
优化 DAX 中的文本搜索
本文翻译自Marco Russo& Alberto Ferrari的文章—《Optimizing text search in DAX》来源:SQLBI 本文描述了如何优化DAX中的文本搜索操作。这种技术可以提高在Power BI报告中使用筛选窗格中的包含条件或Smart Filter Pro自定义可视化的筛选模式时的性能。
在Power BI中导入表格时,所有包含在文本列中的字符串都存储在一个字典中,这样可以提高压缩率,并在列值精确匹配的筛选条件下提供优异的查询性能。然而,当字典含有大量值时,对文本列应用复杂筛选条件的报告可能存在性能问题:根据其他许多变量的情况,仅有几千个唯一值的列就已经成为瓶颈,而当列中出现数十万个唯一字符串时,这绝对会成为一个麻烦。
在2022年10月,Power BI进行了内部优化,通过创建内部索引来改善这些搜索的性能。在这篇文章中,我们将探讨如何评估优化是否生效以及如何衡量性能改进情况。在通常情况下,一切都是有代价的:创建索引是有成本的,你会在第一次查询触及该列时看到这个成本。我们还将看到如何检测这个事件以及存在的这种优化的局限性。
在Power BI中进行文本搜索的情景
使用常规切片器,用户通常选择一个或多个值,这意味着筛选器寻找与所选项完全匹配的项:整个列的值必须与所选项之一完全相同。如果用户想要搜索包含特定子字符串或匹配特定搜索模式的任何列值,则可以在筛选器面板中使用包含高级筛选器选项。
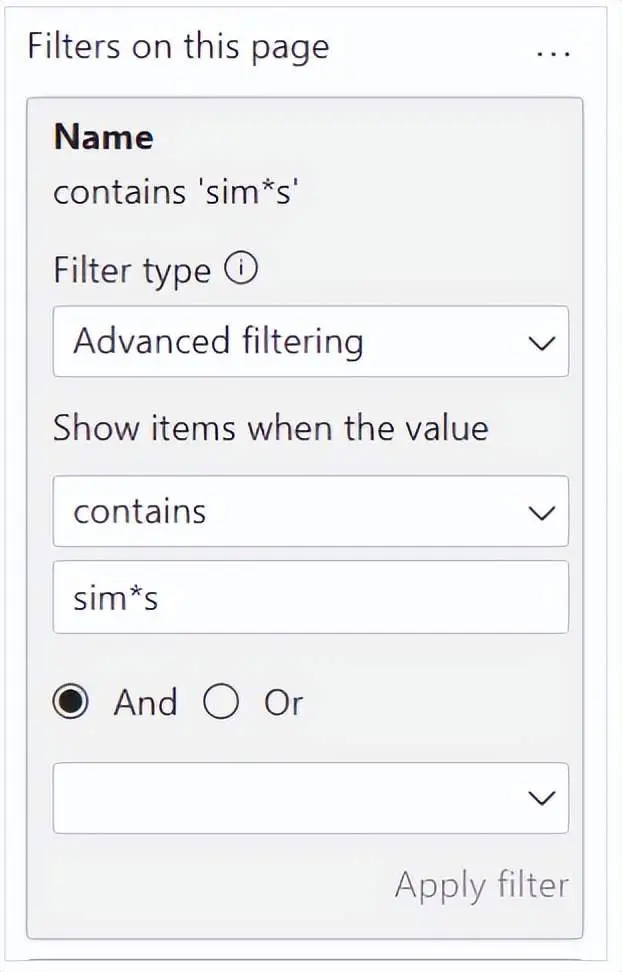
使用模式“sim * s”的规则可以匹配诸如Sims、Simmons、Simpson等客户姓名,但是Simen Aase也会被搜索返回。这种搜索模式在使用OKVIZ的Smart Filter Pro自定义视觉报表中的筛选模式也是可用的。

在Power BI报告中使用用户界面筛选器时,底层查询中包含SEARCH或CONTAINSSTRING来实现DAX中的筛选条件。这些函数不区分大小写,但是区分重音符号。因此,Šime Šaric不会包含在筛选结果中。我们提到这些函数对重音符号敏感的特性,因为这是优化时需要考虑的一个重要因素。
检测瓶颈
我们来考虑下面的报告,在这个报告中我们使用了筛选器面板或Smart Filter Pro来应用了"sim*s"的搜索模式。
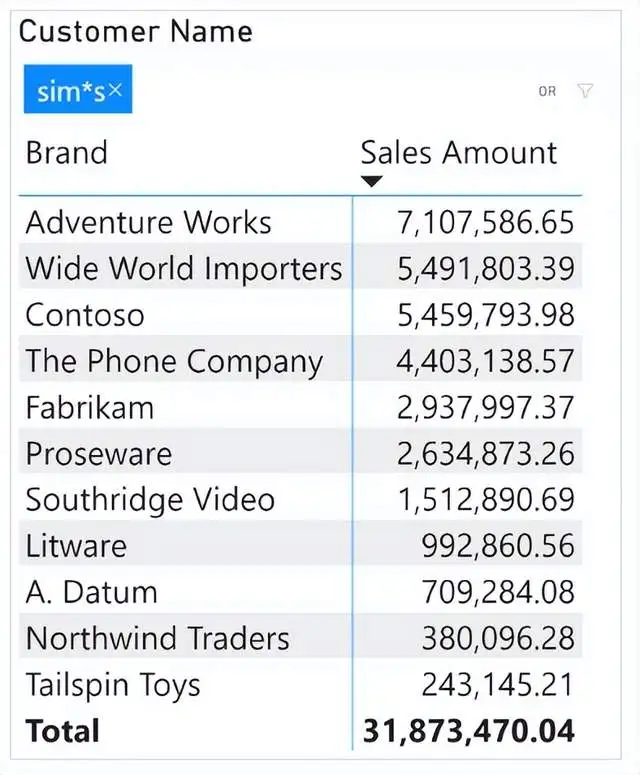
测试基于一个包含1,000万个订单和超过1.4百万个客户的Contoso版本。通过性能分析仪,发现这个简单的报告执行DAX查询需要将近2秒钟。
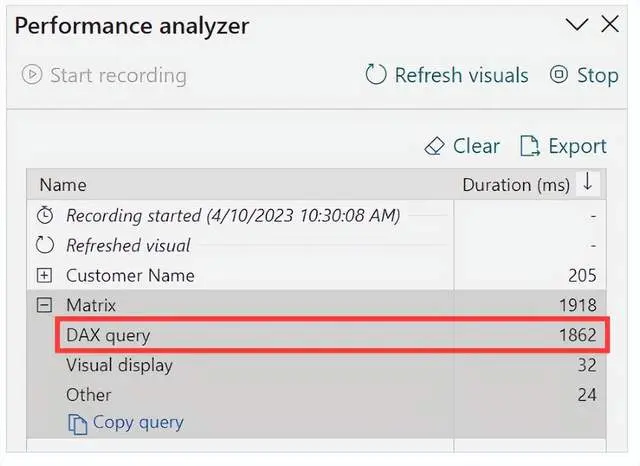
瓶颈的原因是CallbackDataID在VertiPaq引擎执行的批处理操作中用于创建对Customer[Name]进行筛选。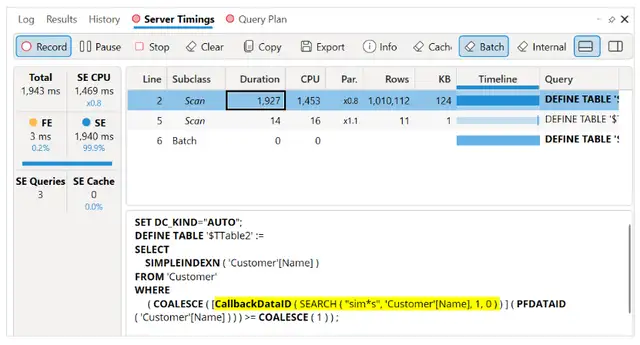
