
对 List.TransformMany 的浅显理解
该函数的语法是:
List.TransformMany( list, (each_in_list)=> function_1, (each_in_list, each_in_list_2)=> function_2)
其语意是:先对第一参数list里的每个元素 each_in_list作为参数代入function_1里去运算,得到另一个列list_2,也就是第二参数。这个过程几乎等于List.Transform,所以可以把第二参数看作是内嵌了一个List.Transform。
然后把原始list的每个元素 跟list_2在相同位置上的元素 配对成一对, 每一对(each_in_list, each_in_list_2)作为两个参数代入function_2,运算后返回单元素,按同样的顺序排列成新的(单)列。
看一下下面的例子就会很好理解上面的解释:
= List.TransformMany({1..10}, (each_in_list)=> {each_in_list+10}, (each_in_list, each_in_list_2)=> Text.From(each_in_list) & "-" & Text.From(each_in_list_2))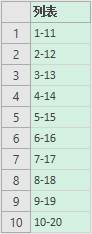
如果list只是单值(标量)元素构成的列,而且经过function_1生成的列list_2依然是单值(标量)元素构成的列,那么list和 list_2对应位置的元素两两组合再进一步运算 似乎没必要经过第三参数function_2,直接在function_1里一步搞定是完全可以的,这种情况下用TransformMany似乎没有意义。
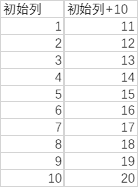
但,如果这两个列的元素不是单值呢?例如在第一次function_1时 在初始列表list的每个位置都生成一个11..15的列,相当于list_2是列中套列:
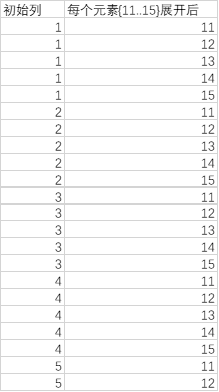
= List.TransformMany({1..10}, (each_in_list)=> {11..15}, (each_in_list, each_in_list_2)=> Text.From(each_in_list) & "-" & Text.From(each_in_list_2))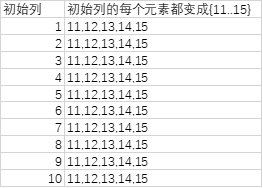
可见,第三参数在运算之前将初始列从1到10每个元素分别与嵌套的列1到5各自组合: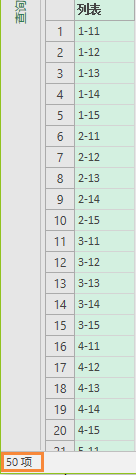
对于第一次function_1,如果按照前面理解的 相当于内嵌了一个List.Transform:
= List.Transform({1..10}, (each_in_list)=> {11..15})
只是List.Transform不会自己将其展开: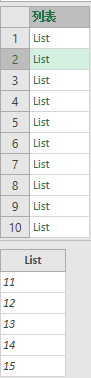
因此,List.TransformMany的第二参数虽然起到了与List.Transform同样的作用,但到了其第三参数与初始列配对时 却不是简单地同位置上一一对应,也就是说,第三参数里的each_in_list_2不是对第二参数返回的list_2的简单复制,而是自动地展开,等于又多执行了一步ExpandList类似的操作。于是初始列list与list_2之间形成了笛卡尔积。
但这个自动添加的ExpandList操作也就仅限一次。要是第二参数返回的是多于两层嵌套的列,到达第三参数的list_2不会一直展开到最内部的单值(标量)元素:
= List.TransformMany({1..10}, (each_in_list)=> {{11..15}, {21..25}}, (each_in_list, each_in_list_2)=> [a= each_in_list, b= each_in_list_2])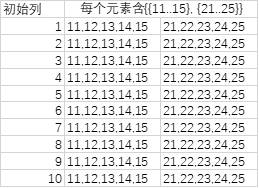
一次展开后: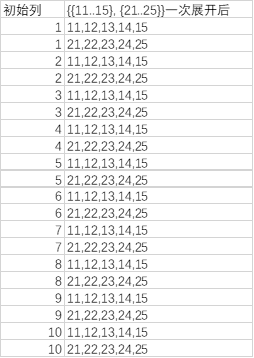

上图例子中,由于list_2的每个元素是{11..15}或{21..25}},即使展开一次,也是{11..15}或者{21..25}这样的列(--复合值,而不是单值11,12,13,...,15,21,22,...,25)与原始列的每个元素去组对。
总而言之,List.TransformMany不仅让我们省写了List.Transform(在第二参数起到相同作用),而且省却了ExpandList。在与初始列“合并 形成笛卡尔积”时,由于M想要两表合并必须要有公共列,即使像笛卡尔积这样纯完全外连接 并不需要公共列的时候 我们也不得不在两表分别添加索引列这样的的额外步骤,这样算来,List.TransformMany至少为我们省却了五个步骤。看来,将TransformMany中的Many理解成一个函数合并了多个步骤不无道理。
前面说了,当初始列(list)以及它的派生列(list_2)都是单值元素时,TransformMany将这两列的相同位置的元素组对在一起进一步运算(第三参数);当有元素是(嵌套)列,且这些嵌套列的元素全部是单值时,TransformMany则将嵌套列全部展开成单列,再与初始列的各个元素交叉组合成一个个对,再做进一步运算。
但当有元素嵌套的列 其元素不能全部是单值(包括又是列 或Table等其它复合结构),就不再展开,仍然像第一种情况那样只是简单把两列中同位置的元素加以组对:
