
Power BI 处理大中小微企业划型(2)大中小微类型计算
第二篇:大中小微类型计算
5. Power Query中数据结构
图表 10 划型计算数据结构图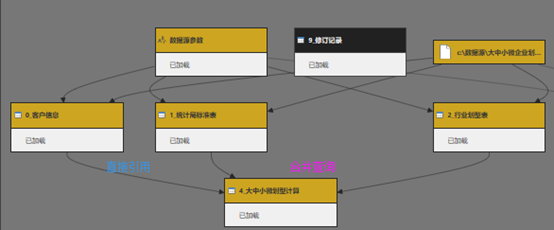
通过Power Query之中的视图=>查询依赖项,我们可以查看在Power Query之中的表间关系,黑白双色的矩形方块所代表的数据表“9_修订记录”不在Power Query之中处理,也与其他数据表没有关系,可以不在本部分讨论。其余黄白双色的矩形方块是Power Query工作对象,并且在加工后加载到展示端Power BI 报表数据表 。
以上数据结构图分成三层,最底部第三层表“4_大中小微划型计算”由第二层的三张表转换计算得出,其中表4直接引用表“0_客户信息”,通过合并查询(NestedJoin)有条件地筛选引用“1_统计局标准表”及“2_行业划型表”之中的部分项目。第一层是写成参数的数据源文件地址名称,被统一引用也方便以后统一修改。
图表 11 0_客户信息
表“0_客户信息”被作为单独的一张表,这样可以在Power BI报表之中方便读者查找未经大中小微企业划型转换的客户信息初始状态。客户信息表结构非常简单,只有客户号,客户国标行业代码,从业人员(X),营业收入(Y),资产总额(Z)一共五列;X,Y,Z三项是判断大中小微类型的维度数据;客户国标行业代码用于定位到大中小微企业划型的统计局行业组,不过房地产相关行业需要到第四级行业代码,其余只需要到第二级;客户号是客户唯一标志。
图表 12 2_行业划型表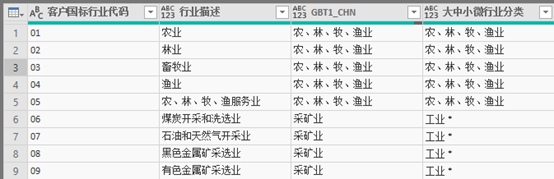
表“2_行业划型表”之中最关键的作用是在两列“客户行业国标代码”与“大中小微行业分类”之间建立对应关系,这样可以从客户信息系统之中的行业代码出发获得统计局大中小微企业行业组。
但是这里需要注意, 笔者对房地产相关行业使用四位数字的第四级行业代码,而非房地产相关行业只使用了两位数字的第二级行业代码。因为房地产相关行业在大中小微企业划型时可能分别属于“房地产开发业”和“其他未列明行业 ”。
图表 13 3_大中小微划型档次赋值表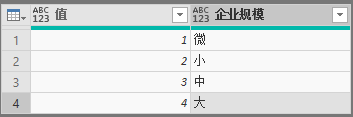
表“3_大中小微划型档次赋值表”在展示时起到两个辅助作用,一是作为切片器,按大中小微切分客户,二是将汉字“微、小、中、大”按1,2,3,4排序。
6. 计算大中小微企业划型
图表 14 大中小微企业划型计算代码与注释
上图是从输入客户数据,引用统计局标准到计算生成大中小微划型的主要过程。双斜杠“//”左边为M函数代码,右边绿色文字为笔者注释。由于这一部分数据处理比上一篇稍为复杂,因此手工修改或者录入的代码更多。以下稍作解释。
a) 直接引用表"0_客户信息",当表名称以阿拉伯数字开头时,前面需添加#。
b) b1,b2是经典的合并查询与展开步骤,合并查询原则与SQL之中的相同,初学者可将其视为Excel中Vlookup函数的升级版。在b1之中根据查找值与比较条件的不同,返回六种结果表(table),需要在b2中展开。
将电脑鼠标单击(双击不可,会完全展开Table)新生成的“行业大类对照表”列(即下方行有许多“Table”字样的一列)空白部分,则可以显示Table之中的具体内容,如下图所示。
图表 15 左外合并查询行业划型表
图表 16 展开合并查询结果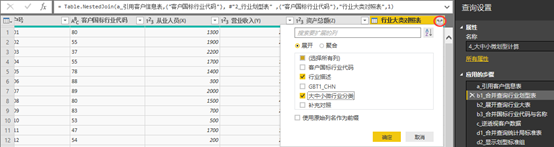