公式引擎对Name中的每个唯一值执行SEARCH函数。尽管为此操作生成的位图索引使得批处理中的第二次扫描非常快速(仅需16毫秒的CPU时间),但对于超过一百万个唯一名称执行SEARCH函数会导致性能瓶颈。此外,CallbackDataID并不会将结果存储在存储引擎缓存中,每次执行包含相同筛选条件的DAX查询时都需要进行相同的昂贵操作。如果用户在页面上应用了筛选器面板,并且该页面包含多个可视化图表,则筛选器的成本必须乘以显示的可视化图表数量。
由于可下载的示例文件版本较小,只包含10,000个订单和略多于5,000个客户,因此使用该示例文件的执行计划似乎更加高效,因为它不使用CallbackDataID。
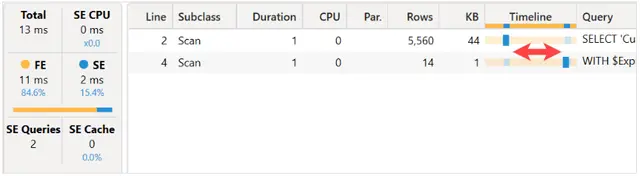
有两个存储引擎查询,它们之间由公式引擎执行计算的时间间隔。第一个xmSQL查询检索所有客户名称的列表:

第二个xmSQL查询应用符合筛选条件的客户名称列表,在两个存储引擎查询之间由公式引擎进行评估:
尽管存储引擎查询会被缓存,但是在这种查询计划的替代方法中,公式引擎评估筛选器的成本始终存在。引擎可以根据Customer[Name]中唯一名称的数量选择其中一种方法,但在两种情况下,您都会看到公式引擎中的成本,存储引擎缓存无法减少这种成本。然而,为了在这种情况下强制使用CallbackDataID,您可以使用以下两个查询之一,这两个查询都不会将Customer[Name]值的列表实际生成给公式引擎:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
SEARCH ( "sim*s", 'Customer'[Name], 1, 0 ) >= 1
)
)
}
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name], "sim*s" )
)
)
}
在CallbackDataID的参数中包含了FILTER条件中使用的DAX表达式: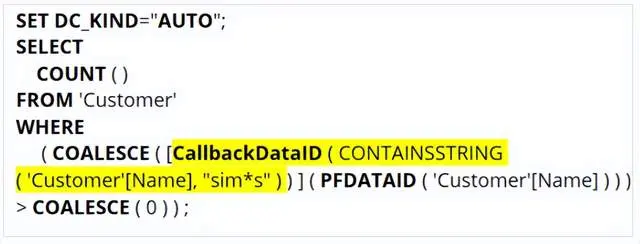
如果您使用的是2022年10月之前的Power BI Desktop版本或2022年之前的任何版本的本地Analysis Services,您将在任何文本列上看到相同的执行计划。如果您使用更新版本的Power BI Desktop、Power BI Service或Azure Analysis Services,则可以看到在我们尝试在供样本模型中的不同列(例如Customer[Country])上使用相同的筛选类型时会出现不同的行为。例如,请考虑以下查询:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Country], "state" )
)
)
}
这次,存储引擎查询筛选的是包含“state”一词的唯一国家--美国:
然而,在旧版本的Power BI中,您将看到以下xmSQL查询:
