
学习 CALCULATE 函数(七)丨帕累托分析法的 BUG

之前,白茶研究了一下帕累托中的关键性DAX代码——累计求和。明白了累计求和的原理,就可以动手在PowerBI中进行制作帕累托图了。
数据如下图: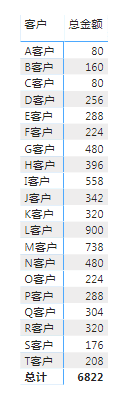
编写如下代码,求出每个客户销售额的占比:
客户占比 =
DIVIDE ( SUM ( '示例'[总金额] ), CALCULATE ( SUM ( '示例'[总金额] ), ALL ( '示例' ) ) )结果如图: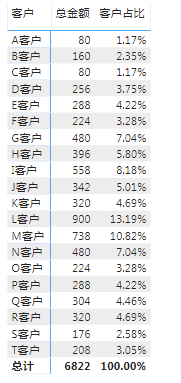
接下来就是利用之前提到过累计求和的代码,求累计占比,可是这里就存在疑问了,这里用什么来进行筛选呢?没有时间维度,该如何进行?
这里有两种方法:
一、上期提到过的参数索引: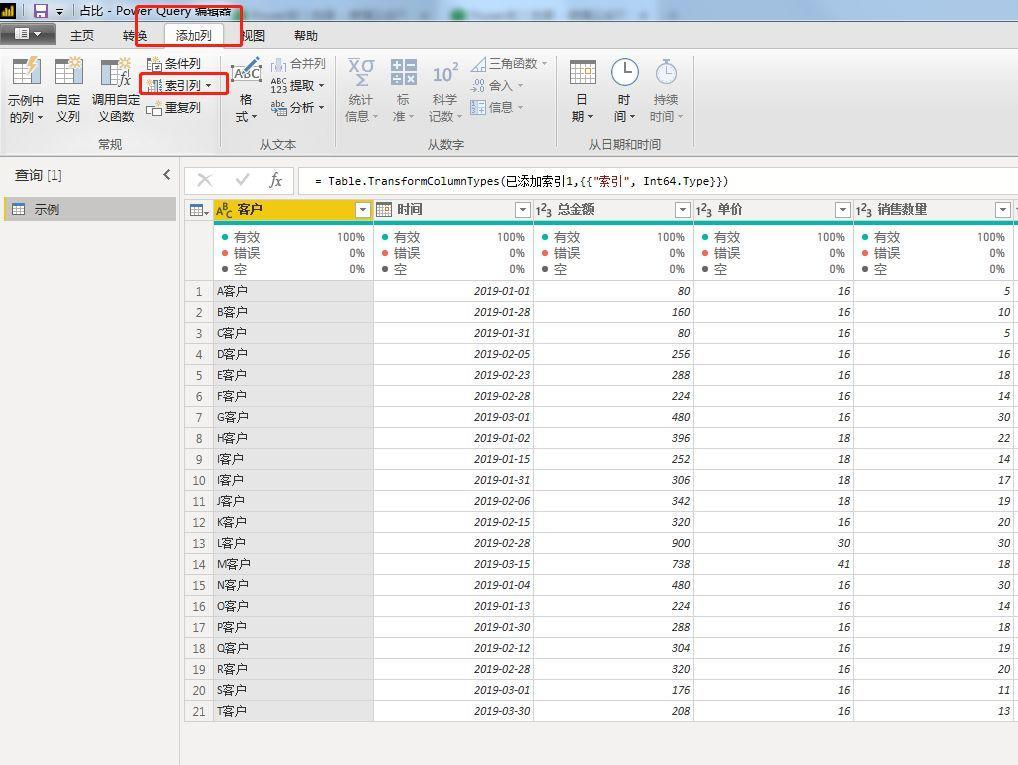
在PQ编辑界面选择添加参数。
之后编写如下代码:
参数占比 =
