
DAX:区分工作日,你就跟我这么做(续)
我们在之前的文章《 区分工作日,你就跟我这么做 》中讲过关于工作时间差的相关计算方法,今天我们要介绍的是如何计算两列日期时间格式数据的工作时间差。
1 计算思路
首先我们思考一下,如果不考虑工作日的话,计算两列值的时间差怎么计算呢?
按照之前文章的思路是判断开始时间和结束时间区间内日期表的行数,如果我们要改成小时,那么可以考虑把日期表扩展成小时就可以计算了。
想到这个,问题就转换为如何将日期表扩展为按小时的时间序列。这是第一种计算方式,这种方式公式比较简单。但是如果日期年份比较多,那么日期时间表行数一年就要8000多行,而且这种方式计算如果要计算更小的单位比如分钟和秒的话,性能就比较低了。
有些其实还有另外一种方式,我们想一下,日期时间差的计算只有开始时间和结束时间的日期不是完整的一整天,中间区间的天数都是完整的,那么我们可以分段计算小时差了,下面我们具体看下两种计算方式。
2 扩展日期表为小时计算小时差
首先,我们来看下如何将日期表扩展按小时的时间序列。需要准备一张Hour的表,存储的数据为一天24小时,可以使用输入数据的方式进行录入。结果如下:
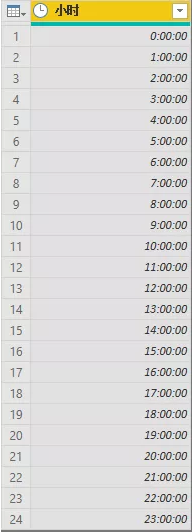
接着就需要考虑如何将日期表扩展为每天的24小时,这就用到了笛卡尔积的方式,这里不是本文的重点,就不再具体介绍了,详细步骤参考文章《 在Power BI中生成笛卡尔积 》中Power Query计算方法部分。这里给出结果:
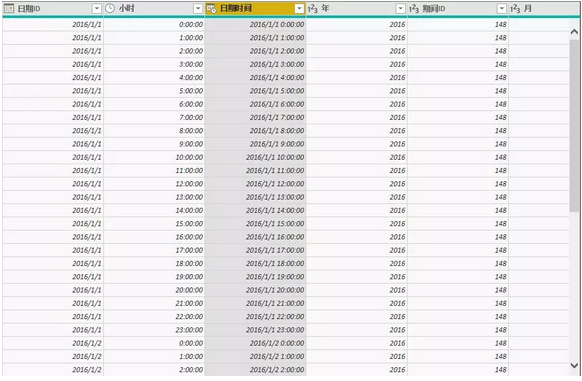
接下来我们就可以计算时间差了:
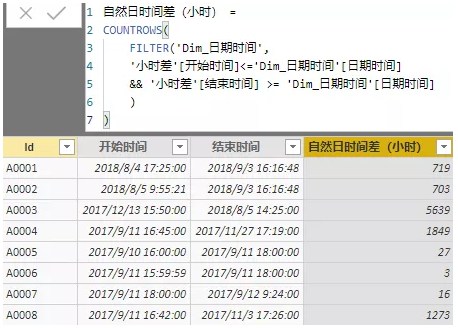
如下图所示,我们在公式中排除非工作日就可以得到结果了:
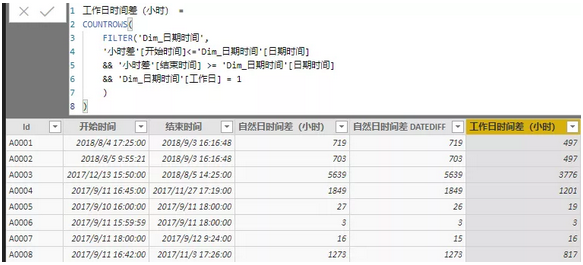
3 分段计算小时差
这种方式计算的时候我们需要判断开始时间和结束时间是否是工作日,那么怎么判断呢?我们可以采用将开始时间和结束时间建立关系的方式去日期表中获取是否是工作日字段,但是如果有多列都需要计算呢,那么关系就需要建很多。如果不使用关系,我们怎么计算呢?