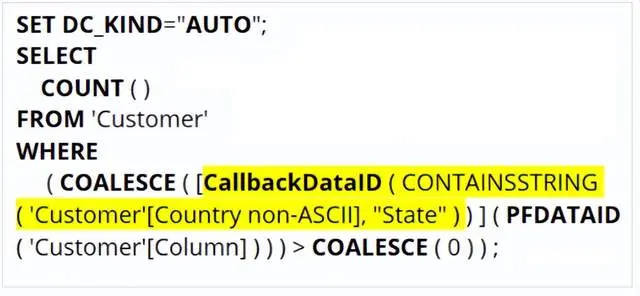
通过对不可优化的Customer[Country non-ASCII]列进行筛选,您可以在示例文件中(公众号后台回复“文本搜索”)看到具有CallbackDataID的相同查询计划。这是因为该列包含非ASCII字符,稍后我们将会看到。
因为对SEARCH和CONTAINSSTRING函数应用了优化,Customer[Country]列具有更高效的查询计划。而对Customer[Name]列没有进行此优化。在解决性能问题之前,我们应该了解为什么出现了这种差异。
优化的工作原理
第一次查询涉及到对列使用SEARCH或CONTAINSSTRING函数时,引擎会尝试创建一个索引来提高这些函数的性能。所创建的索引是不区分大小写的,并且仅在列中包含严格的ASCII字符时才能创建。如果列的任何值中存在非ASCII字符,索引的生成将会停止。这就是为什么我们没有看到任何应用于Customer[Name]列的索引:正如我们之前提到的,该列包含像Šime Šaric这样的值,其中包含了ASCII字符集中不含的带有变音符号的字母。
一旦索引可用,所有使用搜索和包含字符串函数的执行时间几乎可以忽略不计。然而,首次对数据集执行的查询可能会比较慢,因为创建索引需要消耗CPU资源。在索引有效期内,后续查询将变得更快。稍后我们将描述索引被删除的限制和条件。索引已经应用于Customer[Country]列,但由于列中拥有非常少的唯一行,无法测量性能差异。为了分析索引创建的成本并衡量其效益,我们通过去除Customer[Name]列中的变音符号来对该列进行优化。
优化非ASCII列
我们可以通过去除Customer[Name]中的变音符号来简化搜索并利用索引。由于我们不希望丢失正确的姓名,我们创建了第二列,其中包含相同姓名的版本,将变音符号替换为相应的字母。
Customer[Name ASCII]列的填充使用以下M表达式:
= Table.AddColumn (
dbo_Customer,
"Name ASCII", each Text.FromBinary ( Text.ToBinary ( [Name], 28597 ) )
)
我们重复执行一个使用CONTAINSSTRING的查询,但这次是在Customer[Name ASCII]而不是在Customer[Name]上进行:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "sim*s" )
)
)
}
xmSQL查询没有任何CallbackDataID,但是有一个包含搜索表达式的Search函数,因为我们在搜索字符串中使用了通配符:
在xmSQL查询中出现Search函数是评估服务是否支持索引的一个很好的测试,因为否则你永远不会在xmSQL代码中看到Search函数。
