
在 Power BI 中筛选每类产品的前三名
本文翻译自Marco Russo的文章——《Filteringthe Top 3 products for each category in Power BI》本文介绍了在Power BI中如何使每个类别的产品只显示前三名的不同方法,其中详细介绍了如何使可视化展现适应不同的模型和业务需求。
Power BI可视化中的视觉级筛选器可以帮你减少可视化中的元素数量。用这种方法可以根据其他切片器或视觉效果需要的选择轻松地将筛选器应用于筛选报表中产品的前十名。
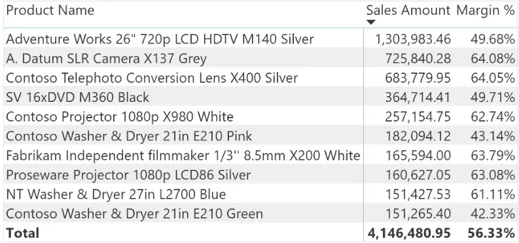
但是,针对希望在单个可视化图表中能够显示每一类产品前三名或者自定义前N名的要求。仅仅通过PowerBI的用户界面的图形化操作并不能提供一种简单的方法。而我们的目标是获得如下图所示结果: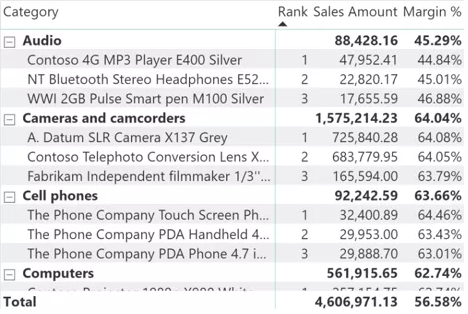
通常,针对此问题的方法是创建一个复杂度量值,将不需要的结果隐藏起来。换句话说,它计算出产品的排名,将排名大于三的结果排除。这种方法虽然易于实现,但是需要修改所有显示在可视化中的度量值,同时会使系统性能受到影响。
更好的解决办法是创建一个用于视觉级筛选器的特定度量值,该度量值无需对其他度量值进行任何更改,仅针对每个产品执行一次,用以定义可见项组。我们将会看到解决此问题的不同选择。
第一种简单的解决方案是,首先度量每一类商品中各个产品的等级,之后在可视化中筛选此度量值的结果。
产品排名度量值返回一类产品中某个产品的排名,ISINSCOPE函数保证排名仅适用于单个产品名称,而CALCULATETABLE函数检索当前产品组所有在可视化中可见的产品名称。例如,我们在可视化中使用了产品类别,相同的度量适用于可视化中其他任何用到的产品列。
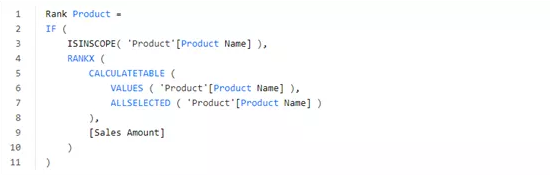
请注意,CALCULATETABLE与ALLSELECTED(产品[产品名称])的内部不同,实际上,度量值必须考虑到Product [Category]上的筛选器上下文,VALUES函数能够完成此任务,而单独的ALLSELECTED函数将忽略可视化应用的筛选器,从而为度量值产生错误的结果。
你将此度量值用于具有产品名称粒度矩阵的可视化筛选器,该筛选器仅筛选返回排名小于或等于三的产品。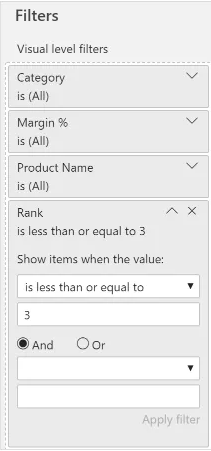
这种方法是有效的,并且可以在可视化中使用相同的Rank Product度量来准确地对每个类别中的产品进行排序。可视化图表中还可以包括其他度量值,例如上一个图中包含的保证金百分比。
替代筛选器的方法
产生替代方法的原因是觉得没有必要计算所有产品的确切排名:让它来检索每个类别的前三个产品,并将结果应用于可视化筛选器。但是,TOPN内部计算的复杂度与RANKX相差无几,因此这并不算一个真正的优化,更多算是一种DAX替代技术的练习。
因为我们并不能给出一个可以当做视觉级筛选器的表,所以我们可以创建一个度量值,如果在筛选器上下文中选择的产品是可见的,则返回1,否则返回0. FilterTop3ByCat_Filter度量通过使用GENERATE和TOPN的组合生成每个类别需要筛选的产品列表,然后使用KEEPFILTERS将结果应用于筛选器上下文。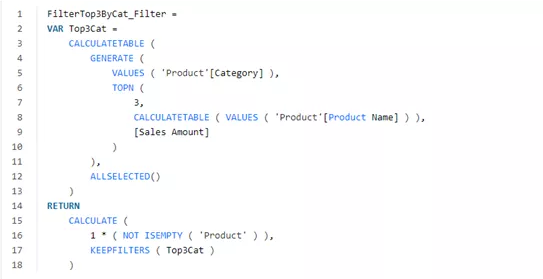
该方案的一个主要缺点是该方法必须专门设计一些应用于可视化的列。例如,样本报告中使用的字段在行中可以看到“类别”和“产品名称”列。
请注意,在准备可视化之前,会针对每种产品评估此度量。因此,在开始时应用ALLSELECTED函数对于消除依赖性是至关重要的,此依赖性产生于类别和产品名称的组合的迭代期间发生的上下文转换。这样,无论在准备可视级筛选器时迭代的产品如何,Top3Cat变量都会产生相同的结果,从而对所有产品进行单一评估。
最终CALCULATE中的KEEPFILTERS将此可见产品列表与当前选择组合在一起,产生该度量的预期结果:如果存在至少一个产品,则为1;如果通过新筛选器没有可见产品,则为0。 此度量值是一个很好的练习,可以检验你对上下文转换,ALLSELECTED和KEEPFILTERS的了解。
尽管这种方法在这种情况下没有体现出任何优势,但你可以创建专门为视觉级别筛选器设计的特殊DAX度量值。你可以自定义可视化中项目的选择,从而克服Power BI用户界面中可用选项的限制。这种方法的优点是数据模型中的现有度量可以无任何变化地工作 - 除非你希望将隐藏项目包含在组小计中,如以下部分所述。
显示已过滤项目组的未过滤小计
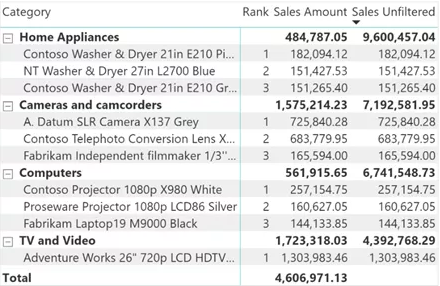
通过使用视觉级筛选器,每一类产品的“销售额”值对应于该类别的前三个产品销售额的总和。换句话说,“销售额”度量仅根据应用于可视化的筛选器显示可见产品销售额的总和。
如果要在类别级别显示所有产品的总和,则需要一个未筛选销售度量值,该度量值在满足条件时忽略产品的筛选器。