其实公式跟之前的是类似的,具体公式如下:
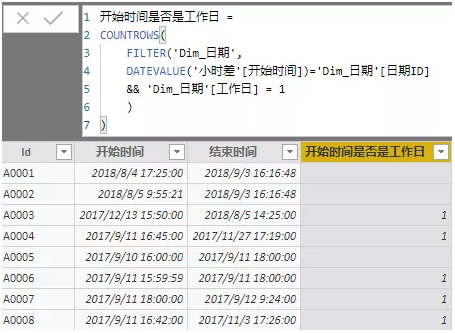
这个公式就是去日期表中筛选等于开始时间的和工作日等于1的数据,那么结果就是如果是工作日,会返回1,代表有一行数据,如果不是工作日会返回空,代表0行。
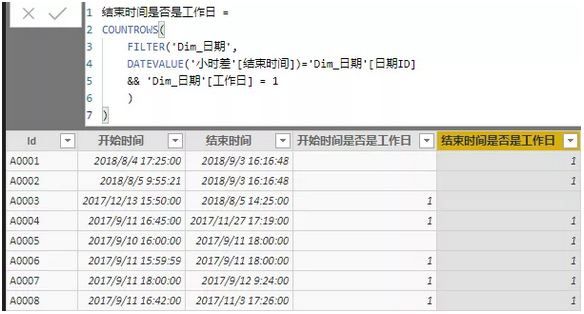
我们用同样的方式可以求出结束时间是否是工作日:
另外还可以使用LOOKUPVALUE函数来计算,公式如下:
LOOKUPVALUE
('Dim_日期'[工作日],'Dim_日期'[日期ID] ,
DATEVALUE('小时差'[开始时间]))
LOOKUPVALUE
('Dim_日期'[工作日],'Dim_日期'[日期ID] ,
DATEVALUE('小时差'[结束时间]))接下来我们就可以求中间区间的工作日差了:
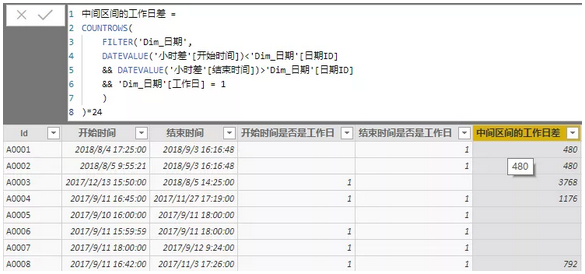
有了前边这些判断,我们就可以分段进行计算了:
方法步骤
- 当开始时间等于空或者结束时间等于空时,返回空;
- 当开始时间是工作日时,结束时间是非工作日时,返回DATEDIFF([开始时间],DATEVALUE([开始时间]) + TIME(23,59,59),MINUTE)/60 + 中间区间工作日差24;
- 当开始时间是工作日时,结束时间是工作日且开始时间所在日期等于结束时间所在日期,返回DATEDIFF([开始时间],[结束时间],HOUR);
- 当开始时间是工作日时,结束时间是工作日且开始时间所在日期不等于结束时间所在日期,返回DATEDIFF([开始时间],DATEVALUE([开始时间])+TIME(23,59,59),MINUTE)/60+ 中间区间工作日差24 + DATEDIFF(DATEVALUE([结束时间]),[结束时间],MINUTE)/60;
- 当开始时间是非工作日时,结束时间是工作日时,返回中间区间工作日差24 + DATEDIFF(DATEVALUE([结束时间]),[结束时间],MINUTE)/60;
- 当开始时间是非工作日时,结束时间是非工作日时,返回中间区间工作日差24。
具体公式合并到一起计算如下:
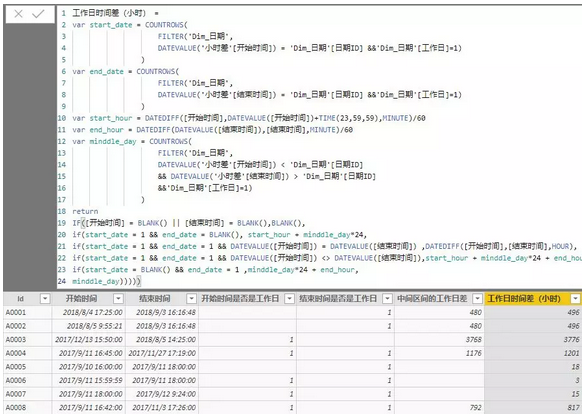
我们对比下结果:
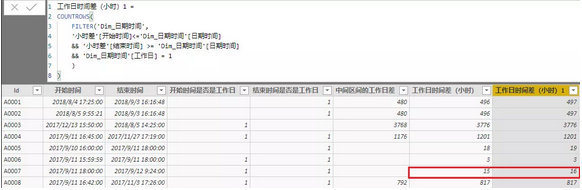
这种方式虽然公式比较长,但是比较灵活,可以根据实际情况进行相应调整。
4 测试性能
关于两种公式的结果,我们测试下性能:
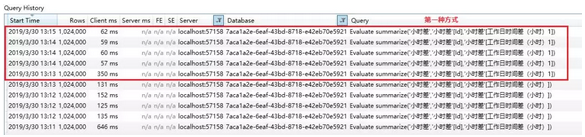
上图可以看到第一种方式性能相对于第二种方式而言是比较好的。
如果我们把计算列改为度量值来写,公式如下:
SUM工作日时间差(小时) =
SUMX('小时差',
var start_date = COUNTROWS(
FILTER('Dim_日期',
DATEVALUE('小时差'[开始时间]) = 'Dim_日期'[日期ID]
&&'Dim_日期'[工作日]=1)
