
Power BI 中星型模式的重要性
本文翻译自国际Power BI大师Alberto Ferrari 的文章——《The importance of star schemas in Power BI》。在Power BI中创建星型模式是提高性能的好办法,更重要的是,能够保证结果准确!本文对星型模式为何可以解决报告中的某些问题进行了解释。
数据建模新手面临的一个常见的问题是,使用只有一个表的完全扁平的数据模型更好,还是花时间构建合适的星型模式更好(您可以在Introduction to Data Modeling
链接:https://www.sqlbi.com/p/introduction-to-data-modeling-for-power-bi-video-course/ 中找到星型模式的描述)。正如Koen Verbeeck所说,一个经验丰富的建模者的座右铭应该是“用星型模式解决一切!”
下面我们看一个简单的案例来了解使用扁平化的报表返回不准确的数字,而使用星型模式可以将其转换为可靠的分析系统。
要分析的数据模型很简单,一家公司拥有四家Beauty Salon:两家 hair salons和两家nail salons。要分析顾客光临salons的相关信息,比如他们的Gender 和 Job。您需要构建一个简单的报告来分析到店的次数,每个salons按Gender 和 Job进行筛选。在同一报告中,您希望将当前选择的salons的到店次数与所属的组的其他salons进行比较。换句话说,要回答的问题是:与所有同类salons的平均水平相比,某个salons的顾客的Gender 和 Job分布如何?
数据源是一个单独的表,已经包含了所有相关信息。
![]()
因为该表不包含任何键,并且所有信息都已经存在,所以看起来不需要在其上构建数据模型-一个表就足够了。实际上,一份包含访问次数及其百分比的报告可以得出正确的结果。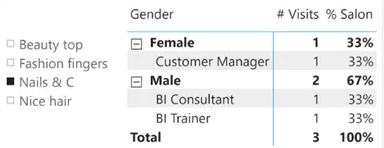
在这份报告中,我们使用了以下度量:
# Visits := COUNTROWS ( 'Visits' )
% Salon :=
VAR NumOfVisits = [# Visits]
VAR NumOfAllVisitsSameSalon =
CALCULATE (
[#Visits],
REMOVEFILTERS( 'Visits' ),
VALUES( 'Visits'[Beauty Salon] )
)
VAR Result = DIVIDE ( NumOfVisits, NumOfAllVisitsSameSalon)
RETURN Result%Salon是不考虑其他任何筛选条件,通过将到店次数除以该salons的总到店数来实现的目标。
事实证明,第二步更具挑战性。我们想要展示处于同一组( hair和nails)的所有salons中顾客的Gender和Job的分布。第一步是计算当前salons所属的组共有多少到店数。下面的方法并不能计算出正确的数字,尽管它看起来是完全正确的:
#Group Visits :=
CALCULATE(
[# Visits],
REMOVEFILTERS ( 'Visits'[BeautySalon] ),
VALUES ( 'Visits'[Group] )
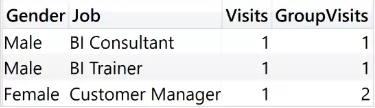
)请看下面的结果:
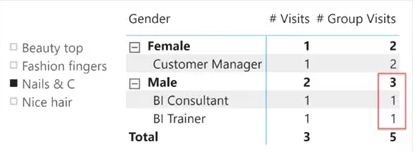
这份报告显然是错误的。你可以很容易地检查出总数的错误。根据之前的数据源表的显示,在nails中已经有三位男性,但是明细却不相等。简单来说,这个例子是错误的,原因有二。
第一个原因是“auto-exist”行为。(关于自动存在可以参考这篇文章:https://www.sqlbi.com/articles/understanding-dax-auto-exist/)
第二个原因是模型在没有访问表的情况下,无法在当前的数据模型中找到group和salon之间的关系。当SUMMARIZECOLUMNS在一个名为Nails & C for Beauty Salon和Male forGender的筛选上下文中扫描表格时,它将这两个筛选器合并在一起,防止它找到未被包括在内的Job(WebDevelopment)。
