
下次就带岳母去这些地方玩——Python 爬虫在 Power BI 中的运用
北京这么大,景点这么多,当被媳妇儿问“下周带我妈去哪儿玩?”屏幕前的你是不是也慌得一比???
一番冥思苦想之后,作为Power BI深度用户的小编我自然又绕了回来--能不能用Power BI解决这个问题呢?
又一番冥思苦想之后,小编认为:可以!
且看下文如何分解:
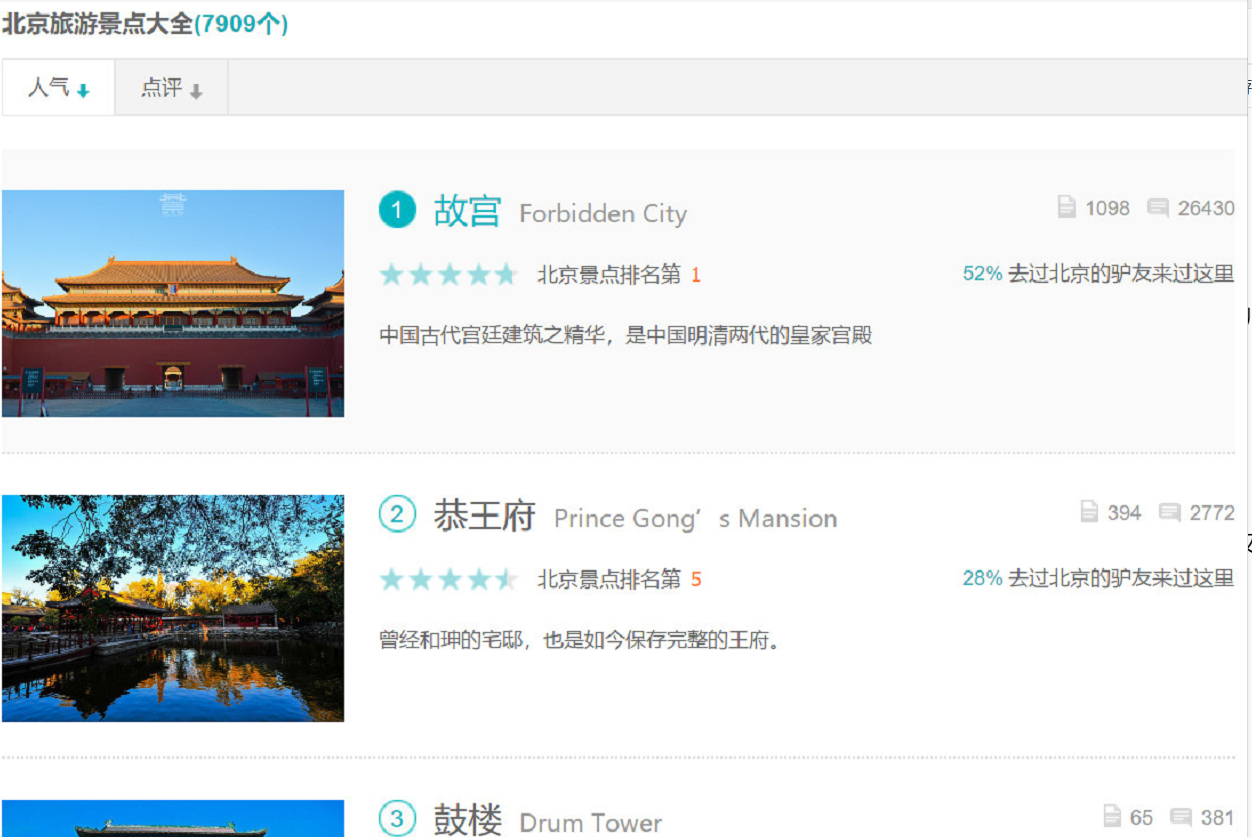
Step1:网页分析
分析去某儿网的网点结构,决定爬取哪些信息,景点名称,星级,排名,游客评论数量,攻略数量,经纬度(html里面有)
Step2:编写爬虫代码
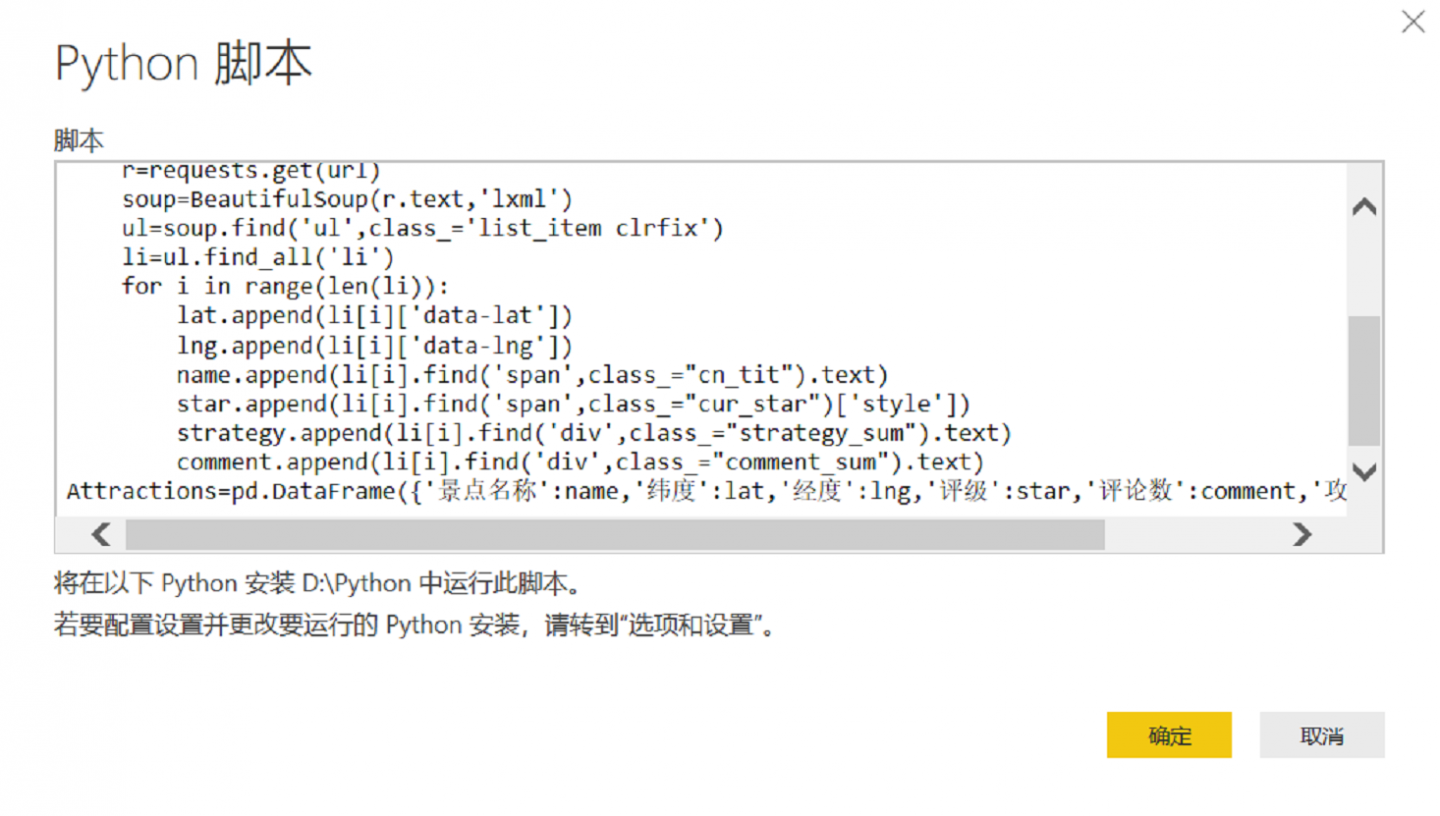
用requests返回网页信息,再用BeautifulSoup解析网页(考虑尾页很多景点星级数据都为0,只取了前二十页)
import requests
import pandas as pd
from bs4 import BeautifulSoup
import numpy as np
