
GROUPBY 和 SUMMARIZE 的区别
本文翻译自Marco Russo& Alberto Ferrari的文章—《Differences between GROUPBY and SUMMARIZE》来源:SQLBI GROUPBY和SUMMARIZE都是按列分组的有用函数。然而,它们在性能和功能上都有所不同。了解细节可以让开发人员为他们的特定场景选择正确的函数。
DAX 提供了丰富的函数集,其中一些函数的功能是重叠的。在众多函数中,有两个函数可以进行分组:SUMMARIZE 和 GROUPBY。但并非只有这两个:SUMMARIZECOLUMNS 和 GROUPCROSSAPPLY 也执行类似的操作。不过,本文讨论的是 SUMMARIZE 和 GROUPBY,因为其他函数还有更多的功能,因此进行比较并不公平。
简而言之:GROUPBY应用于按局部列进行分组,即由DAX函数动态创建的列。SUMMARIZE应用于按模型和查询列进行分组。要注意的是,这两个函数都支持这两种情况:两个函数都可以按模型和局部列进行分组。然而,使用错误的函数会导致性能严重下降。
现在让我们详细说明这些函数是如何工作的。
SUMMARIZE介绍
SUMMARIZE执行两个操作:按本地列分组和添加新的本地列。我们已经在一篇很长很有技术含量的文章中介绍过SUMMARIZE: SUMMARIZE的所有秘密(https://www.sqlbi.com/articles/all-the-secrets-of-summarize/)。
在那篇文章中,我们描述了SUMMARIZE的行为,以及为什么不应该使用它来计算新的本地列。具体来说,SUMMARIZE实现了聚类,这是一种分组技术,尽管非常强大,但可能导致意想不到的结果和较差的性能。
但是,为了进行比较,我们将使用SUMMARIZE来计算新列,以描述其特殊行为。
当与简单示例一起使用时,SUMMARIZE表现良好,将分组操作下推到存储引擎。例如,下面的代码工作得很好,产生预期的存储引擎查询:
EVALUATE
SUMMARIZE (
Sales,
'Product'[Brand],
"Sales Amount", [Sales Amount]
)SUMMARIZE 扫描销售额,按产品[品牌]分组,并按品牌生成销售额。存储引擎查询如下:
WITH
$Expr0 := ( PFCAST ( 'Sales'[Quantity] AS INT ) * PFCAST ( 'Sales'[Net Price] AS INT ) )
SELECT
'Product'[Brand],
SUM ( @$Expr0 )
FROM 'Sales'
LEFT OUTER JOIN 'Product'
ON 'Sales'[ProductKey]='Product'[ProductKey];然而,一旦执行的度量代码变得复杂一些,这种简单的行为就很容易丢失。事实上,正如我们所提到的,SUMMARIZE 是通过一种名为聚类的特殊技术来进行计算的。请看下面的代码:
EVALUATE
SUMMARIZE (
Sales,
'Product'[Brand],
"Sales Amount", [Sales Amount],
"Sales All Brands",
CALCULATE (
[Sales Amount],
REMOVEFILTERS ( Product[Brand] )
)
)由于 CALCULATE 删除了筛选上下文中唯一的筛选项,因此可以合理地认为 "所有品牌销售额 "会产生销售总额。但是,这种推测没有考虑到聚类。由于存在聚类,SUMMARIZE 设置的筛选器会影响扩展销售表的所有列,从而导致这种奇怪的结果。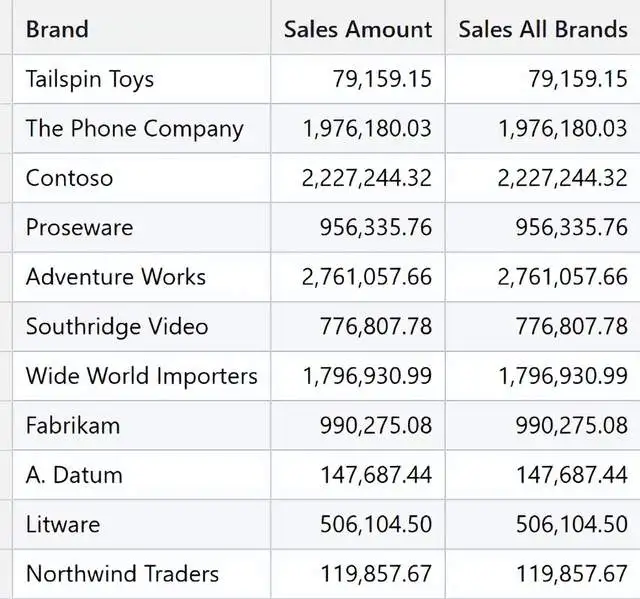
如您所见,"所有品牌销售额 "重复了与 "销售金额 "相同的值。不同的数据分布或存在重复行可能会导致不同的值。此外,由于聚类的原因,一旦要聚合的数据是非三维数据,SUMMARIZE 就需要将整个表具体化。为了计算所有品牌的销售额,这是正在执行的 VertiPaq 查询之一:
WITH
$Expr0 := ( PFCAST ( 'Sales'[Quantity] AS INT ) * PFCAST ( 'Sales'[Net Price] AS INT ) )
SELECT
'Sales'[Order Number],
'Sales'[Line Number],
'Sales'[Order Date],
'Sales'[Delivery Date],
'Sales'[CustomerKey],
'Sales'[StoreKey],
'Sales'[ProductKey],
'Sales'[Quantity],
'Sales'[Unit Price],
'Sales'[Net Price],