CALCULATE ( [客户占比], FILTER ( ALL ( '示例' ), '示例'[索引] <= MAX ( '示例'[索引] ) ) )结果如图: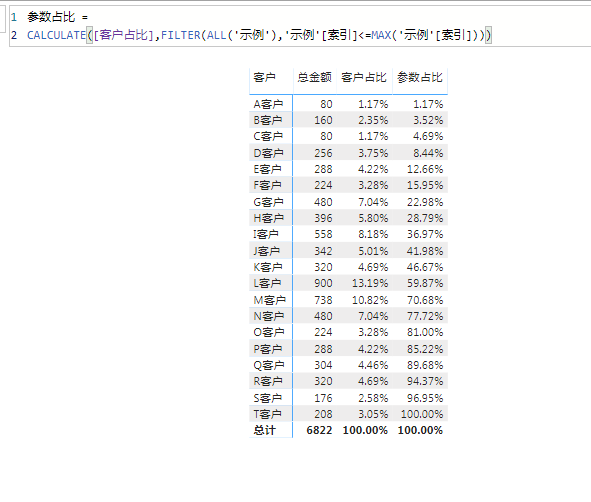
二、使用VAR定义常量,再用MAX筛选。代码如下:
VAR累计求和 =
VAR HQ = [客户占比]
RETURN
CALCULATE ( [客户占比], FILTER ( ALL ( '示例' ), [客户占比] >= HQ ) )结果如图: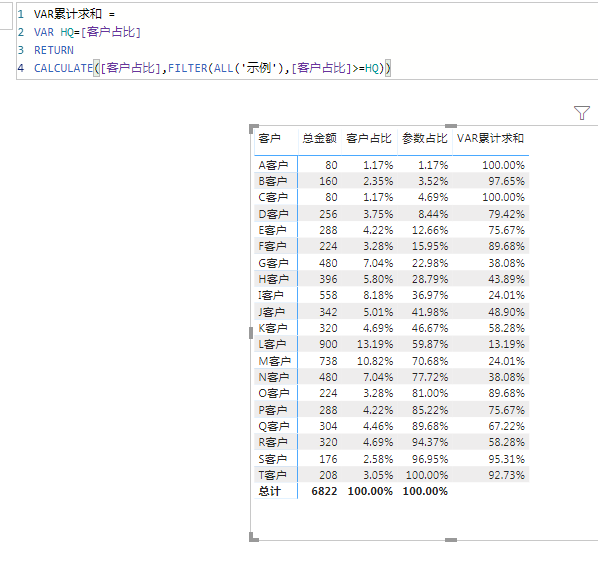
可以看得出来,两种办法求得的数值有很明显的区别,而且,细心观察,不难发现第二种方法有点小问题:
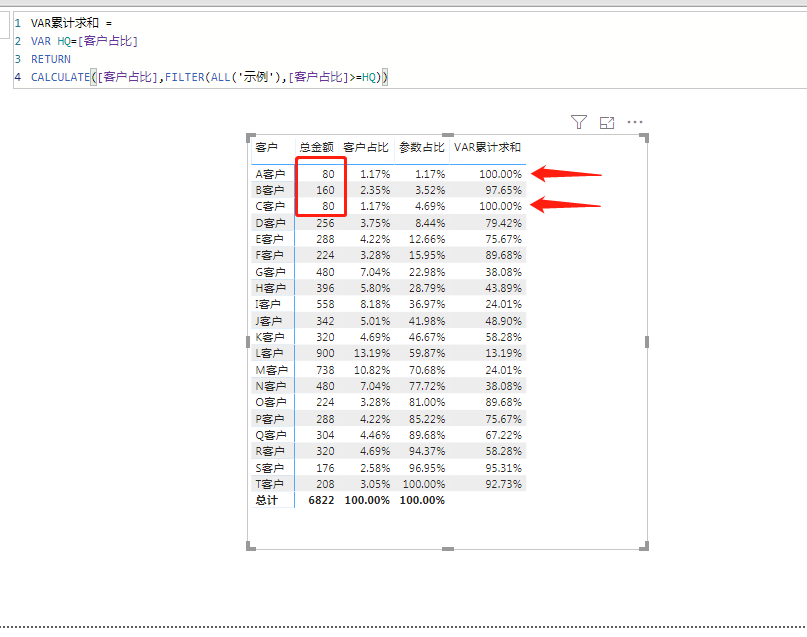
就是在实际情况中,不可能没有相同项的数据,这样的话虽然实际效果差别不是特别多,但是特别不严谨。这个问题我们稍后再说,先继续对比两种方法:
在PowerBI中并没有专门的帕累托图,但是我们回想一下,不就是折线图与柱形图的组合么?
