
前 N 名的占有量
数据源:单表模型没有关系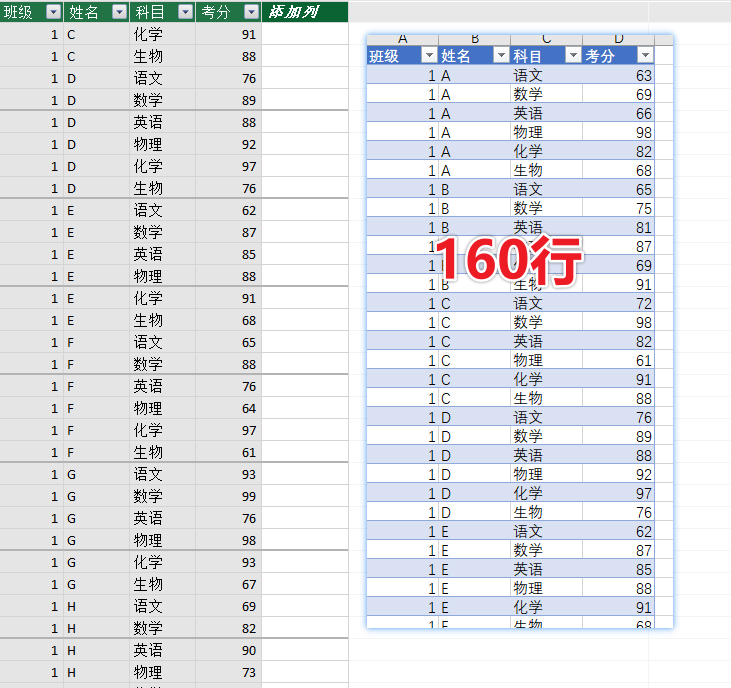
这是我模拟的数据,为什么要模拟数据?因为对于初学者而言,简单的案例可以事半功倍.
我想看看本次考试前10名的各班占有量,说白了就是统计每班有几个,
作为一个班主任,经常会做这些事情,现在的教学制度老师的等级直接影响到老师的待遇,所以班主任常常要知己知彼,才能百战百胜,
好了让我们开始表演吧
新建一个透视表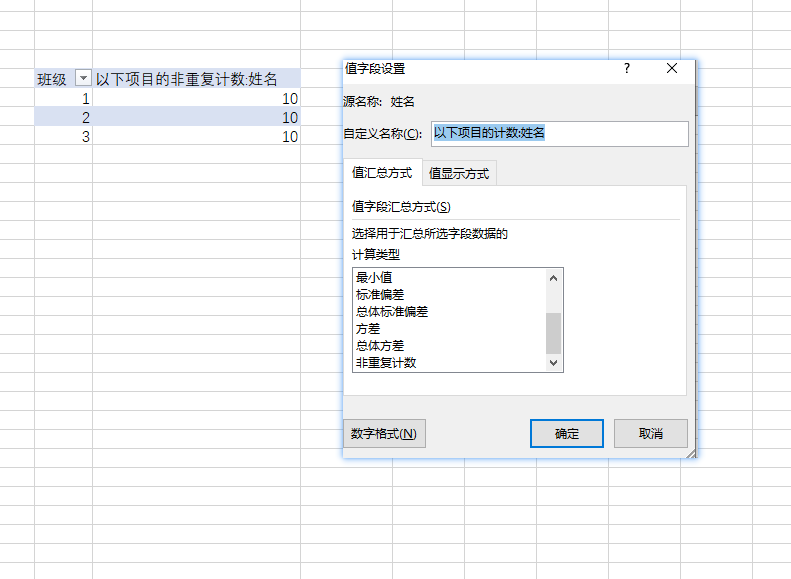
我们发现每班有10个学生
我的核心就是统计同学数,这是我们的最终要
如何才能让统计的有价值呢,就是前10名的占有量
这个度量值和上面的效果是等效的,我们把这个度量值称为基础度量值
php
姓名的非重复计数:=DISTINCTCOUNT('考分表1'[姓名])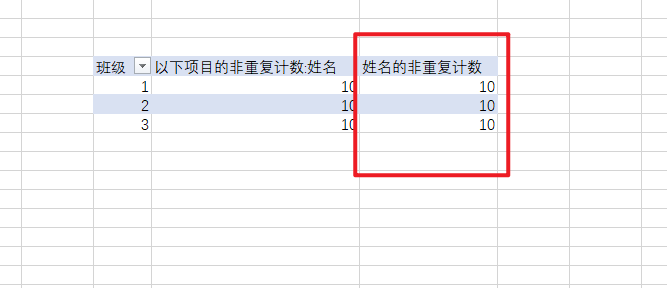
上面这个度量值的计算环境是班级筛选后计算了每个班级的同学数
现在我们想改变一下计算环境
php
前10名:=TOPN(10,VALUES('考分表1'[姓名]),CALCULATE(SUM('考分表1'[考分])))让我们看看这个表是个什么样子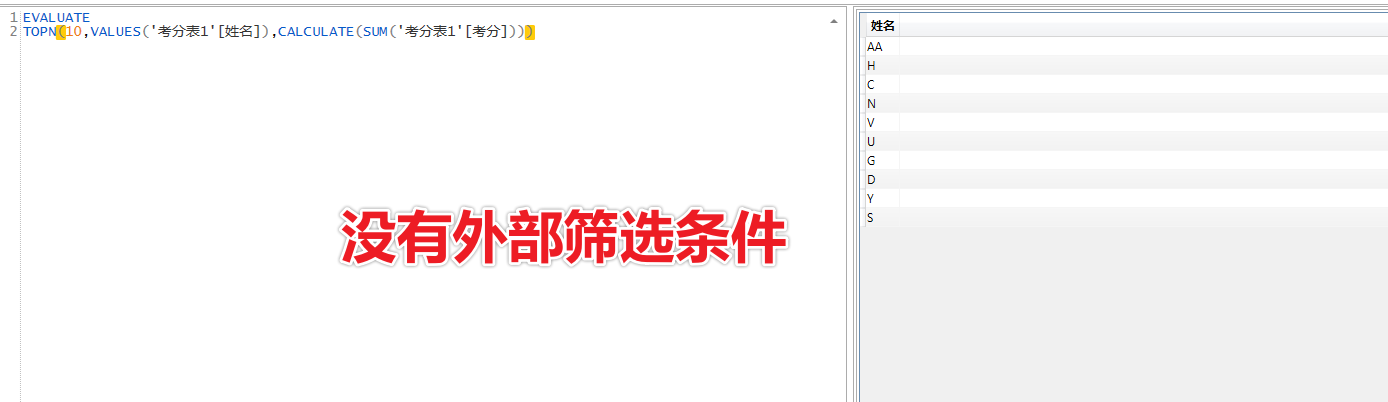
这个表正是我们需要的,按考分求出前10名的同时姓名.
让我们将这个表放进calculate的内部作为筛选表
看看效果
php
前10名姓名:=CALCULATE(DISTINCTCOUNT('考分表1'[姓名]),TOPN(10,VALUES('考分表1'[姓名]),CALCULATE(SUM('考分表1'[考分]))))看看透视表的结果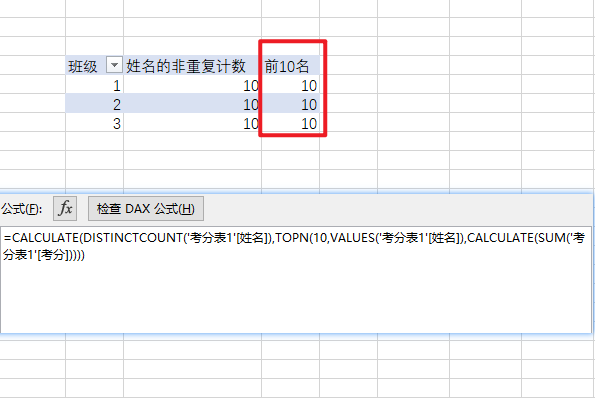
