
RANKX 函数
第一参数,排序对象,一般情况用all(表[列])取全部值,当然也不尽然,
第二参数,排序依据
第三参数,排序值
第四参数,对第二参数升降序
第五参数,对第二参数要不要去重复
第二参数迭代第一参数,生成了一个表,一个参考系
第三参数迭代第二参数,取出第三参数在第二参数中的位置
接下来我会案例演示:
数据源: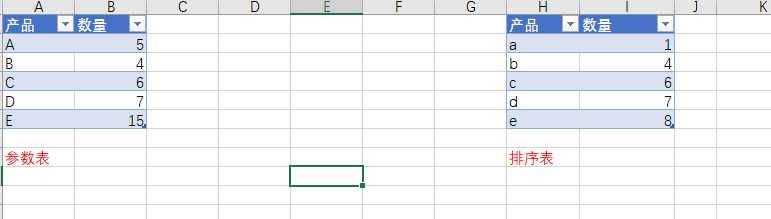
关系视图: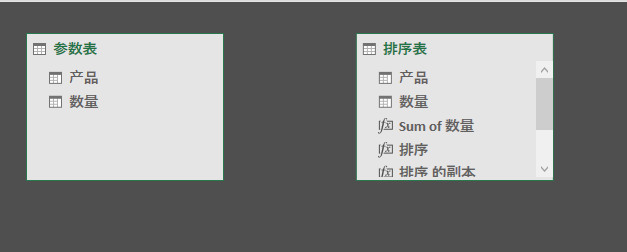
让我在排序表写下第一个度量值:
php
Sum of 数量:=SUM([数量])然后写下第二个度量值:
php
排序:=RANKX(ALL('排序表'[产品]),[Sum of 数量],[Sum of 数量])看看透视表的效果:
在这里我们先不处理总计行,因为这不是我们的话题
让我写下第三个度量值:
php
排序 的副本:=RANKX(ALL('排序表'[产品]),[Sum of 数量],5)把这个度量值放入到透视表看看效果:
我是想告诉你,第三参数和第一参数毛关系也没有,很多人以为第三参数和第一参数关系是必然的,其实不是的
让我写下第四个度量值:
php
排序 的副本 2:=RANKX('参数表','参数表'[数量],[Sum of 数量])放入透视表: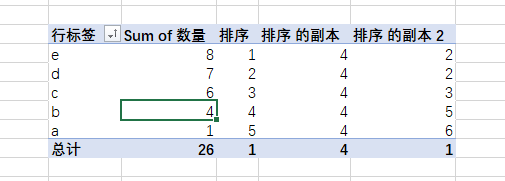
我想告诉你,其实第一参数和第二参数是必须的,排序不一定是第一参数的排序,不要以为第一参数就是排序的对象
其实没有多少毛关系
让我们写下第五个度量值:(上一次复制错了,重新改正了)
php
排序 的副本 3:=RANKX(ALL('排序表'[产品]),[Sum of 数量],SUM('排序表'[数量]))放入透视表看看: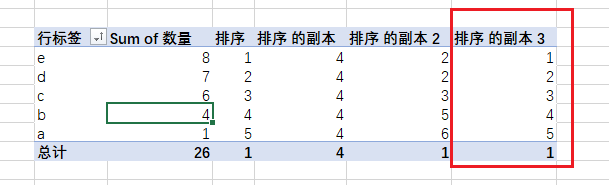
这个我是想告诉你:
其实第三参数和第一参数,第二参数没有直接关系,第三参数是外部筛选取值,没有calculate照样工作,
我的这篇文章主要是颠覆你的认识,因为很多人会形成固化思维,如有阐述不对请读者指点!!!
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