在图15的步骤b1之后,需要展开左外查询所生成的Table。这一步可以手工完成,即单击右上方圆圈之中红圈内的“复杂列符号” ,同时勾选“展开”,“行业描述”与“大中小微行业分类”两列名称,点击“确定”即可。
b3合并国标行业代码与描述,合并前行业代码与行业文字描述分别处于两列,不利于用户理解。合并后显示为“80_居民服务业”这种形式可以方便读者。
c) c步骤逆透视客户数据,将原先处于三列的客户“人数”,“营业收入”,“资产总额”的列标签与数据分别转换为两列。转换前列标签转置为“判断指标”列,转换前数据转置到“客户数据”列。这样可以降低运算次数与代码复杂度。
转换后每一位客户有三行数据,为了减少计算工作,可以在下一步通过与统计局标准表取交集运算排除与企业规模划型无关的维度,只保留有效数据。
图表 17 逆透视客户数据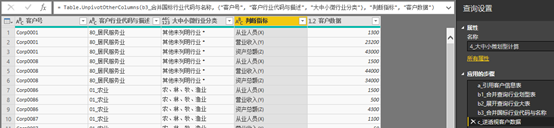
d) d1通过合并查询获取统计局大中小微划型标准,并且通过查询子类交集查询(“JoinKind.Inner”)取客户数据与统计局标准之中的公共部分,以便排除不必要的客户数据和客户数据之中不存在的行业分类,提高运算效率。
图表 18 交集查询统计局分类标准表
为了方便读者肉眼查看不同行业分类各自维度的数量标准,d2与d3合并显示维度名称与大中小微阈值下限。
图表 19 合并标准描述与阈值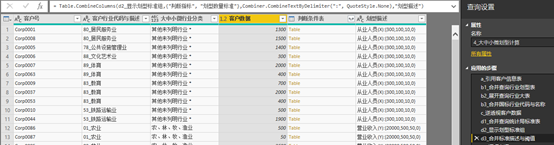
e) e1步骤比较复杂,语句与截图如下Table.AddColumn(d3_合并标准描述与阈值, "逐项考评", (x)=>Table.Last(Table.MinN(x[判断条件表] ,"阈值下限", each [阈值下限]<=x[客户数据])))
图表 20 逐项考评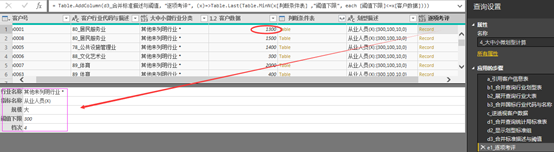
以上代码含义是在上一步“d3_合并标准描述与阈值”的基础上,生成“逐项考评”一列,而这新一列的形式是Record(类似只有两列的转置表,一列是标签,一列是值),内容根据当前行“客户数据”列与“判断条件表”的内容所确定,即取判断条件表之中小于等于当前行客户数据的最大一行内容。在上图数据第一行,“其他未列明行业 *”,“客户数据”为1300,“判断条件表”之中“阈值下限”列小于等于1300的最大行值为300,对应企业规模为大型,档次值为4。
e1步骤之后,需要在e2展开上述Record(类似在b2步骤展开行业分类表),e3转换数据类型是为了后续步骤将客户数据合并展示在一行内,这样做完全是为了提高读者体验。
f) 通过分组运算做汇总提取
e步骤之后,已经获得了每一家客户在每一个规模分类维度的评估,但是由于存在两个评估维度时,单一维度评估结果可能不一致,这时统计局要求按照最低维度评级作为综合规模评级结果,因此下一步还需要通过分组运算提取同一客户的所有评估维度最小值最为客户级企业规模评估结果。同时,为了方便读者更好地理解最终规模划型结果,还需要将各维度结果分别显示。
图表 21 分组汇总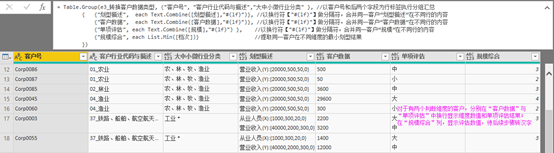
通过以上步骤,数据清洗转换即告完成,下一篇将进入展示与发布环节。
银行业Excel商务智能实践者
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)