我们可以通过使用不带通配符的单词来重复搜索:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "marco" )
)
)
}
这次,xmSQL查询的结果列表是通过公式引擎计算满足条件的值,而不需要通过额外的存储引擎查询来检索Customer[Name ASCII]中的值:
当你看到xmSQL查询中的值列表时,在执行存储引擎请求之前,已经应用了SEARCH / CONTAINSSTRING条件。物理查询计划证实了这一点,而在SEARCH节点之前没有其他存储引擎请求的缺失证明了使用索引来执行该函数。

无论使用哪个函数(SEARCH 或 CONTAINSSTRING),物理查询计划应始终显示一个 SEARCH 节点。实际上,CONTAINSSTRING 只是使用 SEARCH 的快捷方式。但是,我们发现 Azure Analysis Services 可能不会在查询计划中显示该节点;因此,根据引擎版本的不同,查询计划可能不会包含 SEARCH 节点,即使实际上在执行中使用了该函数。
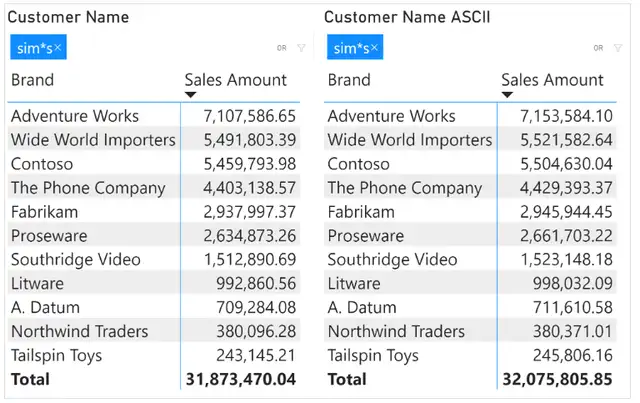
由于应用于 ASCII 字符的筛选器可能返回不同的结果,报表的结果也会不同。例如,我们的示例中使用 Customer[Name ASCII] 列的筛选器会包括更多的客户,因此总金额也比应用于 Customer[Name] 的原始筛选器要大。虽然这可能是期望的行为,但一旦将列转换为仅含 ASCII 字符,请注意这种副作用。
限制
对于 SEARCH 和 CONTAINSSTRING 函数,Power BI 和 Azure Analysis Services 中提供了索引功能。截至 2022 版本,SQL Server Analysis Services 上尚不可用此优化功能,且我们不知道微软是否会在未来的 Analysis Services 本地更新中包含此优化功能。
索引仅适用于使用严格 ASCII 字符的文本列。如果某个值中包含任何非 ANSI 字符,则不会创建索引。
索引是不区分大小写的。
FIND 和 CONTAINSSTRINGEXACT 函数不使用索引。
索引可以用于 "*" 通配符字符,但不能用于 "?" 通配符字符。
索引构建时间必须少于25秒。一旦超过25秒,构建操作超时,查询将在没有索引的情况下执行。创建索引所需的时间由第一个使用SEARCH或CONTAINSSTRING的查询支付。
每当有明确的请求清空缓存,或数据库从内存中移出时,索引就会被删除。以下是导致索引被删除的更详细条件列表:
当 Analysis Services 服务或 Power BI Desktop 被重新启动时。
数据集/数据库被刷新。
Power BI Service中的数据集被从内存中清除。
可能是当 Analysis Services 内存受到压力时。
与安全角色相关的问题没有限制。由于索引是在存储引擎级别上运行的,因此它可以在不同的用户和会话之间共享。事实上,它只是用于加快存储引擎查询的执行速度,这些查询总是包含安全筛选条件。