避免“auto-exist”的影响很简单:您需要为Gender 和 Job创建单独的维度,以便一个维度上的过滤条件不会影响其他维度。这个简单的操作可以防止“auto-exist”。
因此,解决这个问题的第一步(这是必要的,但不是最后一步)是创建两个维度:一个是Gender维度,另一个是Job维度。新模型看起来更像一个星型模式。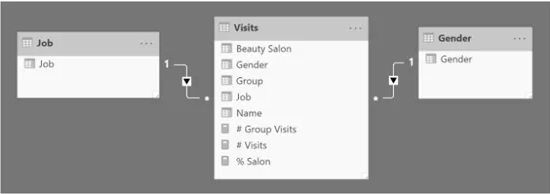
然后,您需要通过维度表中的列而不是事实表中的列来更新矩阵。但是,即使我们删除了“auto-exist”的问题,这仍然不足以解决问题。事实上,这些数字看起来还是一样——仍然是错误的。
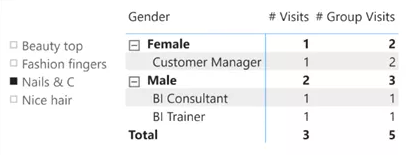
为了确保不再存在自动存在的问题,您可以通过性能分析器捕获由Power BI执行的查询,对其进行一些清理,如下所示:
DEFINE
VAR __DS0FilterTable =
TREATAS( { "Nails & C" }, 'Visits'[Beauty Salon] )
VAR __DM3FilterTable =
TREATAS( { "Female", "Male" }, 'Gender'[Gender] )
EVALUATE
SUMMARIZECOLUMNS (
'Gender'[Gender],
'Job'[Job],
__DS0FilterTable,
__DM3FilterTable,
"Visits", 'Visits'[#Visits],
"GroupVisits",'Visits'[# Group Visits]
)因为SUMMARIZECOLUMNS是通过两个单独的表进行分组和筛选的,所以自动存在不会起作用。通过运行此查询的两个稍微修改过的版本,您可以轻松地再次检查这一点。我们首先引进了IGNORE到度量值中,以避免删除空白行;然后,我们首先按维度(Gender、Job)执行相同的查询分组,然后按事实表中的列执行。
这是对维度进行分组的查询:
DEFINE
VAR __DS0FilterTable =
TREATAS ( { "Nails & C" }, 'Visits'[Beauty Salon] )
VAR __DM3FilterTable =
TREATAS ( { "Female", "Male" }, 'Gender'[Gender] )
EVALUATE
SUMMARIZECOLUMNS (
'Gender'[Gender],
'Job'[Job],
__DS0FilterTable,
__DM3FilterTable,
"Visits", IGNORE ( 'Visits'[# Visits] ),
"GroupVisits", IGNORE ( 'Visits'[# Group Visits] )
)结果表明,尽管许多行都显示空白,但返回了Gender和Job的所有组合。

这是对事实表中的列进行分组的查询:
DEFINE
VAR __DS0FilterTable =
TREATAS( { "Nails & C" }, 'Visits'[Beauty Salon] )
VAR __DM3FilterTable =
TREATAS( { "Female", "Male" }, 'Gender'[Gender] )
EVALUATE
SUMMARIZECOLUMNS (
'Visits'[Gender],
'Visits'[Job],
__DS0FilterTable,
__DM3FilterTable,
"Visits", IGNORE ('Visits'[# Visits] ),
"GroupVisits", IGNORE( 'Visits'[# Group Visits] )
)如您所见,表中不包括没有访问Nails&C的Gender 和 Job。
因此,第一步是成功的,auto-exist在这里不再起作用。我们已经知道这一步是必要的,但这仍然不足以解决问题。尽管问题的本质非常接近于auto-exist,但要发现这个问题还是有点难。
我们报告中缺少的行是(male,Web Development)。因为我们有两个维度,即Job和Gender,所以我们知道SUMMARIZECOLUMNS实际上为该组合计算值。尽管如此,它还是空白。我们需要进一步调查以确定原因。
对于组合Gender=Male, Job=Web开发,DAX计算这个度量:
