
因为要根据某种规则筛选表,我找到几种方法,因为数据源有几百万行,所以需要比较一下几种方法的效率,找到用时最短的方法。
例如有这样一张销售表,现在需要筛选出京津冀的订单。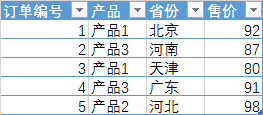
最基本的方法就是直接筛选:
方法1:直接筛选
筛选的行 = Table.SelectRows(源, each
([省份] = "北京" or
[省份] = "天津" or
[省份] = "河北"))但是省份的分类是可变的,根据需要随时会有新的分类方法,记录在一个表中: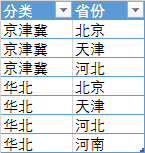
这样方法1就需要经常修改语句,很麻烦,于是我尝试其他几种方法:
方法2:List.Contains
筛选的行 = Table.SelectRows(源, each
List.Contains(
{"北京","天津","河北"},
[省份]))最容易的是可以想到List.Contains,这样{"北京","天津","河北"}就可以用变量来替换了。
然后我又想到了List.MatchesAny:
方法3:List.MatchesAny
筛选的行 = Table.SelectRows(源, each
List.MatchesAny(
{"北京","天津","河北"},
(current) => [省份]=current))不知道作用原理是不是匹配到一个值就不再进行其他元素的匹配,如果是这样的话效率应该比List.Contains要高一些。
然后又想到了List.Accumulate:
方法4:List.Accumulate
筛选的行 = Table.SelectRows(源, each
List.Accumulate(
{"北京","天津","河北"},
false,
(state, current) =>
if [省份]=current
then true
else state))这种方法也是判断3遍,但是如果匹配上了的话就返回true,可能有点类似于递归,但是效率应该不如递归更高,但是应该会比List.Contains高一些。
还有递归法:
方法5:递归
筛选的行 = Table.SelectRows(源, each
let list={"北京","天津","河北"},
fx=(n)=>
if [省份]=list{n}
then true
else if n=List.Count(list)-1
then false
else @fx(n+1)
in fx(0))这种方法的原理是把销售表每一行的省份值在list中进行匹配,从第1个元素进行匹配,如果="北京"就停止匹配并返回true,如果≠"北京"的话再看是不是="天津",如果="天津"就停止匹配并返回true,如果≠"天津"再进行下一个匹配……直到最后一个元素"河北",如果没有匹配上的话就返回false,其实意思就是判断销售表中每一行的省份是不是属于“京津冀”,是的话就筛出来,不是就筛掉,和方法1直接筛选的道理是一样的,只是用递归可以把“京津冀”设为一个变量,方便动态变化。
递归法写法复杂一些,但是它有设有中断规则,对于list中的元素匹配上一个就停止,不再进行后面没必要的匹配运算,我感觉效率会更高一些,这个例子很简单看不出来,但是如果销售表有上亿行,而list中的城市也有几百个,比如要计算双十一当天1亿笔淘宝订单中发往三线城市(估计500+吧)的订单销售额合计,这时候我估计递归法计算会快一些。
总结
方法1最简单,但是我感觉也是要穷举list中的每一个元素,和List.Contains、List.Accumulate等方法计算量一样,但是语句简单些,可能会计算快一些。
方法2和3都要穷举list中的所有元素,计算量会比较大。
5种方法的运算速度我估计是方法5>方法4>方法1>方法3>方法2,如果有合适的例子可以测试一下。
在施阳的文章《模拟绝对引用累计计数》中提到可以测试不同方法的刷新时间,但是我不知道怎么测试的啊,我现在只能是大概判断,不知道是不是PQ也可以用DAX Studio或者类似工具测试刷新时间,知道的朋友可以留言告诉我一下啊,多谢啦。
实例下载:
链接:https://pan.baidu.com/s/1CAwQWObOK3e7uTW9jSlwLw
提取码:rc6i

 把区域做个参数表,先筛一下,再和数据表合并查询,再筛数据 好像速度还行。
把区域做个参数表,先筛一下,再和数据表合并查询,再筛数据 好像速度还行。