在大列上测量性能
创建索引会对具有大基数(cardinality)的列产生显著影响:下面的测试使用了本文开头提到的最大版本的 Contoso 数据集,其中包含 1000 万个订单和 140 万个客户。
在运行第一个查询之前,我们确保清空缓存。
我们运行的第一个查询统计了在 Name 列中包含单词“marco”的客户数量:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name], "marco" )
)
)
}
服务器计时窗格提供了我们用作以下分析基准的信息。
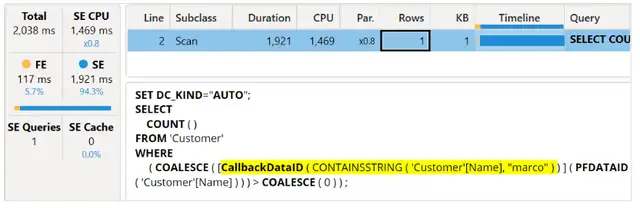
执行时间约为2秒,几乎全部用于存储引擎,而原因是由于CallbackDataID(回调数据ID)。无论我们重复执行多少次,无论是否启用了运行时清除功能,我们始终得到类似的执行时间:当我们禁用此功能时,性能是可比较的。
我们现在运行一个类似的查询,通过筛选 Customer[Name ASCII] 来测试索引性能:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "marco" )
)
)
}
我们运行具有活动的 Clear on Run 的查询,并查看服务器计时窗格。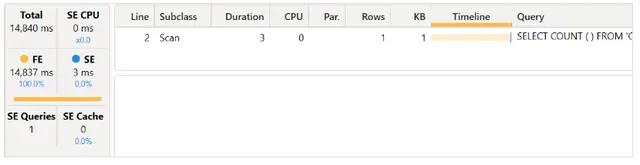
令人惊讶的是,这个查询比基线慢了6-7倍!然而,大部分由公式引擎花费的时间是在创建索引上。我们没有选择xmSQL查询,是因为我们想确保存储引擎查询的位置是可见的:它位于执行的最后,并且查询计划在存储引擎请求之前的行5上显示没有任何活动。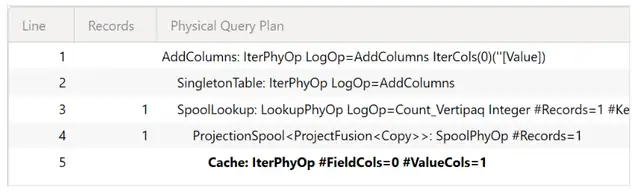
由于CONTAINSSTRING函数不包含任何通配符,所以下面存储引擎请求的查询计划中没有搜索节点。然而,我们知道索引被用来生成要在Customer[Name ASCII]字段中进行筛选的值列表。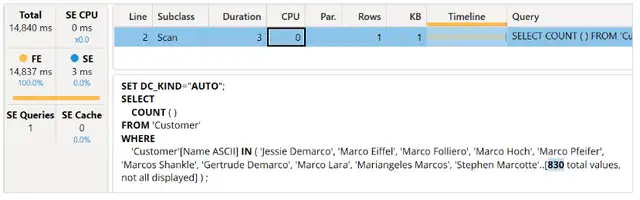
正如我们所见,第一次执行的速度比我们的基准慢了6-7倍。如果我们重复执行会发生什么?首先,我们禁用 Clear on Run(在运行时清除索引),以确保我们不再清除索引。
此时,我们重复执行DAX查询。
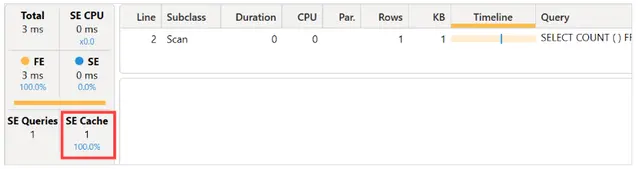
现在执行时间为三毫秒,但结果已经存在于存储引擎的缓存中。因为没有涉及到CallbackDataID,我们只是获取了前一次执行相同xmSQL查询的结果。为了测试索引是否真正有帮助,我们改变了筛选条件,使用“mark”代替“marco”:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "mark" )
)
)
}