'Sales'[Unit Cost],
'Sales'[Currency Code],
'Sales'[Exchange Rate],
SUM ( @$Expr0 )
FROM 'Sales';请注意,RowNumber 并非查询的一部分,因此数据缓存的粒度并不完全是 Sales 的粒度,GROUPBY 也是如此。不过,由于表中的所有列都用作分组列,因此其大小通常非常重要。
同样的查询,使用 SUMMARIZE 和 ADDCOLUMNS 会产生预期结果:
EVALUATE
ADDCOLUMNS (
SUMMARIZE (
Sales,
'Product'[Brand]
),
"Sales Amount", [Sales Amount],
"Sales All Brands",
CALCULATE (
[Sales Amount],
ALL ( Product[Brand] )
)
)这里是结果: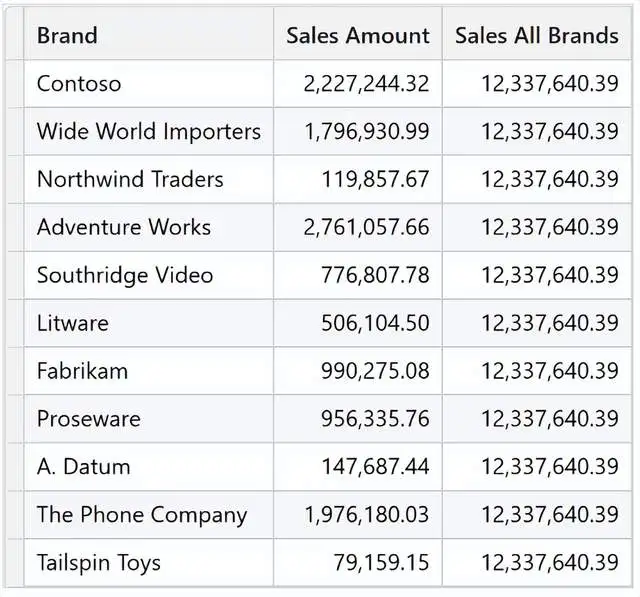
得益于聚类功能,SUMMARIZE 也可以按本地列进行分组。尽管按本地列分组,但下面的查询仍能正常运行:
EVALUATE
SUMMARIZE (
ADDCOLUMNS (
Sales,
"Transaction Size",
IF (
Sales[Quantity] > 3,
"Large",
"Small"
)
),
[Transaction Size],
"Sales Amount", [Sales Amount]
)结果显示了按交易规模分组的销售额。
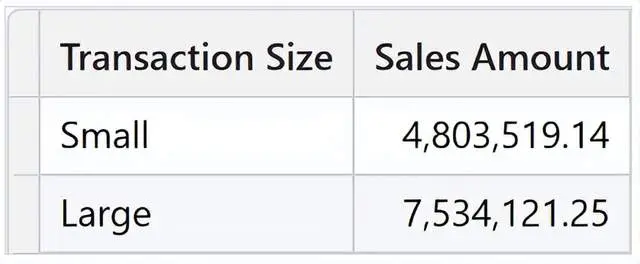
不过,请记住,尽管从语法和语义的角度来看查询是有效的,但其结果却是通过聚类计算出来的。聚类在多种情况下都会产生令人惊讶的结果,而且这种功能带来的问题要多于解决方法。此外,在这种情况下,计算需要将整个销售表具体化。
GROUPBY函数介绍
GROUPBY 按列对表进行分组。列可以是模型列或本地列。不过,它的行为与 SUMMARIZE 非常不同。GROUPBY 甚至不会将计算推送到存储引擎:整个计算都是在将表具体化后在公式引擎中进行的。GROUPBY 还可以在结果中添加新列。不过,由于 GROUPBY 的行为方式,新列需要使用 CURRENTGROUP 特殊函数作为被分组表中列的简单聚合来计算。
举例来说,让我们看看下面的代码:
EVALUATE
GROUPBY (
Sales,
'Product'[Brand],
"Sales Amount",
SUMX (
CURRENTGROUP (),
Sales[Quantity] * Sales[Net Price]
)
)GROUPBY 扫描销售表并按产品[品牌]分组。为了进行分组,DAX 在数据缓存中将 Sales 所需的列具体化,然后由公式引擎进行处理。实际上,查询执行的就是这段代码:
SELECT
'Product'[Brand],
'Sales'[RowNumber],
'Sales'[Quantity],
'Sales'[Net Price]
FROM 'Sales'
LEFT OUTER JOIN 'Product'
ON 'Sales'[ProductKey]='Product'[ProductKey];在销售中,DAX 会检索销售[数量]、销售[净价]和产品[品牌]。Sales[RowNumber] 的存在保证了检索到所有行,否则,VertiPaq 本身将执行分组操作。
结果是一个行数与销售额相同的表格,因此可能非常大。公式引擎会扫描该表,根据产品[品牌]将其分成若干组,然后计算每个组的销售额[数量]乘以销售额[净价]的总和。
GROUPBY 有一个很大的局限性,那就是在迭代 CURRENTGROUP 时使用的表达式不能涉及上下文转换。这一限制使得我们无法使用现有的度量值作为迭代的一部分。您可能已经注意到,我们不得不重写示例中销售金额的代码。
尽管 GROUPBY 看起来很慢,但它是唯一一个可以对无行列的表执行分组和计算的 DAX 函数。例如,下面的查询按本地表的一列对表进行分组,而 GROUPBY 是唯一能执行该操作的函数:
EVALUATE
VAR TableToGroup =
SELECTCOLUMNS (
{
( "A", 1 ),
( "A", 2 ),
( "B", 3 ),
( "B", 4 )
},
"Group", [Value1],
"Value", [Value2]
)
RETURN
GROUPBY (
TableToGroup,
[Group],
"Result",
SUMX (
CURRENTGROUP (),
[Value]
)
)GROUPBY 是一个合适的函数,适用于使用其他 DAX 函数生成一个小表格,然后需要按其中一列执行分组,逐行进行简单的聚合。