name,lat,lng,star,strategy,comment=[ ],[ ],[ ],[ ],[ ],[ ]
for i in range(1,21): #只取前20页,每页展示10个景点
url='http://travel.qunar.com/p-cs299914-beijing-jingdian-1-%s'%i
r=requests.get(url)
soup=BeautifulSoup(r.text,'lxml')
ul=soup.find('ul',class_='list_itemclrfix')
li=ul.find_all('li')
for i in range(len(li)):
name.append(li[i].find('span',class_="cn_tit").text) #提取景点名称
lat.append(li[i]['data-lat']) #提取纬度
lng.append(li[i]['data-lng']) #提取经度
star.append(li[i].find('span',class_="cur_star")['style']) #提取星级
strategy.append(li[i].find('div',class_="strategy_sum").text) #提取攻略数量
comment.append(li[i].find('div',class_="comment_sum").text) #提取评论数量
Attractions=pd.DataFrame({'景点名称':name,'纬度':lat,'经度':lng,'评级':star,'评论数':comment,'攻略数':strategy})
print(Attractions)Step3:代码植入PowerBI
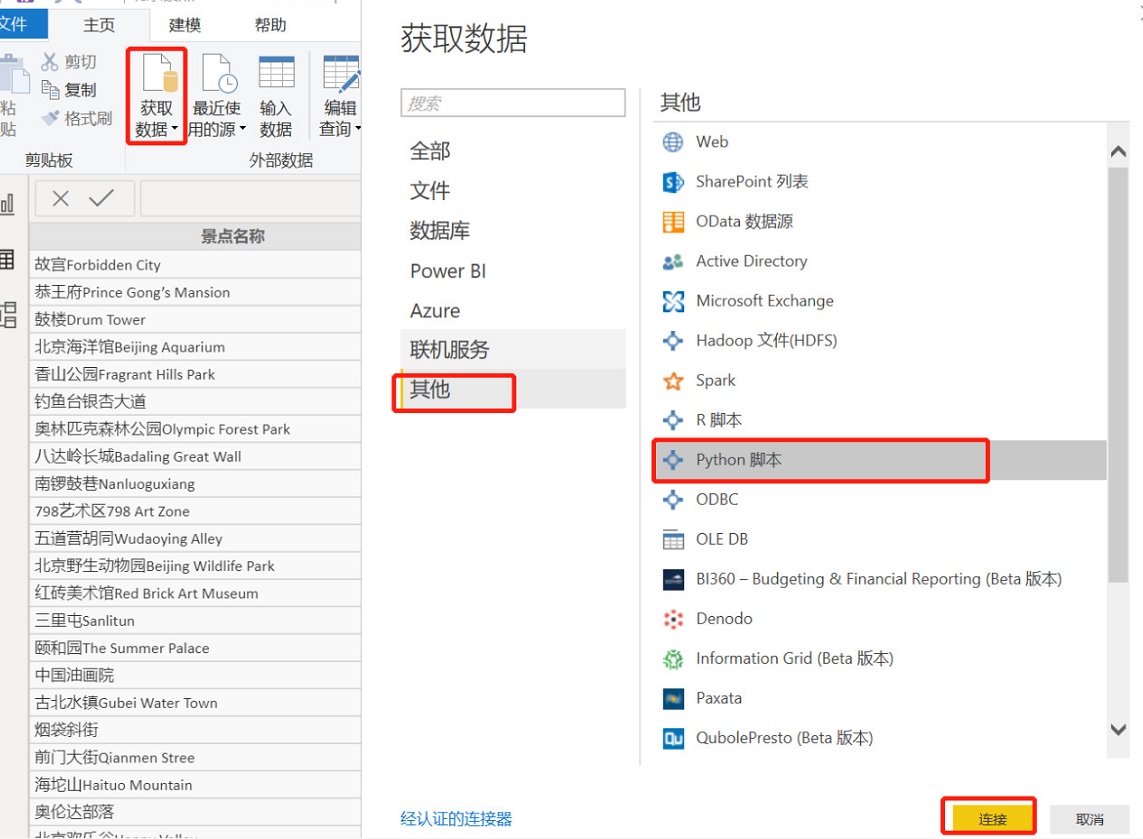
获取数据-其他-Python脚本,粘贴脚本
Step4:数据清洗
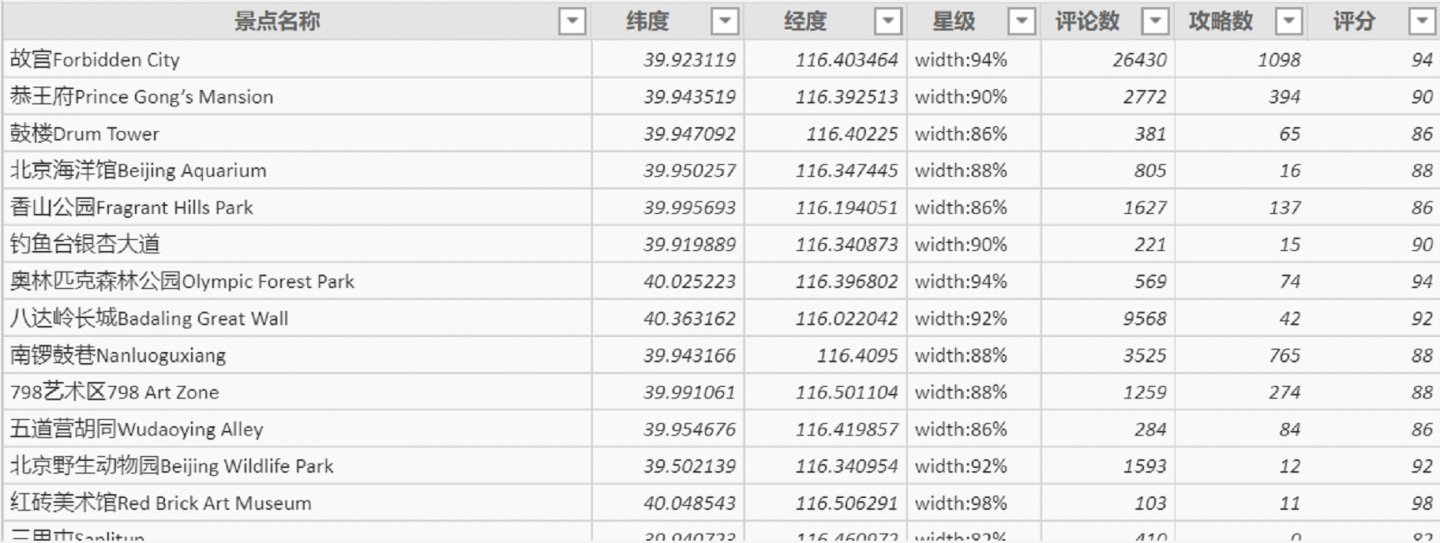
这里将星级提取为评分。
Step5:将景点信息在Dashboard中呈现
