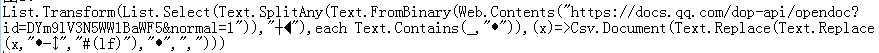
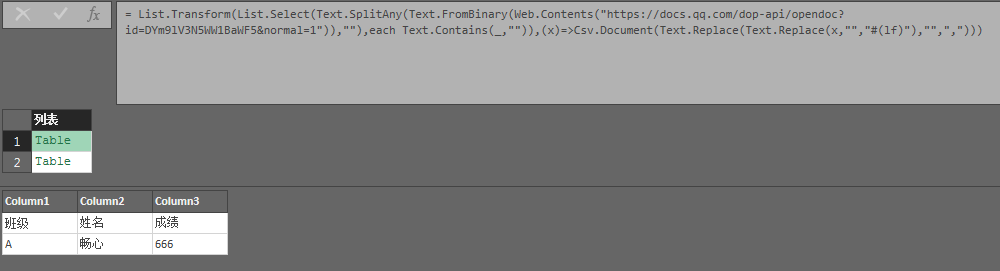
读取forms
填写网址:https://docs.qq.com/form/edit/DYlhmZlVUSW1BYUZX#/fill-detail
收集信息地址:https://docs.qq.com/sheet/DYlZqTU1XWkZJV3pk?tab=BB08J2
问题提取:
List.Transform(Json.Document(Lines.FromBinary(Web.Contents("https://docs.qq.com/dop-api/opendoc?id=DYlhmZlVUSW1BYUZX&normal=1")){3})[questions],each [title])或者
List.Transform(Json.Document(Web.Contents("https://docs.qq.com/dop-api/opendoc?id=DYlhmZlVUSW1BYUZX&outformat=1&normal=1"))[clientVars][collab_client_vars][initialAttributedText][text]{0}[questions],each [title])答案收集:
Json.Document(Web.Contents("https://docs.qq.com/dop-api/opendoc?id=DYlZqTU1XWkZJV3pk&tab=BB08J2&outformat=1&normal=1"))[clientVars][collab_client_vars][initialAttributedText][text]{0}{3}{0}[c]
后面表格数据处理与sheet一样操作即可!与腾讯文档类似的石墨文档公开分享的表格数据读取:
加入石墨文档分享连接为:
https://shimo.im/sheets/90f3FCyeHM8SYrLf/hzozR那么文档读取接口构造为:
https://shimo.im/api/sheetcalc/screenshot/90f3FCyeHM8SYrLf/hzozR只是石墨文档的数据格式更复杂,处理字符串要些技巧: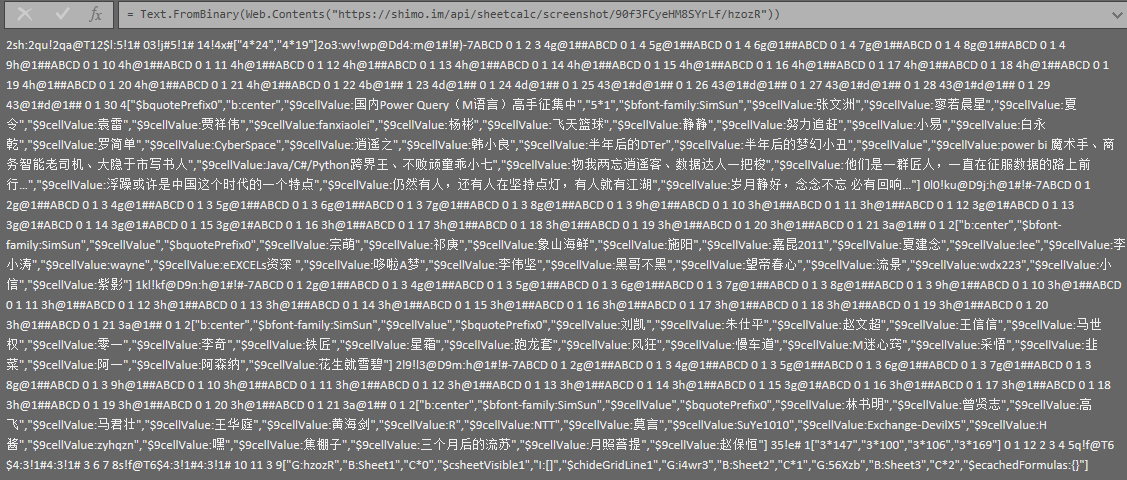
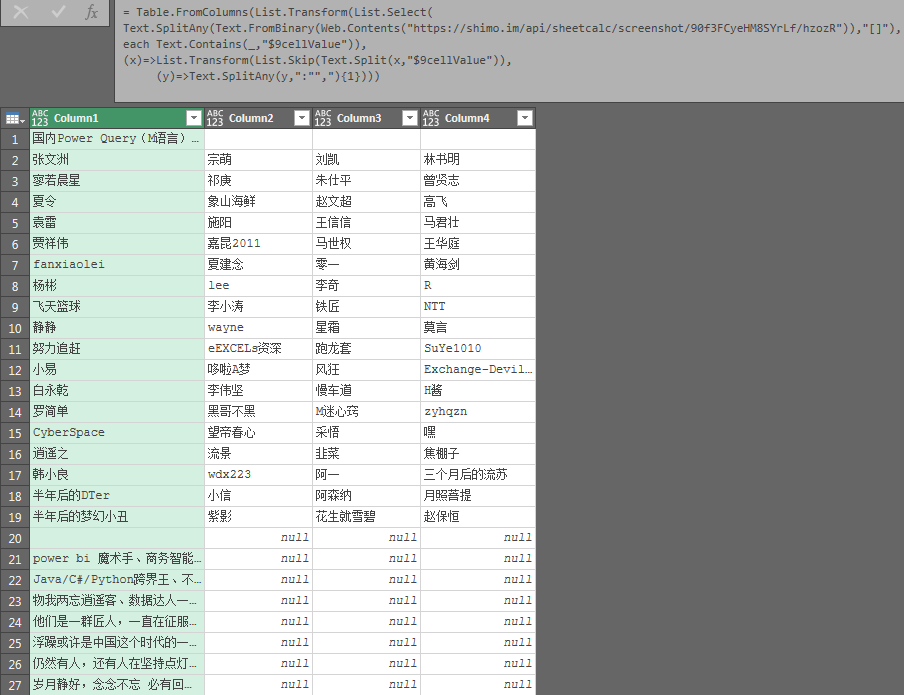
Table.FromColumns(List.Transform(List.Select(Text.SplitAny(Text.FromBinary(Web.Contents("https://shimo.im/api/sheetcalc/screenshot/90f3FCyeHM8SYrLf/hzozR")),"[]"),
each Text.Contains(_,"9cellValue")),(x)=>List.Transform(List.Skip(Text.Split(x,"9cellValue")),
(y)=>Text.SplitAny(y,":"","){1})))道高一尺 魔高一丈
https://pbihub.cn/users/44

自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)