选择正确的函数
正如您所看到的,当需要按模型中的列分组时,SUMMARIZE 可以很好地发挥作用。尽管它也可以按本地列分组,但它使用了聚类,其结果大多出人意料。GROUPBY 不使用聚类。不过,它也有一个很大的局限性:它总是将需要分组的表具体化。因此,GROUPBY 并不是按模型列分组的最佳选择,而 ADDCOLUMNS/SUMMARIZE 则能产生更高效的代码。
不过,当需要按本地列对小型临时表进行分组时,GROUPBY 是最好的函数,因为它可以在不依赖聚类的情况下完成工作。
明智的 DAX 开发人员会选择合适的函数,通常会将 SUMMARIZE、ADDCOLUMNS 和 GROUPBY 混合使用,以获得最佳性能和正确结果。让我们通过一个例子来详细说明这一点。之前,我们向您展示了这段代码:
EVALUATE
SUMMARIZE (
ADDCOLUMNS (
Sales,
"Transaction Size",
IF (
Sales[Quantity] > 3,
"Large",
"Small"
)
),
[Transaction Size],
"Sales Amount", [Sales Amount]
)该查询使用 SUMMARIZE,因此进行了聚类。它执行两个 VertiPaq 查询。第一个查询基本上是具体化 Sales:
SELECT
'Sales'[Order Number],
'Sales'[Line Number],
'Sales'[Order Date],
'Sales'[Delivery Date],
'Sales'[CustomerKey],
'Sales'[StoreKey],
'Sales'[ProductKey],
'Sales'[Quantity],
'Sales'[Unit Price],
'Sales'[Net Price],
'Sales'[Unit Cost],
'Sales'[Currency Code],
'Sales'[Exchange Rate]
FROM 'Sales';第二个存储引擎查询使用第一个查询的结果,对销售数据进行大规模筛选:
WITH
$Expr0 := ( PFCAST ( 'Sales'[Quantity] AS INT ) * PFCAST ( 'Sales'[Net Price] AS INT ) )
SELECT
'Sales'[Order Number],
'Sales'[Line Number],
'Sales'[Order Date],
'Sales'[Delivery Date],
'Sales'[CustomerKey],
'Sales'[StoreKey],
'Sales'[ProductKey],
'Sales'[Quantity],
'Sales'[Unit Price],
'Sales'[Net Price],
'Sales'[Unit Cost],
'Sales'[Currency Code],
'Sales'[Exchange Rate],
SUM ( @$Expr0 )
FROM 'Sales'
WHERE
( 'Sales'[Exchange Rate], 'Sales'[Currency Code], 'Sales'[Unit Cost], 'Sales'[Net Price], 'Sales'[Unit Price], 'Sales'[Quantity],
'Sales'[ProductKey], 'Sales'[StoreKey], 'Sales'[CustomerKey], 'Sales'[Delivery Date], 'Sales'[Order Date],
'Sales'[Line Number], 'Sales'[Order Number] )
IN { ( 1.000000, 'USD', 1227800, 2536500, 2670000, 1, 1507, 999999, 1573592, 43818.000000, 43816.000000, 1, 363800 ) ,
( 0.914500, 'EUR', 1677300, 2928100, 3290000, 2, 241, 999999, 587554, 43739.000000, 43736.000000, 2, 355804 ) ,
( 0.902900, 'EUR', 676000, 1470000, 1470000, 1, 668, 340, 884269, 43693.000000, 43693.000000, 1, 351503 ) ,
( 1.335200, 'CAD', 322500, 701300, 701300, 3, 1707, 999999, 278457, 43473.000000, 43472.000000, 1, 329404 ) ,