位置由经纬度控制,气泡大小代表攻略数量,颜色代表游客评论数量。
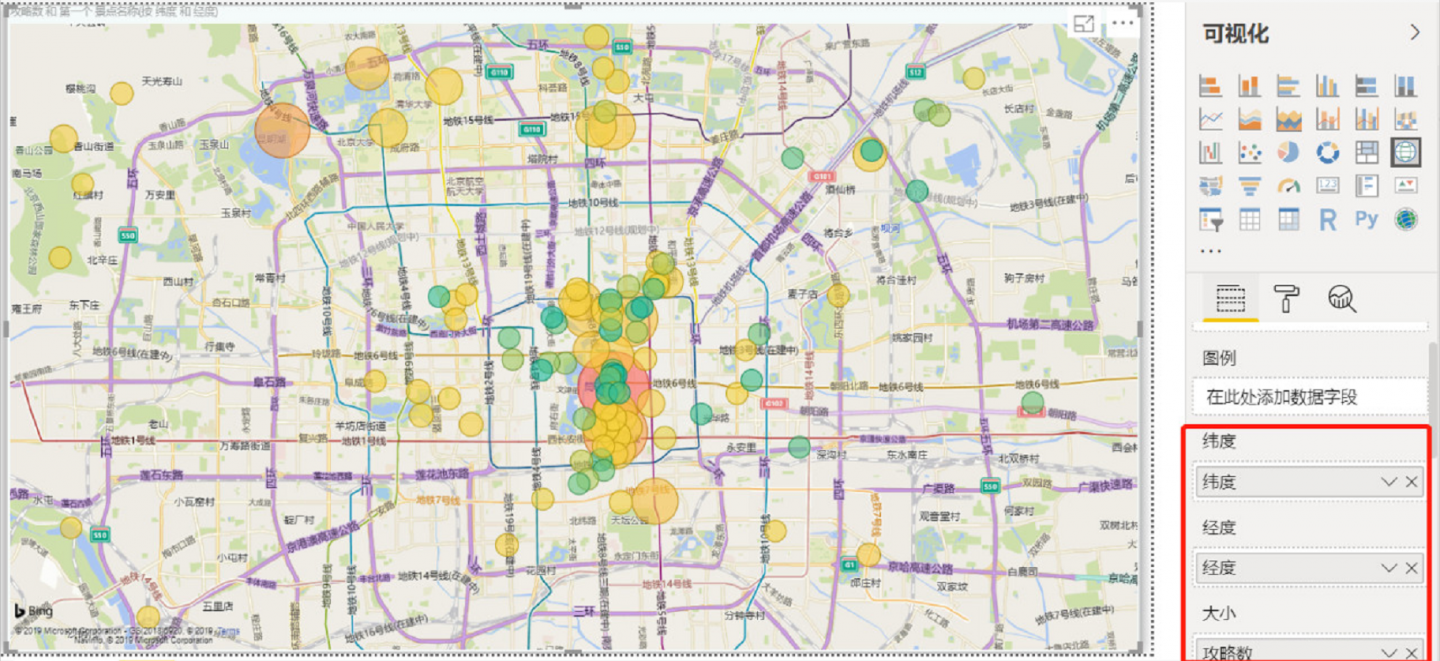
下次就带岳母去这些地方玩——Python爬虫在Power BI中的运用
Step6:将上图呈给媳妇看看,根据景点在地图上的分布以及火热程度可酌情发表个人意见
总结一下:
1) 需要在本地部署python环境,配置好变量环境;
2) 提前在IDE上编写好爬虫程序,Python的处理结果以Dataframe形式输出;
3) 获取数据-更多-其他-python脚本,在输入框输入调试好的代码;
4) 如需修改代码,编辑查询-更改源-修改代码,注意Dataframe的变量名不能改;
5) 在Power BI中,python除了可以导入外部数据,在数据清洗和可视化也有发挥的地方,有兴趣的小伙伴可以研究研究哦~
今天的内容就是这些,小伙伴们下期再见!
-
PowerPivot工坊原创文章,转载请注明出处!
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)