#Group Visits :=
CALCULATE(
[# Visits],
REMOVEFILTERS ( 'Visits'[BeautySalon] ),
VALUES ( 'Visits'[Group] )
)因此,我们可以扩展完整的表达式,以更好地了解发生了什么:
EVALUATE
{
CALCULATE (
CALCULATE(
[#Visits],
REMOVEFILTERS( 'Visits'[Beauty Salon] ),
VALUES( 'Visits'[Group] )
),
'Visits'[BeautySalon] = "Nails & C",
'Gender'[Gender]= "Male",
'Job'[Job]= "Web development"
)
}内部CALCULATE在外部CALCULATE定义的筛选上下文中计算VALUES函数。由于没有(Male,WebDevelopment)访问Nails&C.,因此VALUES('Visits'[Group])返回一个空表,而不是salons所属的组的表。因此,该度量将返回空白。
虽然这种行为非常接近于auto-exist,但这一次完全是我们的锅。与DAX无关。当筛选器上下文中的筛选器集产生一个空结果时,无法查找当前salons属于哪个组,因为在visit表中没有行告诉我们这个信息。换句话说,我们依靠事实表来告诉我们salons属于哪个组。在没有访问表的情况下,无法获得这些信息。
了解问题比找到解决方案困难得多。为避免此问题,我们需要定义一个包含salons及其各自所属组别的数据结构。该表不能是可以被报表过滤的访问表;它必须是一个专门的维度。因此,解决方案的最后一步是使用名为Beauty Salon的表为Beauty Salon建立第三个维度。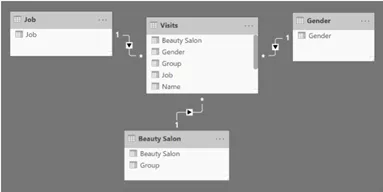
维度就位之后,我们将切片器与Beauty Salon表的BeautySalon列一起使用,而不是Visits表中的BeautySalon列,然后对DAX代码进行较小的更正:
# Group Visits :=
CALCULATE(
[# Visits],
REMOVEFILTERS ( 'BeautySalon'[Beauty Salon] ),
VALUES ( 'Beauty Salon'[Group])
)如您所见,REMOVEFILTERS和VALUES函数在维度表上运行,而不是对事实表中的列进行处理。该度量的总体逻辑保持不变。有了这项新度量值,报告现在将显示正确的结果。
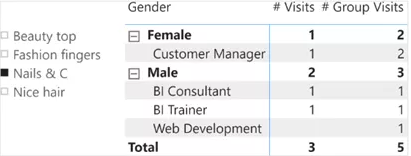
从DAX的角度来看,在一个有10行数据的模型上发现这个问题是很有挑战性的,但是我们知道在结果中会出现什么数字,这使得问题变得更简单了。不用说,要在一个有数百万行数据的模型上找到这个问题简直是天方夜谈。这就是为什么专家建模师总是遵循以下规则:
- 始终使用星型模式。
- 隐藏事实表中的所有列。仅在事实表中显示度量。
- 仅通过维度公开可见的属性。
- 使用一眼就能掌控和理解的少量数据对公式进行测试。
这些都是黄金法则。专家建模人员有时会推翻这些规则,但是他们这样做是基于对所处理内容的深入透彻的理解,缺乏经验的建模者常常选择避开规则。如果您想感受一下进入一个完全未经探索和危险的复杂迷宫的刺激,那么这样做是令人兴奋的。转念一想,如果您想为您的客户部署一个合理的模型,那么遵守这些简单的规则是朝着正确方向迈出的非常好的一步。
原文链接:
https://www.sqlbi.com/articles/the-importance-of-star-schemas-in-power-bi/
-
PowerPivot工坊原创文章,转载请注明出处!
如果您想深入学习微软Power BI,欢迎登录网易云课堂试听学习我们的“从Excel到Power BI数据分析可视化”系列课程。或者关注我们的公众号(PowerPivot工坊)后猛戳”在线学习”。
长按下方二维码关注“Power Pivot工坊”获取更多微软Power BI、PowerPivot相关文章、资讯,欢迎小伙伴儿们转发分享~
Power Pivot工坊
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)