真是不可思议呀,这个结果不是我们想要的
为什么会这样呢,我们仔细分析calculate的第二参数,发现它受到了外部行标签班级的筛选,topn完全变了,
我们要忽略班级的筛选
php
前10名:=CALCULATE(DISTINCTCOUNT('考分表1'[姓名]),CALCULATETABLE(TOPN(10,VALUES('考分表1'[姓名]),CALCULATE(SUM('考分表1'[考分]))),ALL('考分表1'[班级])))
再看看透视表的效果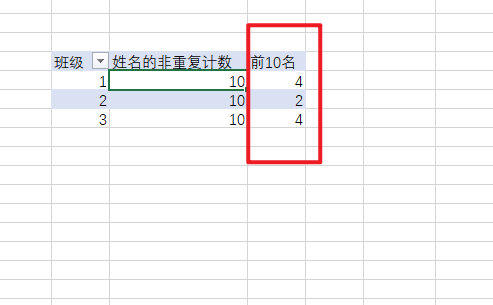
补充一下文洲老师写的
php
前10名:=CALCULATE(DISTINCTCOUNT('考分表1'[姓名]),TOPN(10,ALL('考分表1'[姓名]),CALCULATE(SUM('考分表1'[考分]),ALL('考分表1'[班级]))))百分比应该如下求
php
前10名:=CALCULATE(
DIVIDE(DISTINCTCOUNT('考分表1'[姓名]),CALCULATE(DISTINCTCOUNT('考分表1'[姓名]),ALL('考分表1'[班级]))),
CALCULATETABLE(
TOPN(10,VALUES('考分表1'[姓名]),CALCULATE(SUM('考分表1'[考分]))),
ALL('考分表1'[班级])
)
)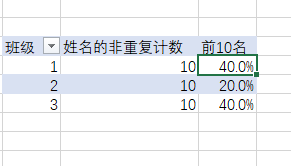
这个结果才是我们想要的
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)