我们在保持禁用Clear on Run的情况下运行查询。我们得到了仅为五毫秒的执行时间,而这次xmSQL查询是由存储引擎执行而不是从缓存中检索出来的。
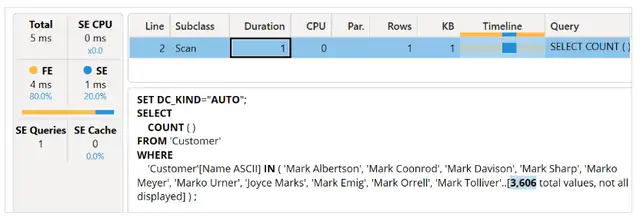
对完整单词进行筛选可以获得出色的性能。那么,如果我们在搜索字符串中使用通配符会发生什么呢?我们将分析文章开头使用的相同搜索模式的性能:
EVALUATE
{
COUNTROWS (
FILTER (
Customer,
CONTAINSSTRING ( 'Customer'[Name ASCII], "sim*s" )
)
)
}
查询结果仍然比基准线快,但不如没有通配符的搜索条件快。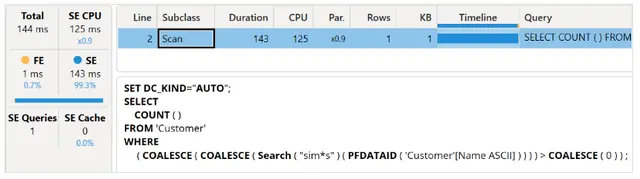
索引改善了带有和不带有通配符的SEARCH和CONTAINSSTRING的性能,尽管索引只支持“*”通配符。如果筛选器包含“?”通配符,引擎将回退执行计划到CallbackDataID而不使用索引。然而,在刷新后第一个查询模型的用户必须等待最多15秒才能看到结果,但是索引对所有后续的用户查询都可用。通常情况下,这是值得的努力,但是您应该记住,每次清除缓存时都要重新构建索引以测试性能。如果你在基准测试中看到索引构建操作,你必须评估并从你度量的典型执行时间中减去那个时间。在用户的最坏条件下,假设存储引擎缓存为空,但索引始终可用。
因此,既然我们有了索引,我们可以通过将筛选器应用于Customer[Name ASCII]而不是Customer[Name]来查看原始报告的执行计划。我们已经看到由于我们筛选了变音符号,结果有所不同。现在是时候来看一下服务器计时了。

查询计划类似,但在批处理的第一个扫描中创建位图索引所需的时间从原来的1,927毫秒减少到了173毫秒。索引在优化我们的报告方面确实非常有效。
结论
SEARCH和CONTAINSSTRING函数可以从在这些函数第一次目标列时自动创建的索引中受益。为了确保索引被使用,请检查列是否仅包含ASCII字符,并且搜索参数不使用“?”通配符,因为目前不支持非ASCII字符和“?”通配符。
索引构建的成本作为公式引擎活动的一部分在相应的存储引擎请求之前可见。了解这种行为对于在优化过程中解释服务器计时面板上的信息非常重要。假设频繁发生数据集逐出或频繁执行刷新操作;在这种情况下,索引构建操作可能会打扰最终用户,因为它可能比相应的CallbackDataID操作更昂贵。假定索引在大部分时间内是高效的,即它准备好随时使用。
在某些特定情况下,您可能希望通过在刷新操作后运行特定查询来预先创建索引。一个更好的解决方案是在Tabular模型中设置一个标志,在数据集加载到内存时立即请求索引构建(如果感兴趣,请投票支持该想法),而不是等待对该列的第一个查询。另一个常见的需求是支持非ASCII字符的索引。
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