)
var end_date = COUNTROWS(
FILTER('Dim_日期',
DATEVALUE('小时差'[结束时间]) = 'Dim_日期'[日期ID]
&&'Dim_日期'[工作日]=1)
)
var start_hour = DATEDIFF([开始时间],
DATEVALUE([开始时间])+TIME(23,59,59),MINUTE)/60
var end_hour = DATEDIFF(DATEVALUE([结束时间]),
[结束时间],MINUTE)/60
var minddle_day = COUNTROWS(
FILTER('Dim_日期',
DATEVALUE('小时差'[开始时间]) < 'Dim_日期'[日期ID]
&& DATEVALUE('小时差'[结束时间]) > 'Dim_日期'[日期ID]
&&'Dim_日期'[工作日]=1)
)
return
IF([开始时间] = BLANK() ||
[结束时间] = BLANK(),BLANK(),
if(start_date = 1 && end_date = BLANK(),
start_hour + minddle_day*24,
if(start_date = 1 && end_date = 1 &&
DATEVALUE([开始时间]) = DATEVALUE([结束时间]) ,
DATEDIFF([开始时间],[结束时间],HOUR),
if(start_date = 1 && end_date = 1 &&
DATEVALUE([开始时间]) <> DATEVALUE([结束时间]),
start_hour + minddle_day*24 + end_hour,
if(start_date = BLANK() && end_date = 1 ,
minddle_day*24 + end_hour,
minddle_day)))))
)SUM工作日时间差(小时)1 =
SUMX('小时差',
COUNTROWS(
FILTER('Dim_日期时间',
'小时差'[开始时间]
<='Dim_日期时间'[日期时间]
&& '小时差'[结束时间]
>= 'Dim_日期时间'[日期时间]
&& 'Dim_日期时间'[工作日] = 1
)
)
)测试结果性能如下:

对比可以看出,度量值相对于计算列来说,没有计算列性能好。
原因是计算列是消耗内存的,而度量值计算是消耗CPU的。因此应尽量保持DAX引擎计算简单的聚合运算,对于复杂运算,使用公式引擎进行,在数据量小的时候(几十万以内)并不是一个问题,而对于数据量在几百万行以上数据时就会成为关键问题。
需要注意的是,上述例子开始时间是小于结束时间的,如果存在开始时间大于结束时间的情况需要使用IF先进行排除。另外,在SSAS模型中使用DATEDIFF时,如果开始时间大于结束时间,会出现报错信息,可以使用if 排除此情况后再进行计算。
* PowerPivot工坊原创文章,转载请注明出处!
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