选择这俩个中的任意一个都可以。
我们将[客户]共享轴,[总金额]作为列值,分别将[参数占比]与[VAR累计求和]放入行值中进行对比。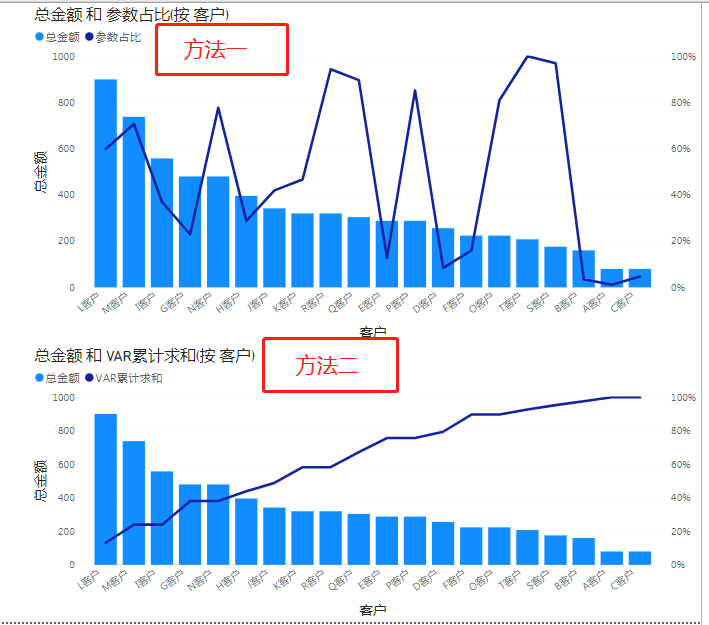
很清楚的就发现了,方法一做的图不符合帕累托曲线图,这是因为什么呢?因为[参数占比]是根据白茶添加的参数索引计算的,不是按照纯累计帕累托的思想进行的。
而方法二,是按照对比[占比]情况进行聚合的,所以第二种办法更符合帕累托的思路。
可是记得白茶在上面说过的么?就是实际情况中,肯定有数据是相同的,虽然不影响我们的分析结果,但是会显得不严谨。而且,@韭菜大神说的一句话,白茶深有感触,两个数据都是一样的,你凭啥判定这个是1,那个是2呢?
这句话让我无以言对。确实,岂能尽如人意,但求无愧于心吧。
这里可以补充一下,就是第二种的方法,可以对两个数据进行判定,代码如下:
优化VAR累计 =
VAR HQ = [客户占比]
VAR NA =
SELECTEDVALUE ( '示例'[客户] )
RETURN
CALCULATE (
[客户占比],
FILTER (
ALL ( '示例' ),
IF ( [客户占比] <> HQ, [客户占比] >= HQ, [客户占比] >= HQ && '示例'[客户] <= NA )
)
)结果如图: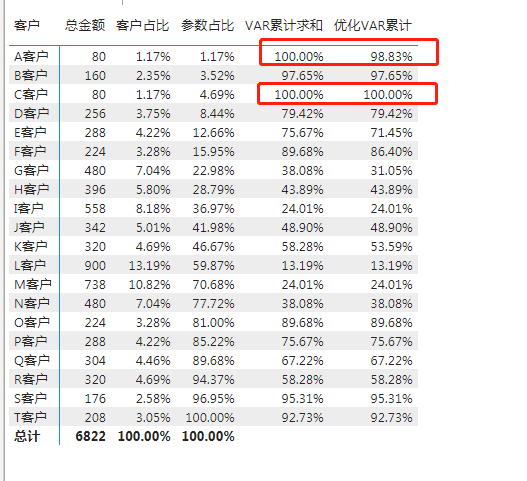
能看的出来,对两个相同的数据进行了排序。各位小伙伴,请自行判断,根据实际需求选择适合自己的代码。
解释一下代码含义:
VAR HQ=[客户占比]—这里是将客户占比定义为常量
VAR NA=SELECTEDVALUE('示例'[客户])—同上,只不过定义的是客户
RETURN—结果输出
CALCULATE([客户占比],—这里是根据后面的筛选,然后进行聚合
FILTER(ALL('示例'),—选择整个表,清除外部筛选
IF( [客户占比]<>HQ,—假如两个客户占比不同
[客户占比]>=HQ,—结果1,按照大于等于的顺序筛选
[客户占比]>=HQ&&'示例'[客户]<=NA)))—否则2,按照客户名的排序方法进行大于等于的顺序筛选。
小伙伴们❤GET了么?
白茶会不定期的分享一些函数卡片
(文件在知识星球[PowerBI丨需求圈])
这里是白茶,一个PowerBI的初学者。
下面这个知识星球是针对有实际需求的小伙伴,有需要的请加入下面的知识星球。
请在PC端查看,有部分图片无法在移动端显示。
PowerBI丨白茶
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