= List.TransformMany({1..10}, (each_in_list)=> {Table.FromList({"a", "b", "c", "d"}, null, {"Letters"})}, (each_in_list, each_in_list_2)=> each_in_list_2)
也就是前面说的:自动展开只限于一次。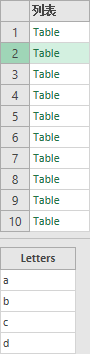
鉴于“自动展开只限于一次”那个特性,如果不管是初始列list还是其派生列list_2,含有某个非单值的元素,且该元素内嵌的 又是全单值元素的列,按理TransformMany会将内嵌列全部展开,但此时我们又不想让它展开,仍然以简单的同位置组对方式,则可以在list_2表达式外面再加个花括号,形成多层嵌套:
= List.TransformMany({1..10}, (each_in_list)=> {{1..5}}, (each_in_list, each_in_list_2)=> each_in_list_2)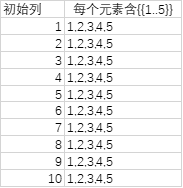
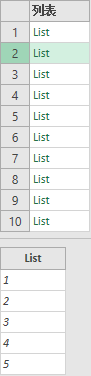
利用这个特性,我们来做个简单例题:怎样利用List.TransformMany生成不规则间隔的递增序列。
先生成表示10个间隔的随机序列:
RL ={1,3,2,5,4,2,1,4,6,3},
显然最后生成的递增序列应该是{1,4,6,11,15,17,18,22,28,31},也就是每个元素都是之前所有元素之和。
当然这个题目完全可以用更直接简单的函数,用TransformMany简直就是杀鸡用牛刀。但正因为简单,可以借此更容易理解TransformMany的机理。
下一步= List.TransformMany({1..10}, (each_in_list)=> {RL}, (each_in_list, each_in_list_2)=> each_in_list_2)
为了不让RL展开,我们在其两边再套个{ }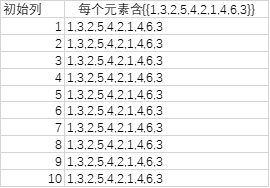
然后根据初始列的每个元素值N 取这随机数列的前N个数:
= List.TransformMany({1..10}, (each_in_list)=> {RL}, (each_in_list, each_in_list_2)=> List.FirstN(each_in_list_2, each_in_list))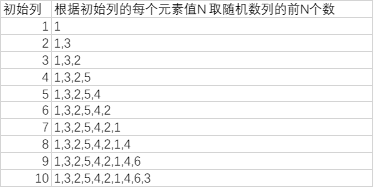
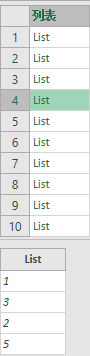
再加个List.Sum就成了:
= List.TransformMany({1..10}, (each_in_list)=> {RL}, (each_in_list, each_in_list_2)=> List.Sum(List.FirstN(each_in_list_2, each_in_list)))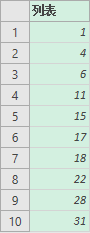
再拿知乎上的一个例子 来试着改用List.TransformMany。
原文https://zhuanlan.zhihu.com/p/50524122 《Power Query 模拟Excel绝对引用》
他的思路是:先用Text.Split把字符串按空格拆分成List;
然后第二步:用List.Transform+Text.Length套路遍历这个List,求出每个项的长度,
第三步:用{1..List.Count(a)},或List.Positions获得该List的顺序列,相当于新添一个索引列;
第四步:按照该索引列 顺序地取得原List的每个项,并从头累加到当前顺序位置: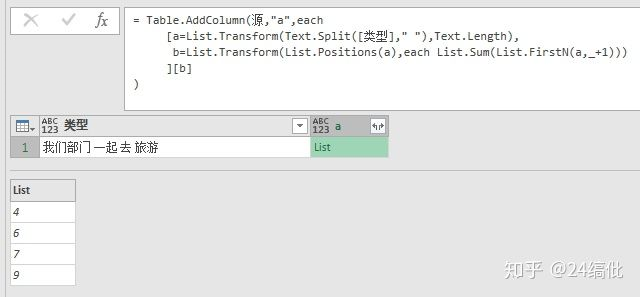
之所以要新添一个反映List各个项的位置的顺序列,是因为List不能直接获取每个项自己在整个列里的位置(顺序号)
现在我们按照同样的思路和解题步骤,但换个M函数。
首先,将文本转成列是必不可少的:
文字列 = List.Transform(List.RemoveItems(Text.Split("我们部门 一起 去 旅游", " "), {""}), (x)=> Text.Length(x)),
其次,为了获得每个项在列中的位置,顺序(索引)列也不能缺席(这里的顺序列变个花样写,意义不变)。
然后,以该顺序列出发,将顺序号与文字列里的每项 按位置一一组对。同样不能将所有文字项与全部顺序号交叉对应。所以要在文字列外面再套个{ }:
= List.TransformMany({1..List.Count(文字列)}, each {文字列}, (x, y)=> ......)
第三参数(省略号部分)就跟前面随机序列累加 是一样的了。
不过这次略微换个写法 换换口味,把FirstN提前到第二参数就截取得到 文字列在当前顺序位置之前的部分:
总结一下List.TransformMany的机理:
先对初始列(第一参数list)进行类似List.Transform那样的变换(第二参数),生成派生列list_2,然后根据派生列list_2的元素是否单值还是复合结构值 进行组对--如果都是单值,则从两列中按照在列中的相同位置各取一个元素 组对成一对;如果list_2有元素是复合结构,则将该元素展开(仅一次)成多个元素,这多个元素与初始列的所有元素两两组合成多个对(笛卡尔积)。最后将这些组对好了的元素对 送入第三参数进行下一个变换。最终仍然形成一个列 作为结果返回。
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)