
RANKX 函数之计算列
在实际做报表时,有时会遇到需要对某些指标(例如销售额等)进行排名,所以今天跟大家讨论一下可以实现排名的DAX函数-RANKX函数。
首先看下RANKX函数的参数:
RANKX(<table>, <expression>[, <value>[, <order>[, <ties>]]])
其中
table:表,或者能返回表的DAX表达式。
expression: 任何返回单一标量值的DAX 表达式,此表达式将针对 table 的每一行进行计算,以生成所有用于排名的可能值。
value:(可选)任何返回要找到其排名的单个标量值的 DAX 表达式。
order:(可选)指定如何对 value 排名的值,从低到高或从高到低。
ties:(可选)一个枚举,它定义如何在具有等同值时确定排名。
函数返回值:针对为表中每一行计算的表达式,返回值列表中当前表达式的排名。
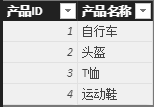
下图为我们此次讨论用到的数据,为方便起见,我们将数据做了简化,分别为’销售记录’表和’产品’表。现在,我们需要对各类产品的销售额进行排名。
要实现排名,我们可以在表中创建计算列,也可以写度量值。此次我们先来看下相对简单的计算列。因为要对各产品的销售额进行排名,所以我们先写出[销售额]的公式:
销售额 = sum('销售记录'[销售])
接着在’产品’表中新建列,命名为[排名1],然后使用RANKX函数写出[排名1]列的公式:
排名1 = rankx('产品',[销售额])
结果如下: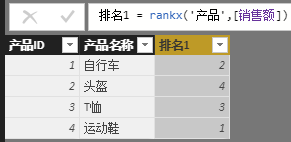
但是有人可能会无意发现这个问题,若排名的公式不完全按上文那样写,不预先写出度量值[销售额],而是将其直接嵌套入RANKX函数中,如下,结果怎么不对了呢?
排名2 = rankx('产品',SUM('销售记录'[销售]))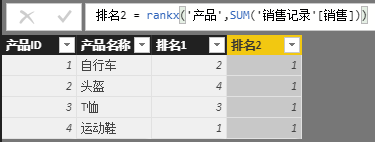
这是因为,RANKX是一个迭代函数,它对’产品'表中的每一行都计算了该函数第二个参数处的表达式,然后再根据计算结果进行排名。也就是说,如果公式写成:
排名1 = rankx('产品',[销售额]),那就是对’产品'表的每行进行了[销售额]计算,如果公式写成 排名2 = rankx('产品',SUM('销售记录'[销售])), 那就是对’产品'表的每行进行了SUM('销售记录'[销售]计算。这时肯定会有人问,[销售额]和SUM('销售记录'[销售]不是等价的吗?[销售额]就是用SUM('销售记录'[销售])计算出来的啊~ 那我们就将这两个的结果在列中都呈现出来,看它们的结果是否相同,如下图: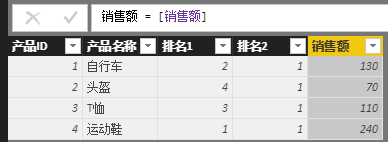
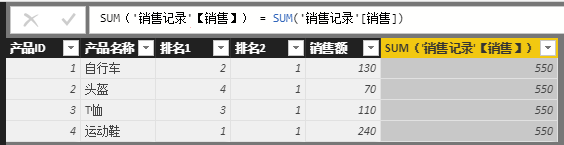
如此看来,在计算列中,[销售额]和SUM('销售记录'[销售])得出的结果并不相同,一个结果是每行得到不同的值,而另一个结果是每行的值都相同,都是销售总额,所以导致以下两个公式的出来的排名不相同,
排名1 = rankx('产品',[销售额])
排名2 = rankx('产品',SUM('销售记录'[销售]))
并且,显而易见,第二个公式得出的结果是错的,那么这是为什么呢?这就涉及到上下文的概念了,因为聚合函数,例如SUM,MIN和MAX只能感知筛选上下文,而忽略行上下文,所以得到每行相同的值,而[销售额]中存在隐性的CALCULATE函数引发了上下文转换,将现有的行上下文转化成了等价的筛选上下文。所以,如果我们还想在排名公式中使用SUM函数的话,需要在其外面加一个CALCULATE函数。如下:
排名3 = RANKX('产品',CALCULATE(SUM('销售记录'[销售])))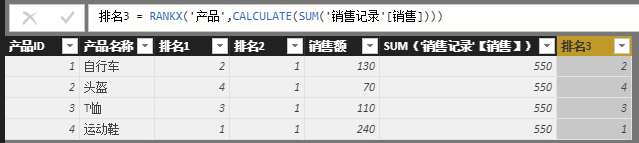
- PowerPivot工坊原创文章,转载请注明出处!
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。点击左下角“阅读原文”可直达云课堂。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯。欢迎小伙伴儿们转发分享~
阅读原文
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)