“SalesUnfiltered”度量值仅返回“产品名称”级别的“销售额”,而在“类别”级别调用时,它会计算从“产品名称”中删除过滤器的“销售额”。这样,您可以显示一个矩阵,根据所有产品的总销售额对类别进行排序,而只有前三名产品显示在矩阵的详细信息中。
显示已过滤项目组的排名
在前面的例子中,排名度量值在类别级别是空白的。如果要显示类别和产品的排名,则需要以下度量,根据可视化的当前级别更改RANKX参数:
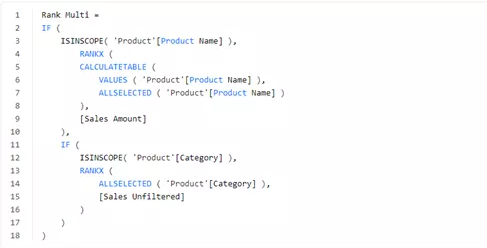
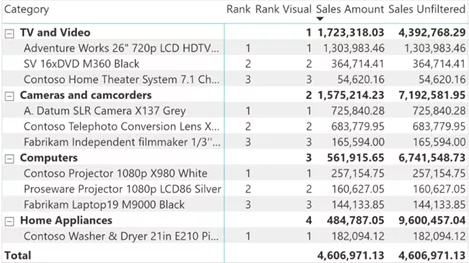
Rank Multi度量值使用Sales Unfiltered度量值正确对类别进行排序,如以下屏幕截图所示:

如果你想创建一个排名,该排名会考虑在可视化当中筛选的产品的销售额度量的排名,在类别级别中获取正确的筛选器上下文涉及到一些复杂计算。需要ALLSELECTED条件来检索在可视化中被过滤的类别和产品的组合。
因此,在遗失当前筛选器上下文之前,必须将当前类别的Sales Amount值存储在变量中,以便使用适当的值执行RANKX。

根据书写度量值产生了如下结果,根据可见的销售额度量值精确计算类别和产品名称的排名。
结论
利用书写特定的度量值应用于可视化的视觉级筛选器是一种非常强大的技术,可以完全自定义报表中显示的项目。此筛选器的存在需要特殊的度量值,以显示与未包含在视觉级别筛选器中项目相关的值。
-
PowerPivot工坊原创文章,转载请注明出处!
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