( 1.000000, 'USD', 1480780, 3220000, 3220000, 3, 1410, 999999, 1582937, 43095.000000, 43090.000000, 0, 291214 ) ,
( 1.297600, 'CAD', 3214400, 6990000, 6990000, 1, 405, 80, 326829, 43836.000000, 43836.000000, 2, 365800 ) ,
( 1.000000, 'USD', 300800, 513300, 590000, 2, 501, 999999, 1540547, 43818.000000, 43813.000000, 1, 363503 ) ,
( 1.000000, 'USD', 186500, 364950, 405500, 6, 79, 450, 1665181, 43239.000000, 43239.000000, 0, 306110 ) ,
( 1.310000, 'CAD', 1520800, 4590000, 4590000, 4, 569, 100, 384389, 43407.000000, 43407.000000, 0, 322905 ) ,
( 0.875900, 'EUR', 1379600, 3000000, 3000000, 1, 1449, 999999, 590077, 43410.000000, 43406.000000, 0, 322800 )
..[13,915 total tuples, not all displayed]};尽管这两个查询在我们的示例模型上运行速度非常快,但在有数千万行数据的实际示例中可能会非常繁重和缓慢。
使用 GROUPBY 表示的相同查询可能会更高效:
EVALUATE
GROUPBY (
ADDCOLUMNS (
Sales,
"Transaction Size",
IF (
Sales[Quantity] > 3,
"Large",
"Small"
)
),
[Transaction Size],
"Sales Amount",
SUMX (
CURRENTGROUP (),
Sales[Quantity] * Sales[Net Price]
)
)尽管我们不能使用基本衡量标准 "销售金额",但具体化级别却变小了。正在执行的唯一 VertiPaq 查询如下:
SELECT
'Sales'[RowNumber],
'Sales'[Quantity],
'Sales'[Net Price]
FROM 'Sales';但是,这种数据缓存的粒度与 Sales 相同,对于大型模型来说,这将是一个严重的问题。
要想获得更好的性能,就必须将这两个功能结合起来,并改变我们的视角。我们首先按销售额[数量]分组,使用 ADDCOLUMNS 和 SUMMARIZE 生成一个很小的表。该表仅包含 10 行。然后,我们添加 "交易量 "列,最后,我们使用GROUPBY将表格中的10行数据分组到两个“交易规模”集群中:
EVALUATE
GROUPBY (
ADDCOLUMNS (
SUMMARIZE (
Sales,
Sales[Quantity]
),
"@Sales", [Sales Amount],
"Transaction Size",
IF (
Sales[Quantity] > 3,
"Large",
"Small"
)
),
[Transaction Size],
"Sales Amount",
SUMX (
CURRENTGROUP (),
[@Sales]
)
)该 DAX 查询只执行两个存储引擎查询。第一个查询按数量对销售额进行分组:
WITH
$Expr0 := ( PFCAST ( 'Sales'[Quantity] AS INT ) * PFCAST ( 'Sales'[Net Price] AS INT ) )
SELECT
'Sales'[Quantity],
SUM ( @$Expr0 )
FROM 'Sales';第二个 VertiPaq 查询只是检索销售[数量]的不同值:
SELECT
'Sales'[Quantity]
FROM 'Sales';大部分计算都已下放到存储引擎中;具体化程度可以忽略不计,即使在大型数据库中,最后这个 DAX 查询也会非常快。
结论
对于任何认真学习 DAX 的人来说,了解函数的细节、实现方式和预期用法都是一项重要技能。在本文中,我们介绍了 GROUPBY 和 SUMMARIZE 之间的区别。然而,DAX 还有许多隐藏的细节值得了解。
使用错误的函数可能会产生意想不到的结果或查询效率低下。对 DAX 了解得越多,你的代码就会变得越好。
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


